Command Palette
Search for a command to run...
WorldMark:一个用于交互式视频世界模型的统一基准测试套件
WorldMark:一个用于交互式视频世界模型的统一基准测试套件
Xiaojie Xu Zhengyuan Lin Kang He Yukang Feng Xiaofeng Mao Yuanyang Yin Kaipeng Zhang Yongtao Ge
摘要
Genie、YUME、HY-World 和 Matrix-Game 等交互式视频生成模型正在飞速发展,然而每个模型都使用其自带的基准测试(benchmark)进行评估,且这些测试涉及私有的场景和轨迹,导致无法进行公平的模型间横向比较。现有的公开基准测试虽然提供了轨迹误差、美学评分以及基于视觉语言模型(VLM)的判定等有用指标,但由于输入方式各异,这些指标均缺乏标准化的测试条件——即完全相同的场景、完全相同的动作序列以及统一的控制接口——从而无法在不同模型之间实现可比性。为此,我们推出了 WorldMark,这是首个为交互式图像到视频(Image-to-Video)世界模型提供统一“竞技场”的基准测试。WorldMark 的贡献包括:(1) 统一动作映射层:该层将共享的 WASD 式动作词表转化为每个模型原生的控制格式,从而实现在相同的场景和轨迹下,对六个主流模型进行“苹果对苹果”(即同标准)的公平比较;(2) 分层测试套件:包含 500 个评估案例,涵盖了第一人称与第三人称视角、写实与风格化场景,以及从“简单”到“困难”的三个难度等级,视频时长跨度为 20 至 60 秒;(3) 模块化评估工具包:涵盖视觉质量(Visual Quality)、控制对齐度(Control Alignment)和世界一致性(World Consistency)三个维度,其设计旨在让研究人员在利用我们标准化输入的同时,能够随着领域的发展接入其自定义的评估指标。我们将发布所有数据、评估代码及模型输出结果,以促进后续研究。除了离线指标外,我们还推出了 World Model Arena (warena.ai),这是一个在线平台,任何人都可以通过侧对侧(side-by-side)的对决方式让领先的世界模型同台竞技,并实时查看排行榜。
一句话总结
为了实现交互式视频世界模型公平的跨模型比较,作者推出了 WorldMark,这是一个统一的基准测试套件。该套件利用标准化的动作映射层(action-mapping layer)以及包含 500 个案例的分层测试集,涵盖多种视角和难度等级,用于评估视觉质量、控制对齐度以及世界一致性。
核心贡献
- 本文介绍了 WorldMark,这是一个针对交互式图像到视频(Image-to-Video)世界模型的标准化基准测试,利用统一的动作映射层将共享的 WASD 风格命令转换为各种原生的控制格式。该机制通过在相同的场景和轨迹上测试不同的模型,实现了模型间的直接比较。
- 该工作提供了一个由 500 个评估案例组成的分层测试集,涵盖第一人称和第三人称视角、写实与风格化环境,以及从 20 秒到 60 秒不等的三个难度等级。
- 提出了一种模块化评估工具包,通过结合几何轨迹指标和基于 VLM 的评分,来评估视觉质量、控制对齐度和世界一致性。该工具包旨在允许研究人员在利用基准测试标准化输入的同时,随着领域的发展集成新的指标。
引言
交互式视频生成模型正在演变为复杂的世界模拟器,能够响应用户动作和摄像机控制。然而,该领域目前缺乏一种标准化的方法来比较这些模型,因为每个开发者都使用私有场景、定制轨迹和异构的控制接口。虽然现有的基准测试为视觉质量或物理一致性提供了有用的指标,但它们无法提供进行有意义的跨模型比较所需的相同测试条件。
作者推出了 WorldMark,这是首个旨在为交互式图像到视频世界模型提供共同竞技场的基准测试套件。通过利用统一的动作映射层,可以将共享的 WASD 风格词汇转换为任何给定模型的特定控制格式,例如文本提示或姿态参数。为了确保测试的全面性,作者贡献了一个包含 500 个评估案例的分层套件,涵盖各种视角和难度等级,并配备了用于评估视觉质量、控制对齐度和世界一致性的模块化工具包。
数据集
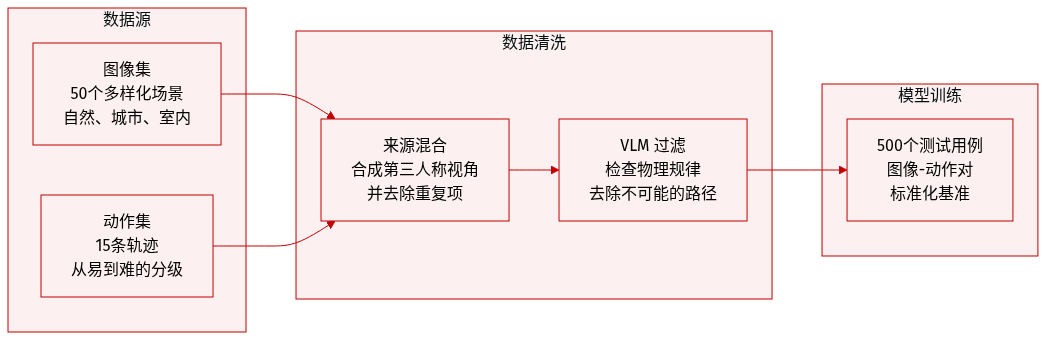
作者推出了 WorldMark,这是一个针对交互式图像到视频 (I2V) 世界模型的标准化基准测试工具包。数据集结构如下:
-
数据集构成与来源
- 作者从 WorldScore 数据集中提取了图像集(Image Suite),该数据集汇集了来自各种现有来源的图像。
- 动作集(Action Suite)由 15 个标准化的动作轨迹组成,范围从简单的平移到复杂的循环运动。
- 通过结合图像和动作,作者创建了一个包含约 500 个标准化评估案例的测试集。
-
子集详情与过滤
- 图像集: 该子集包含 100 张图像。作者首先从 WorldScore 获取 50 张参考图像,并移除重复及近乎重复的图像以最大化多样性。为了实现视角评估,使用图像生成模型为每张原始第一人称图像合成第三人称视角。该套件涵盖三个场景类别(自然、城市、室内)、两种视觉风格(写实、风格化)和两种视角(第一人称和第三人称)。
- 动作集: 该子集包括 15 条轨迹,分为三个难度等级:简单(20 秒单段)、中等(40 秒两段)和困难(60 秒三段)。
- 动作过滤: 为了确保物理合理性,作者使用视觉语言模型 (VLM) 分析每个场景。VLM 识别物理约束(如障碍物),并过滤掉在特定环境中不可能实现的轨迹。
-
处理与元数据构建
- 统一动作接口: 为了实现不同模型之间的“公平”比较,作者使用针对每个模型的适配器,将共享的 WASD + L/R 旋转词汇映射到每个模型的特定原生控制格式。
- 评估框架: 数据被集成到一个模块化的四阶段流水线中,从三个维度评估模型:视觉质量、控制对齐度和世界一致性。
方法
作者利用一个模块化框架,旨在实现不同系统间交互式世界模型的一致性评估,解决了异构动作接口带来的挑战。该方法的核心是一个统一的动作接口,用于标准化输入命令,使不同的模型能够在共同的一组指令下运行。该框架定义了一个由六个离散原语组成的共享动作词汇:前进 (W)、后退 (S)、左平移 (A)、右平移 (D)、左偏航 (L) 和右偏航 (R),每个原语都由持续时间参数化。动作集中的所有 15 条轨迹均由该词汇构建,确保了评估过程中的语义一致性。
参考框架图:该共享词汇通过动作映射适配器转换为每个模型的原生控制格式。例如,YUME 解析嵌入在自然语言标题中的 WASD 指令,HY-World 处理结构化的 6-DoF 姿态参数,Genie 3 接受手柄风格的控制,Matrix-Game 暴露自定义动作函数,而 Open-Oasis 则基于 25 维连续动作向量运行。适配器通过校准每个模型的参数(如步长和偏航率)来保留预期的语义行为,从而在不同架构上实现相同动作的忠实执行。这种设计确保所有模型在遵循架构约束的同时,接收到语义完全相同的指令。添加对新模型的支持仅需实现单个适配器,从而最大限度地降低了集成开销。
评估工作流将此统一接口与其他组件集成:图像选择、动作映射、视频生成和指标评估。给定目标模型,用户首先根据视角、场景类别或视觉风格选择图像,或者提供自定义参考,由 VLM 脚本推断合适的动作序列。所选图像和动作随后进入动作映射阶段,由针对每个模型的适配器将共享的 WASD+L/R 词汇转换为目标模型的原生格式。构建好 (text, image, action) 三元组后,视频生成阶段在标准化条件下运行模型。最后,指标评估阶段使用八项指标套件对输出进行评分,模块化设计允许用户在不修改其他阶段的情况下接入自定义或第三方的指标。
框架设计通过一系列可视化进行了展示。第一部分展示了多样的场景、风格和视角,包括写实的第一人称和第三人称视角以及风格化变体,展示了系统能够处理的环境范围。第二部分描述了统一的动作映射过程,其中共享词汇被转换为不同模型的相应控制格式,突出了该方法的适应性。第三部分对多个模型(Genie 3、YUME、HY-World、MatrixGame 和 HY-Game)在给定相同参考图像和动作时的输出进行了对比分析,展示了尽管输入相同,质量和行为仍存在差异。这种差异性强调了标准化评估框架的重要性。最后的视觉化展示了一个 VLM 推理过程:给定一张地铁站的图像,模型识别出物理障碍并推断出安全通行路径,生成诸如“前进”、“后退”和“行走+平移”之类的输出动作序列。这证明了系统具备推理环境约束并选择适当动作的能力,生成的轨迹以随时间变化的位移和偏航进行可视化。
实验
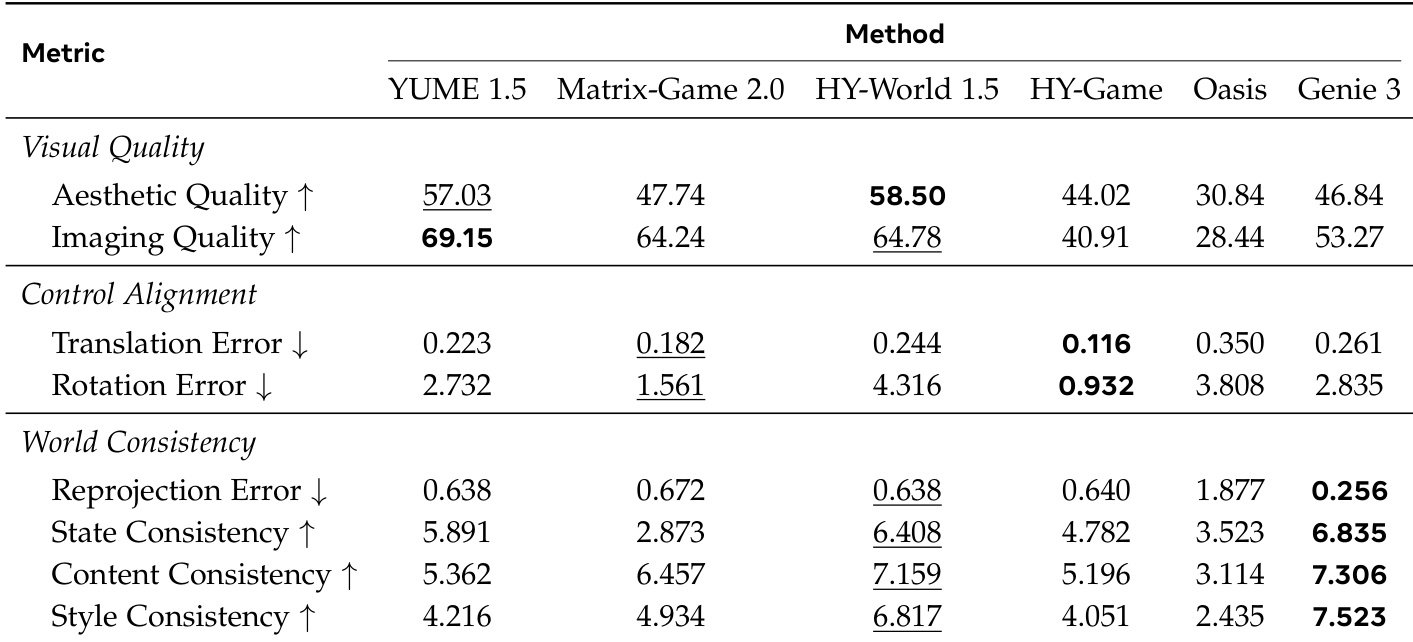
WorldMark 评估套件从三个维度对交互式视频生成模型进行基准测试:视觉质量、控制对齐度和世界一致性。通过在第一人称和第三人称视角下测试各种开源和闭源模型,实验表明,高帧级美学并不一定能保证时间或几何上的连贯性。虽然某些模型在精确遵循命令或视觉吸引力方面表现出色,但像 Genie 3 这样的闭源模型在随时间保持稳定的 3D 环境和风格统一性方面表现出更优的能力。
作者使用全面的指标套件,从视觉质量、控制对齐度和世界一致性等多个维度评估了多种交互式视频生成模型。结果显示,不同模型在不同领域表现出色,一些模型实现了高视觉保真度,而另一些则保持了更好的时间连贯性和控制准确性,且性能在第一人称和第三人称视角之间存在显著差异。Genie 3 在写实和风格化场景的世界一致性指标中始终取得最好或接近最好的结果。HY-World 1.5 在视觉质量和控制对齐度方面表现强劲,尤其是在第一人称评估中。Matrix-Game 2.0 显示出较高的平移误差和显著的旋转误差,表明在维持控制保真度方面存在挑战,尤其是在第三人称设置下。
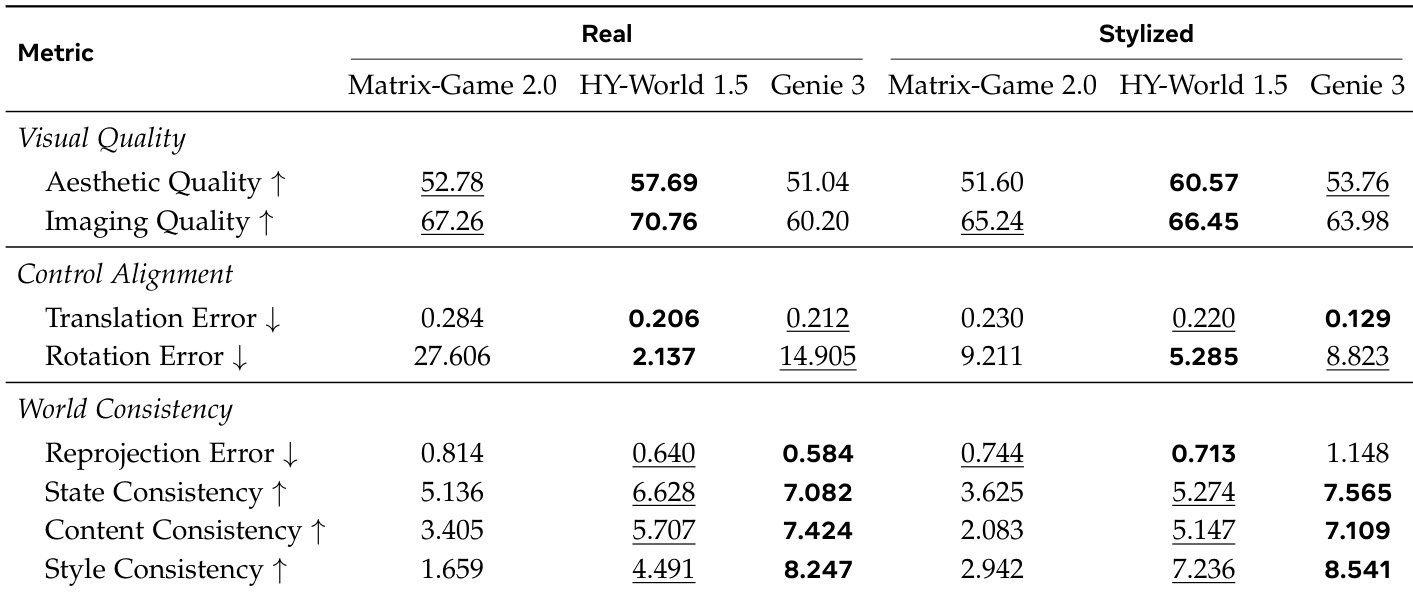
作者使用一套评估帧级保真度、几何控制和时间连贯性的指标,从视觉质量、控制对齐度和世界一致性三个维度对视频生成模型进行评估。结果显示,不同模型在不同领域各有优势,一些模型实现了高视觉吸引力但世界连贯性较差,而另一些模型尽管帧级质量较低,却保持了强大的空间和时间一致性。模型在视觉质量和世界一致性之间存在权衡,部分模型产生了高保真度的帧但缺乏时间连贯性。控制对齐性能差异显著,某些模型表现出强大的几何保真度,而其他模型在旋转一致性方面表现挣扎。在第一人称和第三人称评估中,闭源模型在维持世界一致性方面始终优于开源基准模型。

作者引入了 WorldMark,这是一个旨在从视觉质量、控制对齐度和世界一致性等多个维度评估交互式图像到视频生成模型的基准测试。该基准测试支持交互式 I2V 任务和跨模型评估,提供了捕捉帧级保真度和时间连贯性的全面评估,并侧重于交互式和跨模型场景。WorldMark 评估交互式 I2V 任务,支持跨模型和交互式评估。该基准测试评估了包括视觉质量、控制对齐度和世界一致性在内的多个维度。与之前的基准测试不同,WorldMark 实现了不同模型和交互类型之间的统一评估。
作者从视觉质量、控制对齐度和世界一致性三个维度评估了多个视频生成模型。结果显示,不同模型在不同方面表现出色,一些模型实现了高视觉保真度但控制或一致性较差,而另一些模型保持了强大的世界连贯性但帧级质量较低。Genie 3 在各种场景的世界一致性指标中始终表现良好,而 HY-World 1.5 在第一人称和第三人称视图的视觉质量方面领先。Genie 3 在所有场景的世界一致性指标中均取得了最佳性能,展示了强大的时间与空间连贯性。HY-World 1.5 在视觉质量方面优于其他模型,尤其是在美学和成像质量方面。控制对齐性能在不同模型之间差异很大,某些模型显示出较低的平移误差但较高的旋转误差,表明在几何保真度方面各有侧重。
作者在视觉质量、控制对齐度和世界一致性维度上评估了多个交互式视频生成模型。结果显示,不同模型在特定领域表现出色,一些模型实现了高美学质量但时间连贯性较差,而另一些模型尽管帧级保真度较低,却能维持一致的世界。YUME 1.5 在视觉质量指标中获得了最高分,尤其是在美学和成像质量方面。HY-Game 表现出最佳的控制对齐度,具有最低的平移和旋转误差。Genie 3 在所有指标的世界一致性方面均处于领先地位,表明其具有卓越的时间连贯性和稳定性。
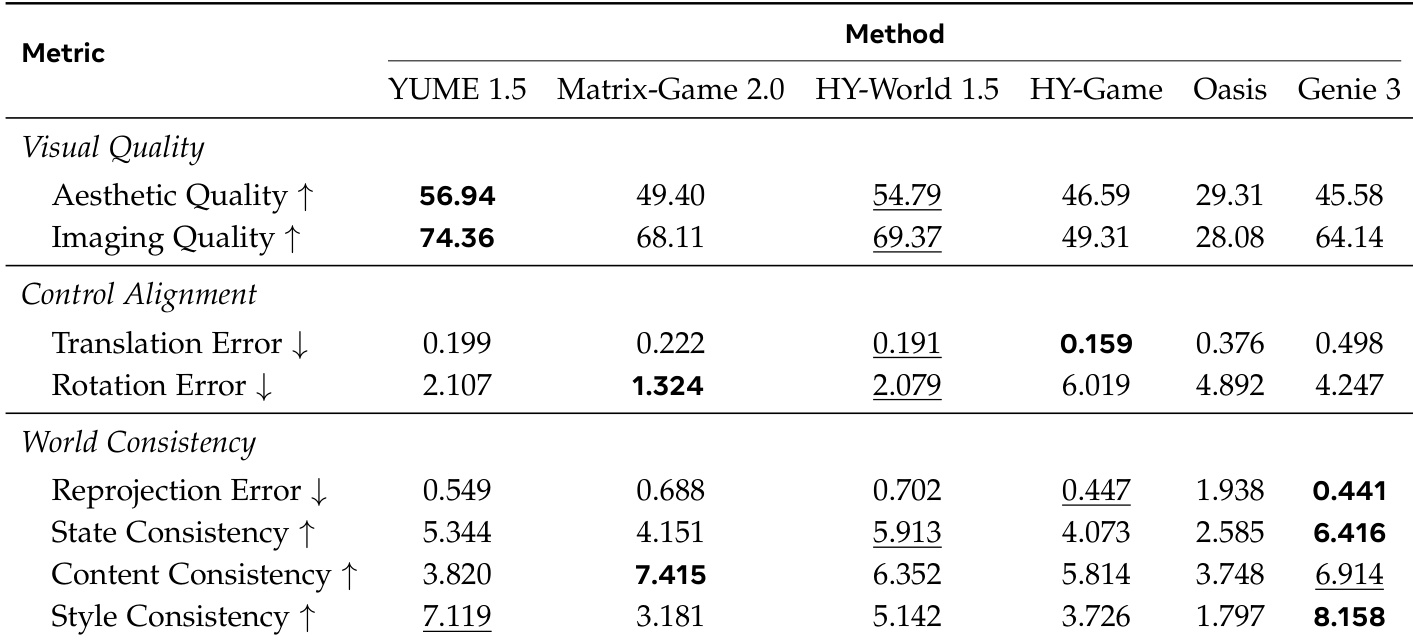
作者利用 WorldMark 基准测试,从视觉质量、控制对齐度和世界一致性维度评估交互式视频生成模型。实验揭示了模型之间固有的权衡,因为一些模型优先考虑高美学保真度,而另一些则在时间连贯性和几何稳定性方面表现出色。总体而言,不同模型展现出专业化的优势,某些架构在视觉吸引力方面领先,某些在精确控制遵循方面领先,另一些则在不同视角下维持一致的世界物理规律方面表现出色。