Command Palette
Search for a command to run...
StyleID:一种用于风格无关的人脸身份识别的感知感知数据集与度量指标
StyleID:一种用于风格无关的人脸身份识别的感知感知数据集与度量指标
Kwan Yun Changmin Lee Ayeong Jeong Youngseo Kim Seungmi Lee Junyong Noh
摘要
创意人脸风格化旨在将肖像渲染为卡通、素描和绘画等多种视觉风格,同时保留可辨识的身份特征。然而,目前的身份编码器(identity encoders)通常基于自然照片进行训练和校准,在风格化场景下表现出严重的脆弱性。它们往往会将纹理或色调的变化误判为身份漂移,或者无法检测到几何形状的夸张变化。这表明目前缺乏一种与风格无关(style-agnostic)的框架,来评估和监督不同风格及强度下的身份一致性。为了填补这一空白,我们推出了 StyleID,这是一个针对风格化人脸身份的人类感知觉察数据集及评估框架。StyleID 由两个数据集组成:(i) StyleBench-H,这是一个基准测试集,旨在捕捉人类在不同风格强度下,针对基于扩散模型(diffusion-based)和流匹配模型(flow-matching-based)的风格化效果所做出的“相同/不同”验证判断;(ii) StyleBench-S,这是一个监督集,通过受控的双选强制选择(2AFC)实验获得的心理测量识别强度曲线推导而来。利用 StyleBench-S,我们对现有的语义编码器进行了微调,使其相似度排序在不同的风格和强度下都能与人类感知保持一致。实验结果表明,我们校准后的模型与人类判断的相关性显著提高,并且在面对域外(out-of-domain)的艺术家手绘肖像时表现出更强的鲁棒性。我们所有的数据集、代码和预训练模型均已在 https://kwanyun.github.io/StyleID_page/ 公开。
一句话总结
为了解决当前身份编码器在艺术风格化下的脆弱性,作者提出了 StyleID。这是一个感知觉察框架及数据集,包含用于人类验证基准的 StyleBench-H,以及通过心理测量识别强度曲线进行监督的 StyleBench-S。该框架通过微调语义编码器,使相似度排序与人类感知保持一致,并增强了对域外艺术家绘制肖像的鲁棒性。
核心贡献
- 本文引入了 StyleBench-H,这是一个人工标注的基准,旨在通过捕捉跨各种风格化方法和强度的、与感知一致的“相同-不同”验证判断,来评估身份保持能力。
- 本工作提出了 StyleBench-S,这是一个大规模合成监督数据集,源自心理测量识别强度曲线,为学习在风格化下保持稳定的身份表示提供了结构化的训练信号。
- 研究人员开发了 StyleID,这是一种与风格化无关的面部身份识别模型,其与人类判断的相关性高于现有编码器,并包含用于提高计算效率的轻量化变体。
引言
创意面部风格化对于个性化化身和数字内容至关重要,但保持可识别的身份仍然是一个重大挑战。目前的身份编码器通常在自然照片上进行训练和校准,这使得它们在应用于风格化图像时显得非常脆弱。这些模型往往无法区分实际的身份漂移与纹理、颜色或夸张几何形状的变化。
作者通过引入 StyleID 来填补这一空白,这是一个旨在应对多种风格化方法和强度下的身份识别的感知觉察框架。研究贡献了两个新颖的数据集:StyleBench-H,一个用于身份验证的人工判断基准;以及 StyleBench-S,一个源自人类心理测量识别曲线的大规模合成监督集。通过在 StyleBench-S 上微调语义编码器,作者开发了一个使相似度排序与人类感知一致的模型,在各种艺术风格下展示了卓越的鲁棒性以及与人类判断的高度相关性。
数据集
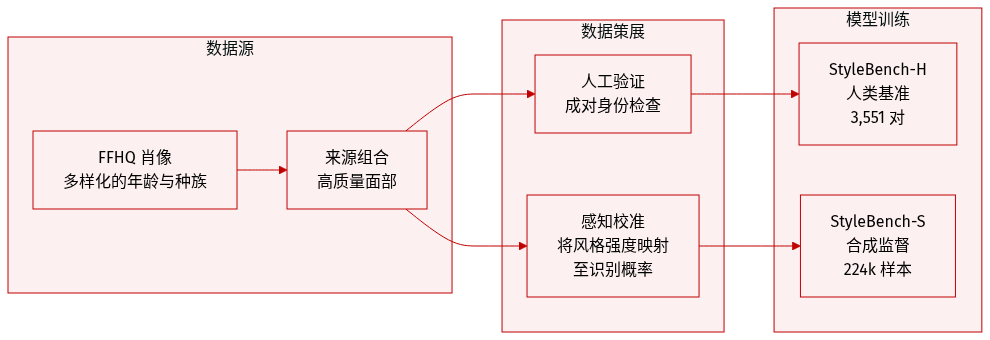
作者引入了 StyleBench,这是一个旨在通过两个专门的子集使算法身份指标与人类感知对齐的数据集框架:
-
StyleBench-H (人类感知基准):
- 组成与来源: 一个由 3,551 个有效数据点组成的严格基准。作者从 FFHQ 中采样高质量的源肖像,在过滤掉具有多样化种族和年龄属性的同时,剔除了头部旋转角度过大或包含多人的图像。
- 处理与标注: 对于每个源身份,作者使用三种不同的方法,在 10 种艺术风格和 7 个离散强度级别上生成了风格化的对应图像。人工标注员执行成对验证任务,以确定源图像和风格化图像是否描绘了同一个人。
- 过滤规则: 为确保数据质量,作者根据响应延迟(过快或超过 100 秒)和不一致性(未通过重复问题测试)丢弃了响应。最终集合经过平衡,仅包含真阳性(true-positive)和真阴性(true-negative)对。
- 评估划分: 作者创建了跨风格(Cross-Style)和跨方法(Cross-Method)划分,以测试在更严格的分布偏移下的鲁棒性,使用了未见的身份、风格以及如 MTG 和 Flux.2 等风格化方法。
-
StyleBench-S (大规模合成监督集):
- 组成与规模: 一个庞大的合成数据集,包含约 224,000 个风格化样本,源自 4,073 个唯一身份。每个身份关联有 55 张风格化图像。
- 校准策略: 为确保合成数据反映人类判断,作者首先使用二选一强迫选择(2AFC)协议进行了校准研究。这使得能够推导出将风格化强度映射到人类识别概率的心理测量识别曲线。
- 选择逻辑: 作者利用这些曲线来选择感知层面的正样本。仅包含估计的人类识别概率保持在高水平(高于 90% 阈值)的图像对。为了保持严格的身份一致性,对于每种方法-风格组合,优先选择识别等级最高和次高的样本。
- 用途: 作者将 StyleBench-S 用作大规模监督集来训练风格鲁棒的身份编码器,提供经过人类感知阈值校准的可扩展训练信号。
方法
作者利用多阶段流水线开发了一种与风格化无关的身份识别模型,从可控的风格化框架开始,最终实现感知校准的身份编码器。整个过程围绕三个主要组件构建:风格化流水线、训练数据集以及专为鲁棒身份嵌入设计的模型架构。
风格化流水线能够生成与源身份存在受控偏差的肖像。作者采用了三种最先进的基于扩散(diffusion-based)和基于流(flow-based)的方法——IP-Adapter、InstantID 和 InfiniteYou——每种方法都支持对风格化强度的显式控制。对于 IP-Adapter,身份信息通过交叉注意力机制注入,风格化强度通过注意力层的缩放和文本调节进行调制,参数化为 sip∈[0,1]。InstantID 将 ControlNet 与类似于 IP-Adapter 的注意力注入相结合,其中风格化强度由 ControlNet 强度和风格调节决定,记作 sid∈[0,1]。InfiniteYou 是一种流匹配方法,使用风格强度参数 sinf∈[0,1]。所有方法都对强度参数进行归一化,使得 s=0 产生最小风格化,而 s=1 代表最大风格化。在数据集构建中,这些参数被离散化为 7 个级别。然而,由于机制不同,相同的归一化值并不能保证跨方法的感知等效性。不同强度下的示例输出如图 2 所示。
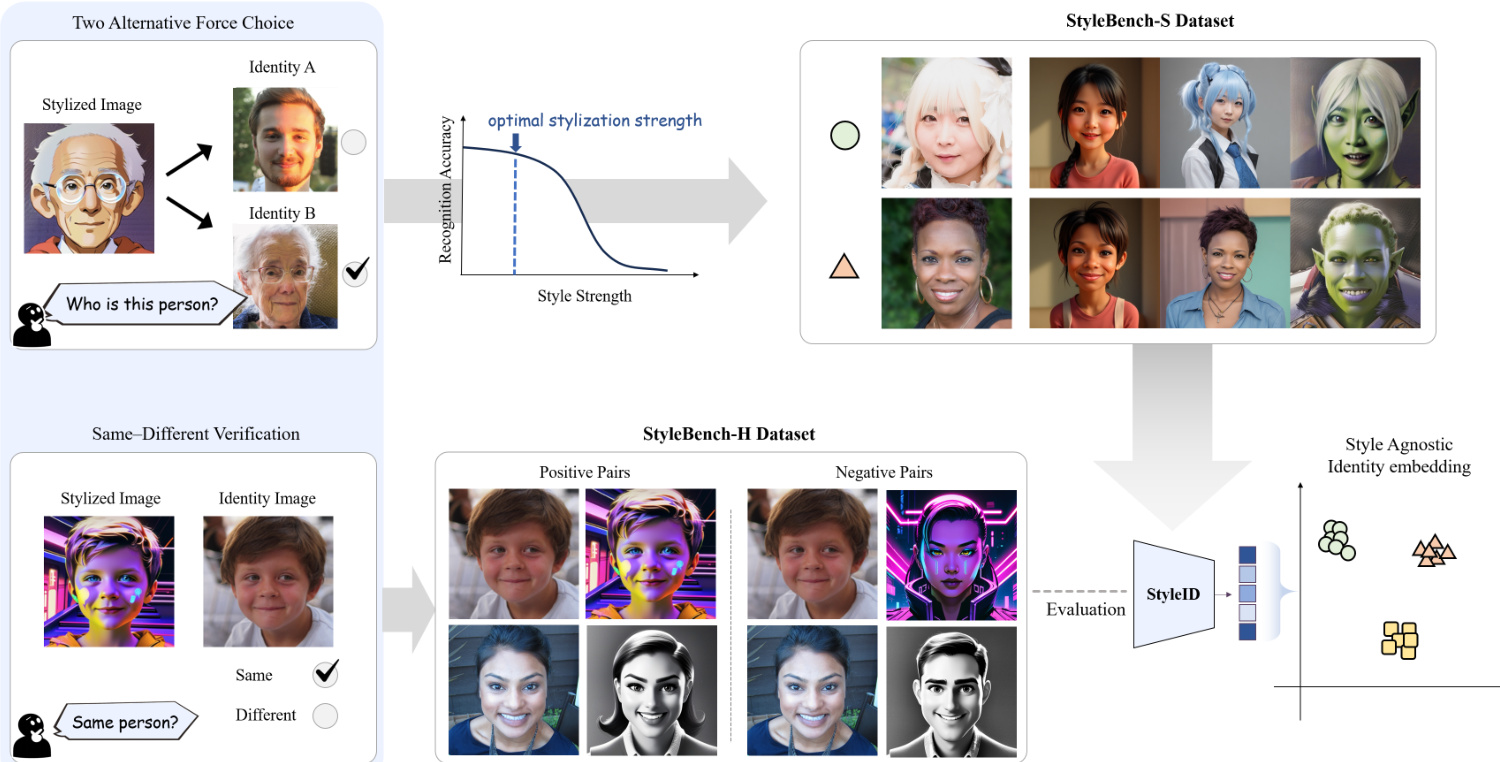
框架图展示了系统的核心组件,包括风格化过程以及识别准确率随风格强度变化的评估。如下图所示,识别准确率在最佳风格化强度处达到峰值,并随着风格化程度的增加而下降,这突显了对能够在不同水平艺术转换下保持鲁棒性的模型的需求。
作者引入了 StyleID,这是一种基于 CLIP 构建的与风格化无关的身份编码器,CLIP 是以对外观和纹理变化具有鲁棒性而闻名的大规模文本-图像语义编码器。为了使 CLIP 适应风格化身份识别并保留其预训练表示,图像编码器被冻结,并将 LoRA 适配器注入到注意力层和线性层中,以学习轻量级且风格鲁棒的身份表示。这种适配防止了过拟合以及偏离 CLIP 预训练流形的灾难性漂移。在生成的嵌入之上,应用了类似于 ArcFace 的角边距函数,以强制执行身份之间的判别性角边距,确保即使在显著的风格偏移下也能保持一致的分离。
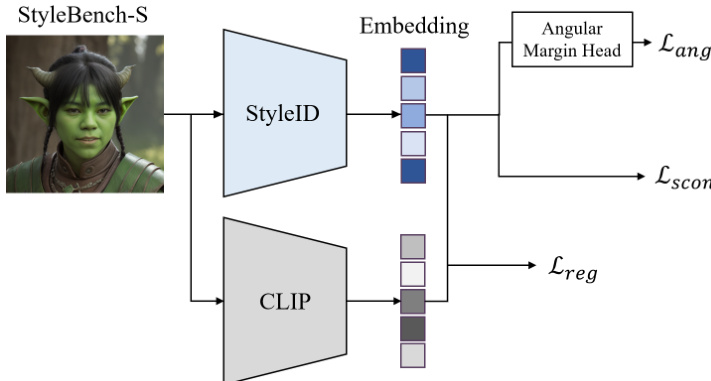
StyleID 的训练目标结合了三个项:角身份损失(angular identity loss)、监督对比损失(supervised contrastive loss)以及嵌入正则化损失(embedding regularization loss)。角身份损失使用 ArcFace 公式。对于具有嵌入 zi 的样本 i,在进行 ℓ2 归一化得到 z^i 后,类别 c 的余弦逻辑值(cosine logit)为 cosθi,c=z^i⊤w^c,其中 w^c 是归一化的类别权重。带有加性角边距 m 和缩放因子 α 时,样本 i 的 ArcFace 损失计算如下:
ℓiang=−logexp(α⋅cos(θi,yi+m))+∑c=yiexp(α⋅cosθi,c)exp(α⋅cos(θi,yi+m)),批次损失为 Lang=B1∑i=1Bℓiang。
此外,采用监督对比损失来增强身份之间的实例级分离。对于每个锚点 i,正样本定义为小批量中共享相同身份的样本,P(i)={p∈{1,…,B}∖{i}∣yp=yi}。使用温度参数 τ,锚点 i 的损失为:
ℓiscon=−∣P(i)∣1p∈P(i)∑log∑a∈{1,…,B}∖{i}exp(z^i⊤z^a/τ)exp(z^i⊤z^p/τ),批次损失为 \mathcal{L}_{\mathrm{scon} = \frac{1}{B} \sum_{i=1}^{B} \ell_i^{\mathrm{scon}}。
最后,为了稳定训练并防止过拟合,嵌入正则化项约束适配后的表示保持接近原始冻结的 CLIP 嵌入:
Lreg=B1i=1∑Bz^i−z^i(0)22,其中 z^i(0) 是来自冻结 CLIP 编码器的嵌入。总训练损失为:
L=Lang+λsconLscon+λregLreg,带有平衡权重 λscon 和 λreg。
实验
研究人员利用人工标注的基准和艺术家绘制的素描数据集,针对各种侧重身份和语义表示的模型对 StyleID 进行了评估,以衡量在显著风格化下的身份保持能力。在验证、检索和姿态鲁棒性任务中的实验表明,尽管外观发生了极端变化,StyleID 通过保持高判别力和与人类一致的身份线索,始终优于基线模型。此外,将 StyleID 集成到生成框架中,通过更好地将身份与艺术纹理和颜色解耦,提高了风格化输出的质量。
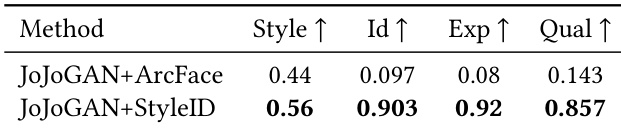
作者比较了在风格化中使用 ArcFace 和 StyleID 作为身份约束时 JoJoGAN 的性能。结果显示,StyleID 在所有指标上都显著优于 ArcFace,在风格、身份、表情和质量方面均获得了更高的分数。这表明 StyleID 为风格化提供了更有效的身份表示,能够更好地将身份从外观属性中解耦,并产生视觉上更优的输出。StyleID 在风格化保真度和质量的所有评估指标上均优于 ArcFace。StyleID 实现了身份与外观更好的解耦,从而产生更连贯、无伪影的风格化输出。StyleID 的提升在自动化评估和人工评估中均保持一致,表明其与感知身份保持具有更强的对齐性。
作者在身份验证任务上,使用多个数据集和指标将 StyleID 与几种基线方法进行了比较。结果显示,StyleID 在几乎所有评估指标上都优于所有基线,证明了在风格化下保持身份一致性的卓越性能。该模型实现了最高的真阳性率、验证准确率和 ROC 曲线下面积,表明即使在外观发生显著变化的情况下,身份嵌入也具有鲁棒性和强大的可分离性。StyleID 在所有评估指标(包括真阳性率、验证准确率和 AUROC)上均实现了最高性能,优于所有基线方法。像 CLIP 和 SigLIP2 这样的语义编码器与人类身份判断的一致性较弱,而像 ArcFace 和 AdaFace 这样侧重身份的模型表现较好,但在风格化下仍显不足。StyleID 在 StyleBench-H 和 SKSF-A 上始终优于基线,展示了在多样化且具有挑战性的风格化条件下的鲁棒性。
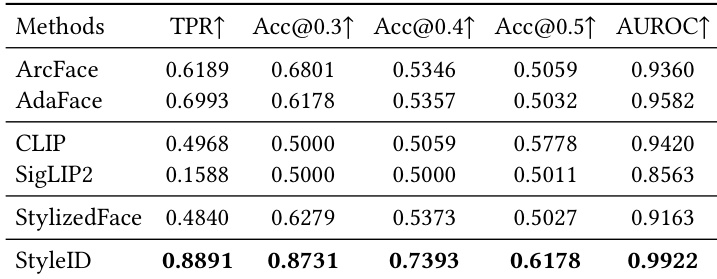
作者在两个数据集上将 StyleID 与几种基线方法进行了比较,证明了 StyleID 在风格化下的身份验证任务中取得了卓越性能。结果显示,StyleID 在多个指标上均优于侧重身份的模型和语义编码器,特别是在具有挑战性的跨风格和跨方法场景中。StyleID 在极端艺术转换下仍保持强劲性能,并对姿态变化表现出鲁棒性,同时其轻量化变体即使在降低计算成本的情况下也具有竞争力。StyleID 在两个数据集和评估划分的身份验证中始终优于所有基线。StyleID 实现了最高的验证准确率和 AUROC 值,尤其是在具有挑战性的跨风格和跨方法场景中。StyleID 的轻量化变体尽管降低了计算成本,但仍保持了强劲性能,优于传统的面部识别模型。
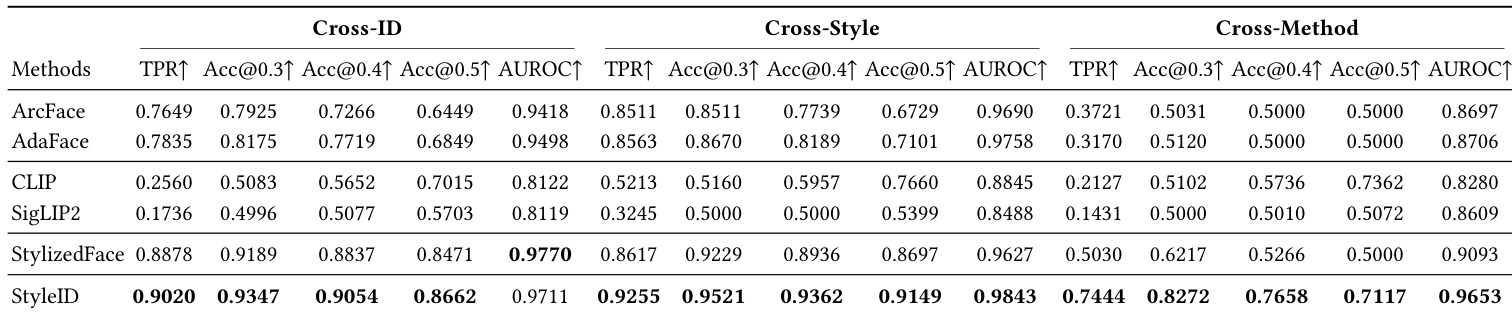
作者在 StyleBench-H 和 SKSF-A 两个数据集上,使用真阳性率、准确率和 AUROC 等验证指标将 StyleID 与基线方法进行了比较。结果显示,StyleID 在两个数据集上始终优于其他方法,在所有报告的指标中均达到了最高值。性能差距在跨风格和跨方法场景中尤为显著,在这些场景下,StyleID 在显著的风格化变化下仍能保持鲁棒的身份验证。StyleID 在 StyleBench-H 和 SKSF-A 上的所有指标中均实现了最高性能,优于所有基线方法。这种提升在具有挑战性的跨风格和跨方法设置中最为明显,表明了在显著风格化下的鲁棒性。StyleID 展示了卓越的验证性能,具有最高的真阳性率和 AUROC 值,表明相同身份对和不同身份对之间具有很强的可分离性。
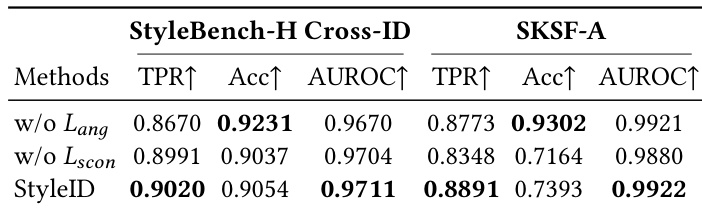
作者在 StyleBench-H 和 SKSF-A 两个数据集上,使用包括真阳性率、准确率和 AUROC 在内的验证指标,将 StyleID 与基线方法进行了比较。StyleID 在两个数据集的所有指标上均始终优于基线,证明了在风格化下卓越的身份保持能力。结果表明,StyleID 即使在具有挑战性的条件下也能保持高性能,而基线表现出显著的退化。StyleID 在 StyleBench-H 和 SKSF-A 的所有指标上均优于基线。与基线相比,StyleID 实现了更高的真阳性率、准确率和 AUROC 值。基线在风格化下表现出显著的性能下降,而 StyleID 保持了鲁棒的验证性能。
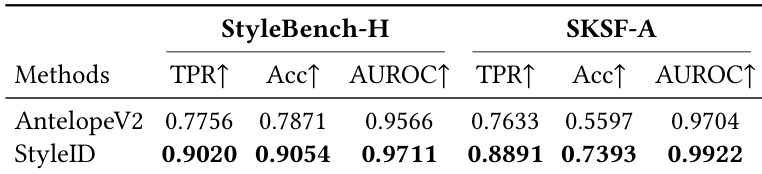
作者通过在多个数据集上的风格化保真度测试和身份验证任务,将 StyleID 与各种身份约束和基线模型(包括 ArcFace、CLIP 和 SigLIP2)进行了评估。结果表明,StyleID 通过有效地将身份从外观属性中解耦,提供了卓越的身份表示,从而产生更连贯、无伪影的风格化输出。即使在极端的艺术转换和具有挑战性的跨风格场景下,StyleID 仍能保持鲁棒的身份一致性,并优于语义编码器和传统的侧重身份的模型。