Command Palette
Search for a command to run...
面向长程任务的 LLM 决策与技能库 agents 协同演化研究
面向长程任务的 LLM 决策与技能库 agents 协同演化研究
Xiyang Wu Zongxia Li Guangyao Shi Alexander Duffy Tyler Marques Matthew Lyle Olson Tianyi Zhou Dinesh Manocha
摘要
长程交互式环境(Long horizon interactive environments)是评估 agent 技能使用能力的重要试验场。这些环境要求具备多步推理能力、能够在多个时间步内实现多种技能的链式调用,并在延迟奖励(delayed rewards)和部分可观测性(partial observability)的情况下做出稳健的决策。游戏是评估 agent 在环境中进行技能使用的理想试验场。大语言模型(LLMs)作为游戏 playing agents 提供了一种极具前景的替代方案,但由于缺乏跨回合(episodes)发现、保留和重用结构化技能的机制,它们往往难以维持一致的长程决策能力。我们提出了 COSPLAY,这是一个协同进化(co-evolution)框架。在该框架中,一个 LLM 决策 agent 从可学习的技能库(skill bank)中检索技能以指导动作执行;与此同时,一个由 agent 管理的技能流水线(skill pipeline)则从 agent 未标记的展开(unlabeled rollouts)中发现可重用的技能,从而构建技能库。我们的框架实现了双向提升:一方面改进了决策 agent,使其能够学习到更好的技能检索与动作生成能力;另一方面,技能库 agent 则持续提取、优化并更新技能及其对应的契约(contracts)。在六个游戏环境中的实验表明,使用 8B 基座模型的 COSPLAY 在单人游戏基准测试中,相比四种前沿 LLM 基线模型实现了超过 25.1% 的平均奖励提升,同时在多人社交推理游戏中也保持了竞争力。
一句话总结
所提出的 COS-PLAY 共演化框架通过将 LLM 决策 Agent 与一个由 Agent 管理的技能流水线相结合,增强了长程决策能力。该流水线能够从无标签的 rollout 中发现并精炼可重用的技能。使用 8B 基座模型在六个游戏环境中对比四个前沿 LLM 基线,实现了超过 25.1% 的平均奖励提升。
核心贡献
- 本文引入了 COS-PLAY,这是一个共演化框架,它将基于 LLM 的决策 Agent 与 Agent 管理的技能流水线集成,以实现无监督技能发现和持续精炼。
- 该框架利用双 Agent 系统:决策 Agent 从可学习的技能库中检索技能以指导动作,而技能库 Agent 则从无标签的 rollout 中提取、分割并更新可重用的技能及其契约(contracts)。
- 在六个多样化游戏环境中的实验表明,8B 基座模型在单人基准测试中相比四个前沿 LLM 基线实现了超过 25.1% 的平均奖励提升,同时在多人社交推理任务中保持了竞争力。
引言
在长程交互环境中,自主 Agent 必须掌握多步推理能力以及链接复杂行为的能力才能取得成功。虽然大语言模型 (LLMs) 在这些场景中展现出潜力,但由于缺乏在不同 episode 之间发现、存储和重用结构化技能的高效机制,它们往往难以实现一致的决策。现有方法通常依赖于人工策划的演示或固定的流水线,这无法让 Agent 进化自身的程序化知识。本文利用名为 COS-PLAY 的共演化框架来弥补这一差距。该系统采用双 Agent 架构,其中 LLM 决策 Agent 检索技能以指导动作,而独立的技能库 Agent 则从无标签的交互数据中自主发现并精炼可重用的技能。
数据集

通过在六个多样化的游戏环境中评估模型,这些环境被分为解谜、平台控制和多 Agent 社交推理三类。数据集和评估设置包括:
-
环境组成与观测:
- 2048: 一个在 4x4 网格上的单人滑块拼图游戏。Agent 接收文本渲染的棋盘,包括方块数值、分数和方向移动的前瞻信息。
- Candy Crush: 一个在 8x8 棋盘上的三消拼图游戏。观测内容包括基于文本的棋盘和当前有效的交换动作。
- Tetris: 一个在 10x20 棋盘上的方块堆叠游戏。Agent 接收 ASCII 棋盘、当前及即将出现的方块,以及堆叠高度和空洞等统计数据。
- Super Mario Bros.: 一个横版平台跳跃游戏。观测内容被转换为对 Mario 位置、附近物体和敌人的自然语言描述。
- Avalon: 一个五人社交推理游戏。状态以自然语言描述的形式提供,涵盖当前阶段、私人角色、任务进度和讨论历史。
- Diplomacy: 一个七人大型策略游戏。Agent 观测包括单位位置、供应中心数量和谈判历史在内的自然语言状态。
-
动作空间与处理:
- 所有观测内容均被转换为文本或自然语言状态描述。
- Agent 通过离散的文本动作进行交互。对于 Tetris,使用宏动作(macro actions)进行有效放置,而非原始控制。对于 Candy Crush,动作空间是动态的,由有效的坐标对交换组成。
-
任务约束与奖励:
- Episode 限制: 大多数环境都有特定的时长限制,例如 2048、Tetris 和 Super Mario Bros. 为 200 步,Candy Crush 为 50 步,Avalon 为 5 个任务,Diplomacy 为 20 个阶段。
- 奖励结构: 奖励根据每个任务量身定制,范围从合并分数、游戏积分到平台跳跃游戏中的进度信号,或社交推理与策略游戏中的胜利结果。
方法
COS-PLAY 框架作为一个共演化系统运行,其中决策 Agent 和技能库 Agent 通过迭代交互来提高交互环境中的长程决策能力。整体架构由两个主要组件组成:决策 Agent,通过原始动作和技能检索与游戏环境交互;以及技能库 Agent,通过处理轨迹在技能库中发现、精炼并维护结构化技能。在每个时间步,决策 Agent 观测当前环境状态,使用检索机制从技能库中检索相关的候选技能,根据检索到的技能更新内部意图状态,并根据观测、意图和当前激活的技能执行原始动作。这一过程生成一条 rollout 轨迹,随后将其输入技能库 Agent 进行精炼。技能库 Agent 通过四个阶段的流水线运行:边界提议(boundary proposal)、分割推理(segmentation inference)、契约学习(contract learning)和技能库维护(skill bank maintenance)。边界提议利用局部信号(如谓词翻转、意图变化、奖励激增和动作执行模式)来识别潜在的技能转换点。随后,分割模块处理这些候选边界,根据观测效果与已学习契约的一致性,为每个片段标记现有技能或新技能。契约学习聚合同一技能在不同实例中的状态变化,形成一个捕捉可靠状态转换的经验证的效果契约,进而用于指导分割并提高技能库质量。最后的维护阶段通过精炼、实例化、合并、拆分和退役操作来更新技能库,确保其保持紧凑、稳定并与不断演化的决策策略保持一致。  两个 Agent 使用 GRPO 结合独立的 LoRA 适配器进行联合训练,使决策 Agent 能够学习技能检索和动作执行,同时使技能库 Agent 学习分割轨迹、验证契约并维护技能库。这种闭环共演化确保了技能质量的提升能够增强决策能力,而更好的 rollout 则能改进技能发现,从而创建一个自我强化的学习系统。
两个 Agent 使用 GRPO 结合独立的 LoRA 适配器进行联合训练,使决策 Agent 能够学习技能检索和动作执行,同时使技能库 Agent 学习分割轨迹、验证契约并维护技能库。这种闭环共演化确保了技能质量的提升能够增强决策能力,而更好的 rollout 则能改进技能发现,从而创建一个自我强化的学习系统。
实验
该框架在六个多样化的环境中进行了评估,包括单人拼图游戏和复杂的多人社交推理游戏(如 Avalon 和 Diplomacy)。实验验证了共演化训练方法使小模型能够实现高数据效率和强大的跨领域适应性,其性能可匹配或超过规模大得多的前沿 LLM。定性分析表明,学习到的技能库提供了必要的时序结构和可重用的策略模式,这防止了长程任务中的灾难性失败,并维持了通用推理能力。
通过在游戏环境上将 COS-PLAY 与基线模型进行对比,结果显示完整的 COS-PLAY 框架获得了比 GPT-5.4 和合并 LoRA 变体更高的奖励。结果表明,完整模型优于基座 Qwen3-8B 和合并 LoRA 版本,这说明共演化训练和专门的 LoRA 适配器有助于提升性能。COS-PLAY 的奖励高于 GPT-5.4 和合并 LoRA 变体。完整的 COS-PLAY 模型优于基座 Qwen3-8B 和合并 LoRA 版本。性能的提升表明了共演化训练和专门 LoRA 适配器的重要性。
通过在系列单人及多人游戏环境中评估 COS-PLAY,并将其性能与多个前沿 LLM 进行对比,结果显示 COS-PLAY 在单人游戏中相比基线模型实现了显著提升,并在多人社交推理任务中与最先进的模型保持竞争力,展示了有效的 few-shot 适应能力和技能重用性。框架的性能归功于决策 Agent 与学习可重用、结构化抽象的技能库的共演化,从而实现了鲁棒的长程推理。COS-PLAY 在单人游戏中相比基线模型实现了显著的平均提升,并在多人社交推理任务中匹配或超过了前沿 LLM。该框架展示了有效的 few-shot 适应性,与以往方法相比,仅需极少的训练迭代即可达到强大的性能。COS-PLAY 学习到的可重用技能抽象提供了安全底线并提高了动作多样性,从而在长程社交游戏中实现鲁棒表现。
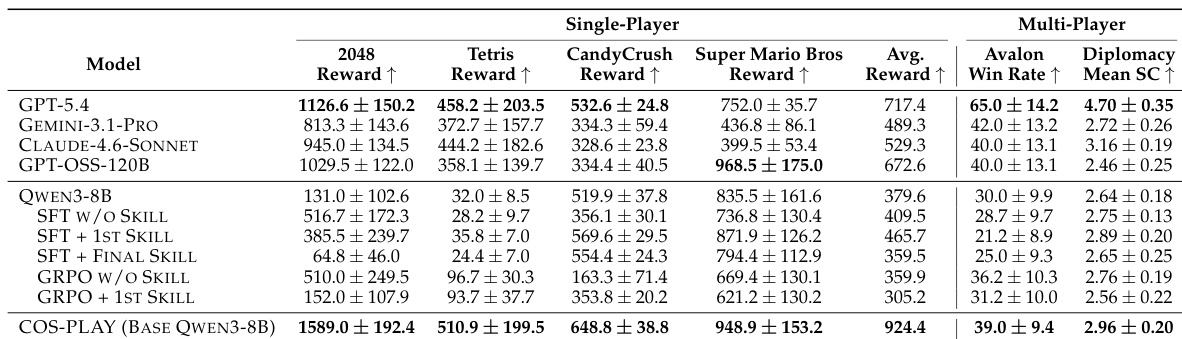
在通用推理基准测试中将 COS-PLAY 与基座模型进行对比,结果显示适配后的模型在保持接近原始模型性能的同时,取得了强大的游戏表现。结果表明,适配过程以极小的退化保留了通用推理能力,这表明尽管在游戏环境中进行了专门化,但该方法并未损害广泛的认知技能。COS-PLAY 在通用推理基准测试中保持了接近基座模型的性能;适配过程导致通用推理能力的退化极小;COS-PLAY 在提升游戏特定性能的同时保留了基座模型的推理能力。

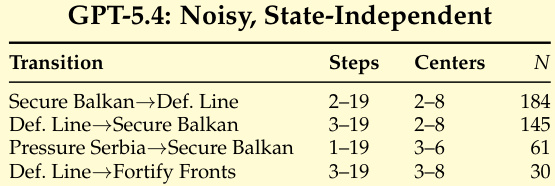
{"summary": "通过分析 Diplomacy 中的技能转换,展示了不同的技能类别如何在游戏过程中的特定步骤和中心数量下被触发。表格说明某些转换,例如从 Secure Balkan 到 Def. Line 以及从 Pressure Serbia 到 Secure Balkan,发生在定义的游戏步骤和供应中心范围内,表明这是一个结构化的、基于阶段的决策过程。这些模式表明技能被用于施加时序结构并指导动作选择,且某些转换比其他转换更为频繁。", "highlights": ["Diplomacy 中的技能转换在特定的游戏步骤和供应中心范围内触发,表明了一个结构化的决策过程。", "某些转换(如 Secure Balkan 到 Def. Line 和 Pressure Serbia 到 Secure Balkan)频繁发生,表明其在游戏中的重要性。", "技能的使用施加了时序结构,有助于指导动作选择并防止策略停滞。"]}
通过对比成功和失败的 episode 来分析 Diplomacy 中的失败模式,发现成功的运行表现出多样化的动作和结构化的技能转换,而失败则以重复动作和缺乏策略变化为特征。分析强调,技能转换和动作多样性对于避免停滞和实现有效游戏至关重要,该框架提供了一种支持探索并防止崩溃的时序结构。成功的 episode 显示出多样化的动作和结构化的技能转换,而失败则以高动作重复率和缺乏变化为标志。该框架通过强制执行维持安全底线的时序结构来防止崩溃,即使在动作选择较差的情况下也是如此。技能转换施加了一种课程表(curriculum schedule),从而拓宽了动作探索并避免了停滞。

通过在单人及多人游戏环境、通用推理基准测试以及 Diplomacy 的特定游戏分析中评估 COS-PLAY 框架,结果证明,将决策 Agent 与专门的技能库进行共演化,能够在保留基座模型通用认知能力的同时,实现卓越的游戏表现和鲁棒的长程推理。此外,定性分析表明,学习到的技能抽象提供了必要的时序结构,从而促进了动作多样性并防止了策略停滞。