Command Palette
Search for a command to run...
见速与见缓:学习视频中的时间流转
见速与见缓:学习视频中的时间流转
Yen-Siang Wu Rundong Luo Jingsen Zhu Tao Tu Ali Farhadi Matthew Wallingford Yu-Chiang Frank Wang Steve Marschner Wei-Chiu Ma
摘要
我们如何判断一段视频是被加速了还是减速了?又该如何生成不同速度的视频呢?尽管视频一直是现代计算机视觉研究的核心,但人们对于感知和控制时间流逝的关注却寥寥无几。在本文中,我们将时间视为一种可学习的视觉概念,并开发了用于推理和操控视频时间流向的模型。首先,我们利用视频中自然存在的模态线索(multimodal cues)和时间结构,通过自监督学习的方式,实现了对速度变化检测以及播放速度估计的学习。随后,我们证明了这些习得的时间推理模型能够帮助我们从嘈杂的自然场景(in-the-wild)来源中,构建出迄今为止规模最大的慢动作视频数据集。这类慢动作素材通常由高速摄像机拍摄,相比标准视频,它们包含了丰富得多的时间细节。利用这些数据,我们进一步开发了具备时间控制能力的模型,包括:速度调节视频生成(speed-conditioned video generation),即产生指定播放速度的运动;以及时间超分辨率(temporal super-resolution),即将低帧率(low-FPS)、模糊的视频转化为具有细粒度时间细节的高帧率序列。我们的研究结果强调了时间在视频学习中是一个可操控、可感知的维度,这为时间可控视频生成、时间取证检测(temporal forensics detection),以及开发能够理解事件随时间演变过程的更丰富的世界模型(world-models)开辟了新的路径。
一句话总结
通过将时间视为一种可学习的视觉概念,研究人员提出了一种自监督框架,用于检测播放速度并构建大规模慢动作数据集,从而通过速度调节的视频生成和用于增强低帧率序列的时空超分辨率实现先进的时间控制。
核心贡献
- 本文引入了一种自监督方法,通过利用视觉运动与音频音调变化之间的自然耦合,来检测时间速度变化并估计播放速度。该方法能够训练出一个在推理阶段仅依靠视频输入即可运行的视觉速度变化检测器。
- 本研究提出了 SloMo-44K 数据集,这是迄今为止最大的慢动作视频数据集,是利用学习到的时间推理模型从嘈杂的自然场景资源中筛选而成的。该数据集提供了训练模型理解和控制时间流逝所需的丰富时间细节。
- 研究开发了用于细粒度时间控制的模型,包括能够产生特定播放速度运动的速度调节视频生成模型,以及能将低 FPS 视频转换为高 FPS 序列的时空超分辨率模型。这些模型在视频理解和生成任务中均达到了最先进的性能。
引言
理解时间的流逝对于创建逼真的视频模型和进行时间取证至关重要。虽然现代计算机视觉模型在空间理解方面表现出色,但由于主要在具有标准固定帧率的视频上进行训练,它们往往缺乏时间推理能力。这种局限性导致现有的视觉语言模型和生成模型在预测播放速度或以特定时间节奏生成内容时面临困难。作者通过将时间视为一种可学习的视觉概念来应对这些挑战。利用多模态线索和自监督学习,开发出了能够检测速度变化并估计播放速度的模型。这种方法使得构建迄今为止最大的慢动作视频数据集成为可能,并利用该数据集实现了先进的时间控制,包括速度调节的视频生成和高保真时空超分辨率。
数据集

作者推出了 SloMo-44K,这是一个专为慢动作视频理解和生成设计的大规模数据集。数据集详情如下:
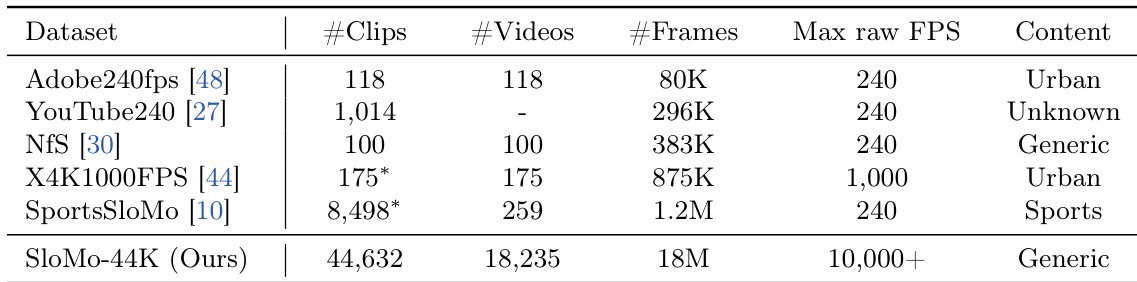
- 组成与来源: 该数据集包含 44,632 个慢动作视频片段,总计 1,800 万帧。原始视频材料通过与高帧率和慢动作相关的查询,从 YouTube、Vimeo 和 Flickr 获取。
- 数据过滤与质量控制: 作者实施了一个多阶段流水线以确保高质量。使用 TransNetv2 进行镜头分割,并使用 OCR 模型移除包含过多文本的片段。为了保持内容完整性,使用 Qwen2.5-VL 过滤掉 CGI 和屏幕录制内容,同时应用视频质量评估 (VQA) 指标来剔除低质量样本。
- 慢动作识别: 为了防止数据集被标准速度内容主导,作者使用了两阶段过滤过程。该过程结合了用于定位慢动作片段的 VideoLLM (Gemini) 和在人工标注片段上训练的微调 ViT 分类器 (VideoMAEv2)。只有同时满足两个模型严格阈值的片段才会被保留。
- 处理与标注:
- 时间分割: 速度变化检测器将视频分割为具有均匀播放速度的片段。
- 速度标注: 作者使用速度估计器为每个片段提供伪速度标注。
- 元数据构建: 使用 InternVL3 生成密集描述(Dense captions)。这些描述包括短描述和长描述,以及背景、风格、镜头类型、光照和氛围等特定属性,以捕捉语义和美学细节。
方法
作者利用自监督框架训练了一个播放速度估计器,该估计器学习在不需要地面真值速度标注的情况下预测视频中的时间速度变化。核心思想是在时间重采样下强制执行等变性:如果视频被加速 k 倍,预测的速度也应按相同的因子缩放。这一原则通过一个损失函数实现,该函数比较原始片段 V 的预测速度对数与加速片段 Vk 的预测速度对数(并按 k 缩放)。训练目标定义为:
L=[logfθ(Vk)−log(k⋅fθ(V))]2.这种自监督信号应用于训练过程中,其中片段通过随机因子 k∼N(1,2T) 进行下采样。对于帧率已知的视频,模型还结合了监督回归目标以直接预测播放速度。该框架旨在检测速度变化并估计绝对速度,如下图所示。

对于速度调节的视频生成,模型基于 Wan2.1-I2V 架构并引入了显式的速度控制机制。给定图像、文本提示和目标播放速度,模型生成的视频具有反映指定时间速率的动态内容。为了实现这一点,目标速度首先被离散化为对数间隔的桶(buckets),范围从 0.01× 到 1.0×,并使用正弦位置嵌入进行编码。随后将此桶 ID 通过多层感知器(MLP)并添加到时间步嵌入(timestep embedding)中,从而调节去噪调度以符合所需的时间速度。离散化过程定义为:
Butcket_ID=⌊log(1)−log(0.01)log(speed)−log(0.01)⋅Nbuckets⌋,其中 Nbuckets=10 是经验设定的值。为了进一步增强速度控制,模型通过调制潜在特征来应用逐帧调节,该调制使用一个 MLP,其输入为时间步与目标速度乘积的位置嵌入。这种调节应用如下:
latent[i]←latent[i]+MLPψ(ϕ(i⋅speed)),其中 latent[i] 表示时间索引 i 处的潜在特征。这种机制允许模型生成具有不同运动动态的视频,如下图所示。

实验
研究人员通过一系列旨在验证时间速度感知和操控的实验对方法进行了评估。首先对速度变化检测器和播放速度估计器进行了基准测试,证明了自监督方法达到了很高的准确性,并非常接近人类感知。利用新构建的 SloMo-44K 数据集,研究进一步验证了速度调节视频生成和时空超分辨率模型,表明这些模型可以在可控速度下合成逼真的运动,并能从运动模糊的输入中重建清晰的高帧率序列。总体而言,研究结果表明,与现有方法相比,利用高帧率数据和跨模态线索能够实现对现实世界物理动态的更优建模。
作者引入了一个涵盖多种活动和时间尺度的规模化慢动作数据集,用于训练理解和操控视频速度的模型。该数据集明显大于现有集合,从而提升了在速度估计、视频生成和时空超分辨率等任务中的性能。结果显示,在此数据集上训练的模型在速度感知方面达到了接近人类的准确度,并能产生高质量、可控的慢动作视频。所提出的数据集在片段、视频和帧数方面均大幅超过现有的慢动作数据集,为时间建模提供了更稳健的训练。在此数据集上训练的模型在播放速度估计方面达到了接近人类的性能,并在速度控制视频生成和时空超分辨率方面优于基准模型。该数据集同时支持理解和生成任务,在视频取证以及在广泛速度范围内实现现实世界动态的高保真合成方面表现强劲。
作者提出了一种利用自监督信号推断播放速度并操控时间动态的视频理解与生成方法。该方法在速度估计和时空超分辨率等任务上进行了评估,结果显示在定量和感知指标上均优于基准模型。模型实现了与人类感知的高度一致,特别是在生成逼真的慢动作视频和增强低帧率素材方面。与基准模型相比,所提出的方法在视频生成任务中实现了更高的感知质量和运动平滑度。结果表明,该模型生成的视频具有更准确的速度可控性和时间一致性。模型在图像质量和减少闪烁方面均优于基准模型,表明具有卓越的时间相干性。

作者针对清晰输入和运动模糊输入,将时空超分辨率方法与多个基准模型进行了对比评估。结果显示,该方法在多个指标上均表现出优异性能,特别是在处理运动模糊和产生高质量、时间一致的输出方面。该方法始终优于现有模型,证明了在挑战性条件下重建细粒度运动细节的有效性。所提出的方法在时空超分辨率方面显著优于现有基准,尤其是在运动模糊的情况下。它在包括 FID 和 FVD 在内的多个评估指标中均取得了最佳结果,表明了高质量的重建能力。该方法展示了即使从严重模糊的输入中也能生成清晰、连贯帧的鲁棒性。
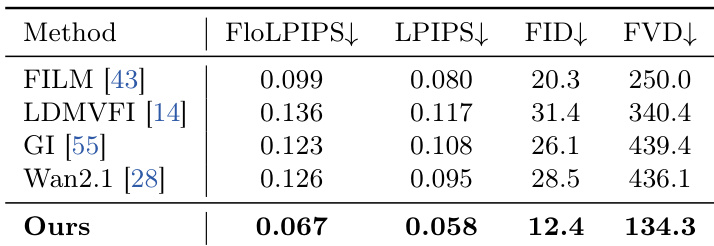
作者将播放速度预测模型与包括人类专家和现有方法在内的多个基准进行了对比评估。结果显示,所提出的方法达到了接近人类专家的性能,在相关性和准确性指标上显著优于其他模型,同时在各种视频条件下估计速度时表现出鲁棒性。所提出的方法在播放速度预测方面达到了接近人类专家的水平,在相关性和误差指标上优于现有模型。该模型相比 VideoLLM 和 SpeedNet 等基准模型有了显著提升,缩小了机器与人类性能之间的差距。该方法在估计视频速度方面表现出强大的鲁棒性和准确性,特别是在具有运动模糊和极端时间尺度的挑战性场景中。
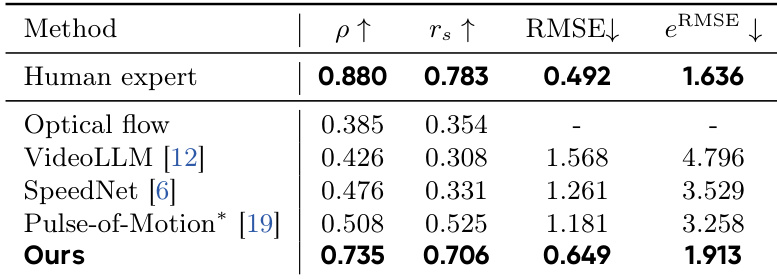
作者评估了训练数据对播放速度预测的影响,对比了在标准视频上训练的模型与在 SloMo-44K 大规模慢动作数据集上训练的模型。结果显示,在 SloMo-44K 上训练的模型在所有指标(包括相关系数和误差度量)上均取得了显著更好的性能,表明具有更优的速度估计准确度。在 SloMo-44K 上训练的模型在所有速度预测指标上均优于在标准视频上训练的模型。在 SloMo-44K 上进行训练带来了与地面真值更高的相关性和更低的预测误差。这种提升在基于线性相关和基于秩的相关度量中均保持一致。
作者使用大规模慢动作数据集在速度估计、视频生成和时空超分辨率等任务中评估了该方法。实验表明,所提出的方法在速度感知方面达到了接近人类的准确度,并能产生具有卓越运动平滑度的高质量、时间一致的视频。此外,该模型在从运动模糊输入中重建细粒度细节方面表现出高度的鲁棒性,并从新数据集提供的多样化时间尺度中显著获益。