Command Palette
Search for a command to run...
用于增强鲁棒性分布式预训练的解耦 DiLoCo 方法
用于增强鲁棒性分布式预训练的解耦 DiLoCo 方法
Decoupled DiLoCo Team
摘要
现代大规模语言模型(LLM)的预训练高度依赖于单程序多数据(SPMD)范式,这种范式要求各加速器之间进行紧密耦合。由于这种耦合特性,瞬时减速、硬件故障以及同步开销会导致整个计算过程停滞,在大规模训练时会浪费大量的计算时间。虽然近期出现的 DiLoCo 等分布式方法降低了通信带宽的需求,但它们在本质上仍属于同步机制,容易受到此类系统停滞的影响。为了解决这一问题,我们提出了 Decoupled DiLoCo。作为 DiLoCo 框架的演进版本,Decoupled DiLoCo 旨在打破步调一致的同步壁垒,超越 SPMD 范式,从而实现训练有效吞吐量(goodput)的最大化。Decoupled DiLoCo 将计算任务分配给多个独立的“学习器”(learners),每个学习器执行局部的内部优化步骤。这些学习器将参数分片异步地通信至一个中央同步器;该同步器通过采用最小法定人数(minimum quorum)、自适应宽限窗口(adaptive grace window)以及动态 token 加权合并(dynamic token-weighted merging)机制来聚合更新,从而绕过失效或运行缓慢(straggling)的学习器。受“混沌工程”(chaos engineering)的启发,我们在包含数百万个模拟芯片、且故障频发的环境中,实现了训练效率的显著提升,并确保了严格的零全局停机时间(zero global downtime)。同时,在文本和视觉任务上,无论是对于稠密(dense)架构还是混合专家(Mixture-of-Expert, MoE)架构,Decoupled DiLoCo 均能保持极具竞争力的模型性能。
一句话总结
受混沌工程启发,Decoupled DiLoCo 是 DiLoCo 框架的演进版本,它将计算分配给独立的学习者,异步地将参数片段通信给中央同步器。同步器采用最小法定人数、自适应宽限窗口和动态 token 加权合并,以规避硬件故障,最大化训练有效吞吐量,并在数百万模拟芯片上实现严格的零全局停机时间,同时在密集和混合专家架构的文本和视觉任务上保持具有竞争力的性能。
核心贡献
- Decoupled DiLoCo 被引入作为 DiLoCo 框架的演进版本,旨在打破单程序多数据(SPMD)范式的锁步同步障碍。该系统将计算分配给多个独立的学习者,执行局部内部优化步骤以最大化训练有效吞吐量。
- 独立学习者异步地将参数片段通信给中央同步器,同步器使用最小法定人数、自适应宽限窗口和动态 token 加权合并来聚合更新。这种方法规避了失败或落后的学习者,确保在易发生故障的环境中具有弹性。
- 数百万模拟芯片的实验表明,训练效率显著提高,且严格实现零全局停机时间。模型性能在基准测试中保持竞争力,包括 MMLU-Pro 和 GSM8K,适用于密集和混合专家架构。
引言
现代大规模语言模型预训练依赖于单程序多数据(SPMD)范式,该范式强制加速器之间紧密耦合,并造成可靠性瓶颈,单个硬件故障会导致整个系统停滞。虽然像 DiLoCo 这样的近期方法减少了通信带宽,但它们本质上仍然是同步的,并且容易受到这些系统停滞的影响。为了解决这个问题,作者引入了 Decoupled DiLoCo,这是一个通过跨独立学习者划分计算来打破同步障碍的框架。这些学习者执行局部优化步骤,并异步地将参数片段通信给中央同步器,同步器使用最小法定人数和基于 tokens 的加权合并来聚合更新。这种方法在易发生故障的环境中最大化训练有效吞吐量,实现零全局停机时间,同时保持具有竞争力的模型性能。
数据集
作者采用了一套多样的基准测试来评估模型在文本和视觉能力方面的性能。
-
数据集组成和来源
- 评估套件汇集了先前研究中的既定公开数据集,包括 Clark 等人、Zellers 等人以及 Yue 等人的引用。
- 数据分为基于文本的推理基准和基于视觉的多模态理解任务。
-
每个子集的关键细节
- 文本基准:
- ARC:小学科学问答问题。
- BoolQ:来自搜索查询的是/否阅读理解问题。
- HellaSwag:常识自然语言推理和文本续写。
- PIQA:关于交互的物理常识推理。
- SIQA:关于社交互动和行为的常识推理。
- WinoGrande:代词解析的对抗性基准。
- 视觉基准:
- ChartQA 和 InfographicVQA:图表和信息图的视觉和逻辑推理。
- COCO-Captions:为日常图像生成描述性标题。
- DocVQA:文档页面图像上的视觉问答。
- MMMU:专家级多学科多模态评估。
- TextVQA:阅读和推理图像内的文本。
- 文本基准:
-
使用和 Processing
- 作者仅使用这些数据集进行评估,以衡量推理、常识和多模态理解能力。
- 本节未详细说明特定的训练划分、混合比例或裁剪策略,因为数据用作测试套件。
- 处理侧重于特定任务的输入,如基于基准定义的图像标题或问答对。
方法
作者引入了 Decoupled DiLoCo,这是一个分布式训练框架,旨在通过将单体 SPMD 集群分解为独立的、异步的学习者来演进先前专注于带宽的方法。该架构优先考虑可用性和分区容错性而非严格一致性,允许系统在存在硬件故障或落后节点的情况下,甚至在预训练规模下高效运行。
系统架构包含一个中央同步器以促进异步参数协调。如系统架构图所示,Learner 工作节点运行在具有高带宽内存(HBM)的加速器硬件(TPU)上,执行计算密集型的内部优化循环。相比之下,Syncer 运行在仅 CPU 资源和 RAM 上,管理全局模型参数并协调异步参数协调。这种分离确保 Syncer 具有最小的故障面,并且不会与训练工作负载竞争加速器资源。
请参阅框架图以了解学习者与 Syncer 之间的交互。在此设置中,即使 Learner Unit 2 停滞,Learner Unit 1 也会继续其训练循环。Syncer 聚合来自可用学习者的更新并将其广播回去,确保尽管个别组件发生故障,整体训练过程也不会停止。这种解耦隔离了硬件故障的影响范围,防止局部问题在整个集群中传播。
为了优化通信效率,模型权重被划分为片段。作者评估了几种分片策略,以平衡模型性能和系统带宽使用。层分片方法按 Transformer 层对权重进行分组,如果同步间隔超过层数,可能会导致突发通信模式。张量分片在单个张量级别对权重进行划分,允许更频繁的通信,但可能导致片段大小不均匀。为了解决这些问题,作者采用平衡张量分片。该策略使用贪心装箱算法将张量分布在片段上,使它们的总大小大致相等,确保一致的带宽使用并避免通信峰值。
训练过程涉及学习者的内部优化循环和 Syncer 的外部优化循环。学习者在本地数据分片上执行标准内部优化步骤(例如 AdamW)。定期地,它们将元数据和模型片段发送给 Syncer。Syncer 从法定人数的学习者聚合这些片段,应用外部优化器(例如带有 Nesterov 动量的 SGD),并广播更新后的参数。这种异步协调允许系统容忍落后节点和异构硬件速度。
通过分布式检查点和学习者恢复机制进一步增强鲁棒性。向量时钟用于跟踪系统的事件状态,通过 Chandy-Lamport 算法实现一致的分布式快照。当学习者失败或需要重新加入时,它可以从对等学习者获取模型状态的副本并与 Syncer 同步。此过程是异步的,不会阻塞系统的其余部分,允许动态调整活跃学习者的数量。
请参阅步进模式比较,以了解 Decoupled DiLoCo 与弹性数据并行训练的区别。虽然弹性数据并行训练在切片不可用或同步期间会停止,但 Decoupled DiLoCo 即使在某些学习者离线或恢复时也会继续步进。此功能允许框架即使在激进的硬件故障场景下也能保持高有效吞吐量和可用性。
最后,系统支持确定性重放以进行调试和分析。通过记录捕获事件状态、向量时钟和故障事件的事件磁带,无论底层硬件条件如何,都可以精确重现训练轨迹。这确保算法行为可以与系统噪声隔离,促进对框架弹性的严格评估。
实验
实验使用 Gemma 模型在文本和视觉数据上评估 Decoupled DiLoCo,以验证对硬件故障的弹性、对异构硬件的支持以及跨模型规模的可扩展性。该框架在模拟故障场景期间保持高系统有效吞吐量和正常运行时间,而标准数据并行训练会退化,且不牺牲下游模型质量。结果进一步证实,该方法无缝集成了机会性计算资源,并在密集和混合专家架构上匹配集中式基线。
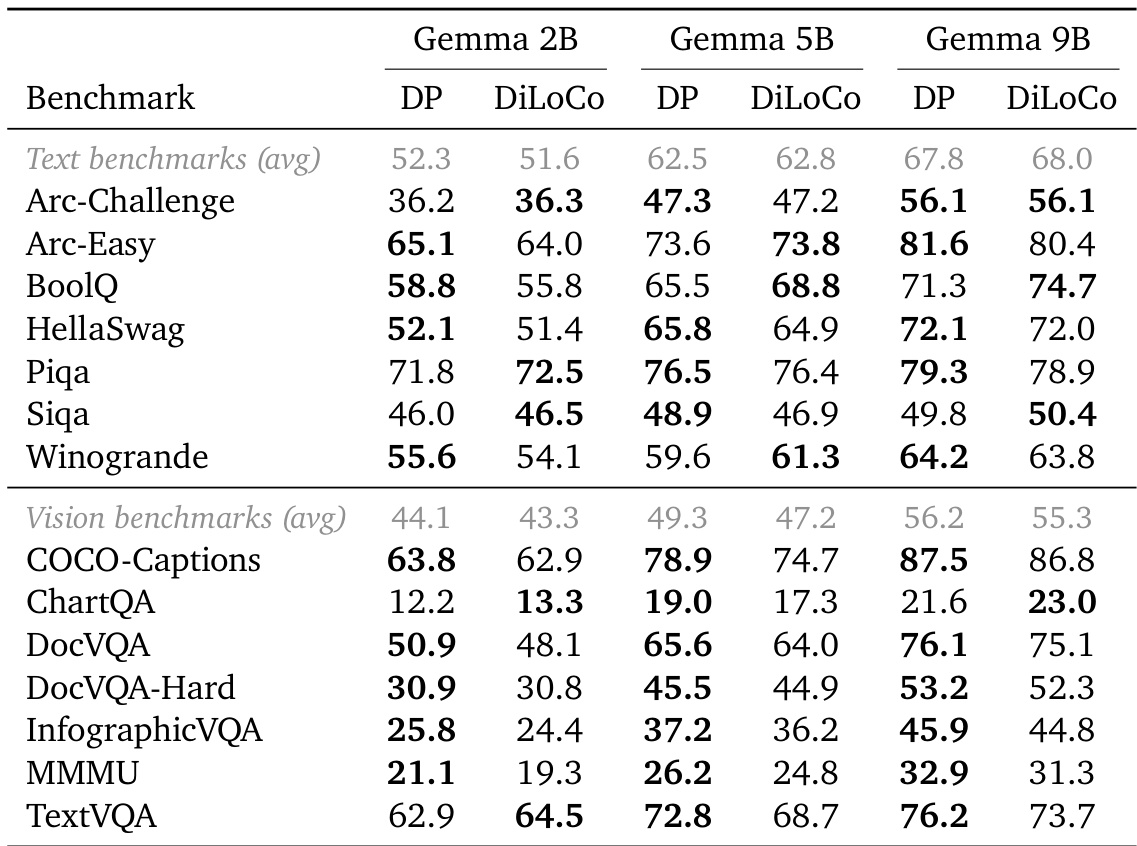
作者比较了 Decoupled DiLoCo 与标准数据并行训练在不同大小 Gemma 模型上的下游性能。结果表明,解耦框架在文本和视觉基准测试上实现了与集中式基线相当的性能。Decoupled DiLoCo 在所有模型大小上实现的文本基准平均值与数据并行训练相当。视觉基准结果表明,解耦和标准训练方法之间性能一致。具体任务得分在不同方法之间略有不同,但在较大规模下未观察到显著的性能差距。
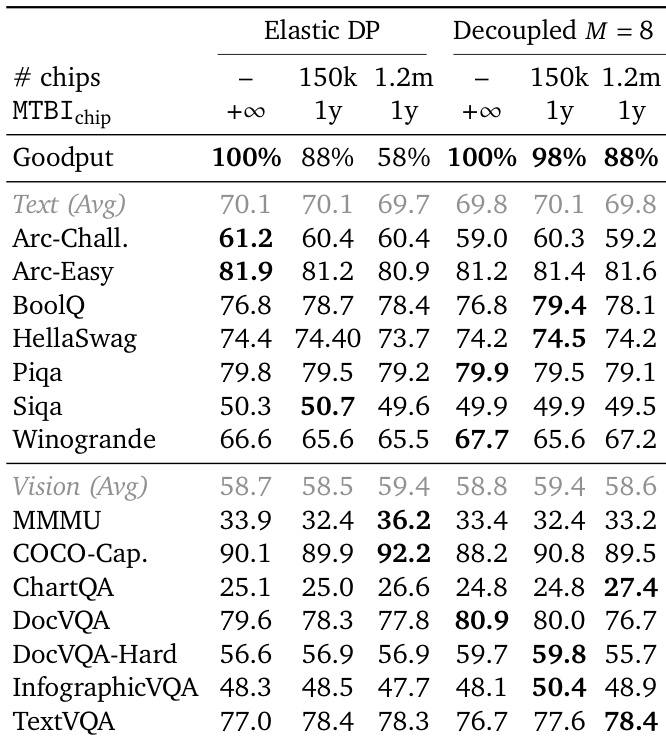
作者应用混沌工程原则来测试 Decoupled DiLoCo 框架对模拟硬件故障的弹性,并将其与标准弹性数据并行进行比较。结果表明,虽然标准弹性 DP 随着集群规模和故障率的增加而遭受有效吞吐量急剧下降,但 Decoupled 方法保持了一致的高效率。此外,文本和视觉基准上的下游模型性能保持稳健,并与无故障基线相当,表明该框架尽管存在重大硬件中断,仍保留了训练质量。Decoupled 训练在重度模拟故障率下维持高有效吞吐量,显著优于效率急剧下降的弹性 DP。文本和视觉任务上的下游评估指标在两种方法上保持稳定且具有竞争力,显示出对硬件中断的弹性。系统有效地掩盖了硬件故障,保持了与无故障标准训练运行相当的模型质量。
作者评估了不同的合并策略,具体比较了标准平均与模型参数和嵌入的径向方向平均(RDA)。结果表明,与标准平均方法相比,在模型合并操作中使用 RDA 在各种文本和视觉基准上始终产生更优越的性能。使用 RDA 进行合并和模型更新的配置在文本和视觉类别中均实现了最高的总体平均值。仅对合并操作应用 RDA 与基线平均方法相比,显著提高了 ARC-Challenge 和 COCO 等任务的性能。两个组件的标准平均在大多数评估指标上作为性能最低的基线。

实验比较了 Decoupled DiLoCo 与标准数据并行训练在不同计算可用性水平下的效率。结果表明,Decoupled DiLoCo 框架效率显著更高,在所有测试场景中均表现出比数据并行基线低得多的值。此外,对 Decoupled DiLoCo 方法应用 int4 通信压缩相比其未压缩版本产生了额外的效率增益。Decoupled DiLoCo 在所有计算利用率水平上均保持对数据并行训练的显著效率优势。使用 int4 通信压缩进一步降低了 Decoupled DiLoCo 的指标值,相比标准配置。随着计算利用率的增加,方法之间的效率差距持续存在并保持巨大。

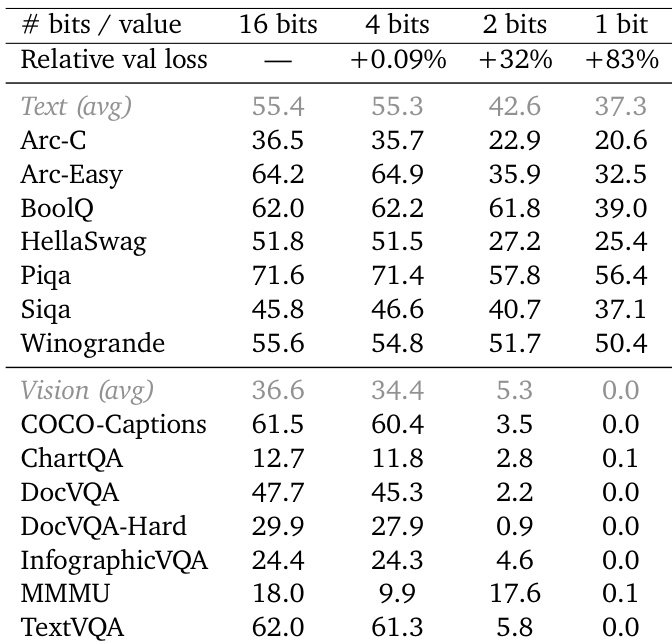
作者评估了将外部梯度压缩到较低位精度以减少训练期间带宽约束的影响。结果表明,压缩到 4 位保持了与 16 位基线相当的模型性能,而将精度降低到 2 位或 1 位会导致下游任务能力的显著下降。4 位压缩产生的性能与 16 位基线相当,验证损失增加最小。使用 2 位精度时,文本和视觉基准经历显著的性能下降。1 位压缩导致所有评估任务中的模型严重退化。
作者将 Decoupled DiLoCo 与标准数据并行训练进行了评估,表明在文本和视觉基准上具有相当的下游性能,同时对模拟硬件故障保持优越的弹性。进一步分析验证,采用径向方向平均进行合并和 4 位梯度压缩可在不牺牲模型质量的情况下优化效率。总的来说,这些实验证实该框架在不同计算条件和精度水平下实现了稳健的训练性能和显著的效率增益。