Command Palette
Search for a command to run...
DeVI:通过合成视频模仿实现基于物理的灵巧人机交互
DeVI:通过合成视频模仿实现基于物理的灵巧人机交互
Hyeonwoo Kim Jeonghwan Kim Kyungwon Cho Hanbyul Joo
摘要
视频生成模型的最新进展使得在广泛的场景和物体类别中合成逼真的“人-物交互”(Human-Object Interaction, HOI)视频成为可能,其中包括难以通过动作捕捉系统获取的复杂灵巧操作。虽然这些合成视频中蕴含的丰富交互知识在灵巧机器人操作的运动规划方面具有巨大潜力,但其有限的物理保真度和纯 2D 的特性,使得它们难以直接作为基于物理的角色控制(physics-based character control)中的模仿目标。我们提出了 DeVI(Dexterous Video Imitation),这是一个全新的框架,利用文本条件的合成视频,实现与未见过的目标物体进行符合物理逻辑的灵巧 agent 控制。为了克服生成式 2D 线索的不精确性,我们引入了一种混合追踪奖励机制,该机制集成了 3D 人体追踪与鲁棒的 2D 物体追踪。与依赖高质量 3D 运动学演示的方法不同,DeVI 仅需生成的视频,从而实现了跨多样化物体和交互类型的零样本(zero-shot)泛化。广泛的实验表明,DeVI 的表现优于现有的模仿 3D 人-物交互演示的方法,尤其是在建模灵巧的手-物交互方面。我们进一步验证了 DeVI 在多物体场景和文本驱动动作多样性方面的有效性,展示了将视频作为具有 HOI 感知能力的运动规划器的优势。
一句话总结
DeVI 框架通过一种结合了 3D 人体追踪与鲁棒 2D 物体追踪的混合追踪奖励,模仿以文本为条件的合成视频,从而实现物理上合理的灵巧机器人操控。与依赖 3D 运动学演示的现有方法相比,该框架在多种物体上实现了卓越的 zero-shot 泛化能力。
核心贡献
- 本文引入了 DeVI,这是一个利用视频扩散模型作为运动规划器的框架,能够在不需要高质量 3D 运动捕捉数据的情况下,在物理仿真中实现物理上合理的灵巧人机交互。
- 该工作提出了一种混合追踪奖励系统,将 3D 人体追踪与鲁棒的 2D 物体追踪以及视觉 HOI 对齐相结合,从而在无需 6D 物体位姿估计的情况下重建与物体对齐的运动。
- 大量实验表明,该方法在多种物体上实现了 zero-shot 泛化,并且在建模复杂的灵巧手物交互方面优于依赖 3D 运动学演示的现有方法。
引言
在物理仿真中实现真实的灵巧人机交互 (HOI) 对于训练 robotic agent 执行抓取或功能性操控等复杂任务至关重要。虽然视频生成模型可以合成多样的交互场景,但它们生成的 2D 内容缺乏在物理引擎中进行直接模仿所需的物理保真度和 3D 深度。现有的模仿方法通常依赖于高质量的 3D 运动捕捉数据,这很难扩展到多种物体和复杂的动作中。本文提出了 DeVI,这是一个使用以文本为条件的合成视频作为交互感知运动规划器的框架。通过引入结合 3D 人体追踪与鲁棒 2D 物体追踪的混合追踪奖励,克服了 2D 生成线索的不精确性,从而在不需要 3D 演示的情况下实现了灵巧操控的 zero-shot 泛化。
方法
DeVI (Dexterous Video Imitation) 框架旨在学习一种类人控制策略,使仿真角色能够从 2D 视频输入中模仿复杂的人机交互 (HOI)。整个过程始于 3D 场景初始化,其中由 SMPL-X 模型参数化的人体和目标物体被放置在桌面环境中。为了增强视频合成的真实感,SMPL-X 网格被替换为来自 THuman2.0 数据集的纹理人体网格,并通过线性混合蒙皮进行变形,以匹配初始 SMPL-X 模型的姿态。随后,从一组预定义的相机视角对该纹理场景进行渲染,生成 2D 图像,作为视频生成的起点。
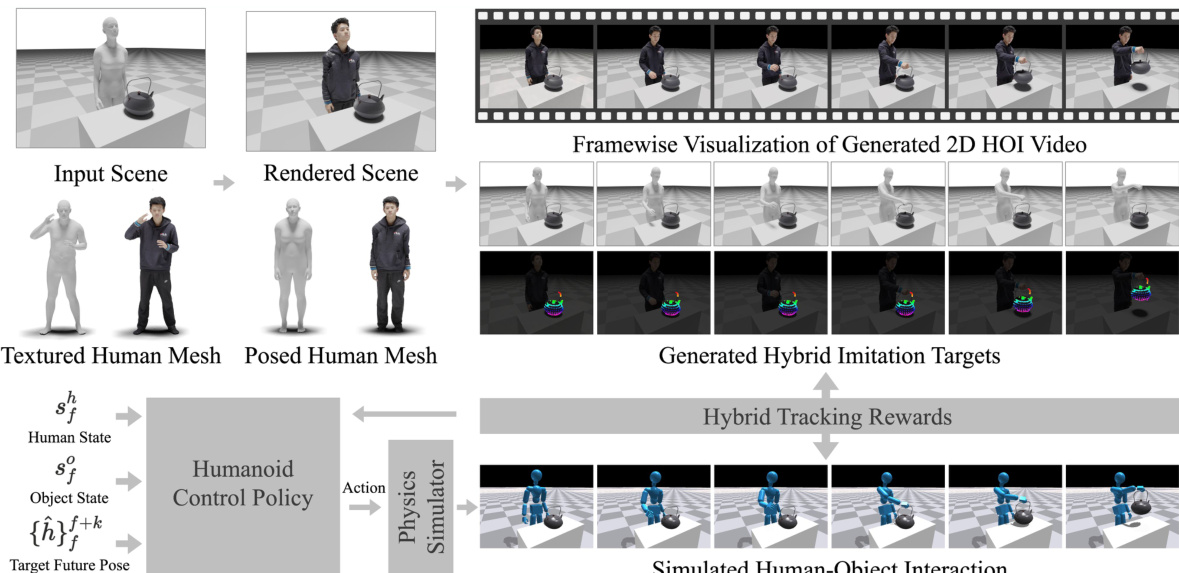
如下图所示,渲染的场景被用于使用预训练的视频扩散模型生成 2D HOI 视频。该视频以描述所需交互的文本提示为条件,包含了提取混合模仿目标所需的视觉信息。该方法的目标是学习一种能够复制视频中所观察到的运动的策略,即使在原始 3D 运动捕捉数据不可用的情况下也是如此。

混合模仿目标从生成的 2D 视频中提取。对于人体部分,应用现成的单目运动估计器来恢复 3D SMPL-X 人体运动序列。初始重建通过视觉 HOI 对齐优化过程进行细化,该过程将估计的人体姿态与视频中的 2D 投影以及初始 3D 物体状态进行联合对齐。这种对齐涉及最小化一个复合损失函数,其中包括身体和手部关节的 2D 投影损失、时间一致性损失,以及用于强制人体与物体接触的单侧 Chamfer 距离损失。对于物体部分,通过使用视频追踪器在视频帧中追踪可见的物体顶点来构建 2D 轨迹,从而提供 2D 物体参考。
类人控制策略 πθ 被训练用于追踪这些混合目标。该策略的输入为当前角色状态 st(包含人体和物体状态)以及目标向量 gt,后者被定义为 3D 人体运动参考的未来 k 个实体。学习目标是最大化期望折扣累积奖励 J(θ),并使用近端策略优化 (PPO) 进行优化。奖励函数被设计为三个部分的乘积:人体追踪奖励 (Rh)、物体追踪奖励 (Ro) 和接触奖励 (Rcontact)。
人体追踪奖励鼓励仿真角色匹配 3D 人体运动参考,结合了关节位置、速度和旋转差异,以及用于实现平滑且物理合理的动作的功率惩罚。物体追踪奖励 Ro 被定义为仿真物体 2D 投影与从视频中提取的 2D 物体轨迹之间负平方误差的指数函数。接触奖励 Rcontact 是接触力奖励与接触距离奖励的乘积。它由二进制接触标签 ψt 进行调节,该标签通过分析物体顶点和手部关节的运动来推断接触时机,从而从视频中自动估计。
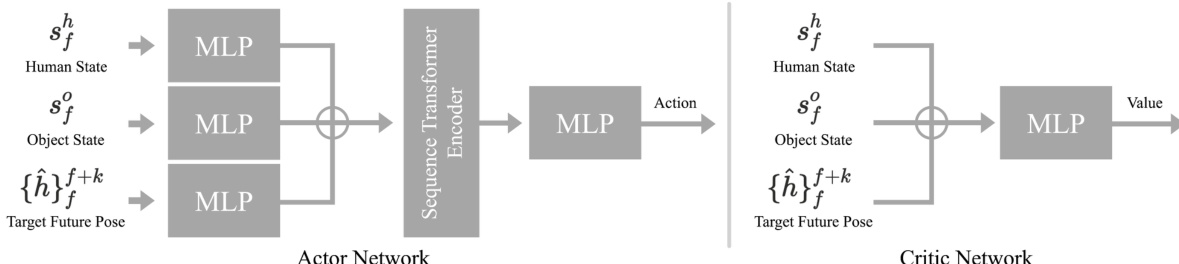
控制策略的 actor-critic 网络架构如下图所示。输出动作的 actor 网络由针对人体状态、物体状态和目标未来姿态的独立多层感知器 (MLP) 组成。这些表示被拼接在一起,并通过序列 transformer 编码器进行联合编码,随后通过多层 MLP 生成动作。估计价值函数的 critic 网络采用相同的输入,将其拼接并传递通过多层 MLP。策略通过使用 PPO 算法更新 actor 和 critic 网络进行训练,并由混合追踪奖励引导学习过程。
实验
研究人员通过使用 GRAB 数据集和多种合成视频场景,将 DeVI 模仿灵巧人机交互的能力与最先进的 3D 运动模仿基准进行比较,从而对其进行评估。实验验证了所提出的混合模仿目标和视觉 HOI 对齐有效地弥合了 2D 视频线索与 3D 基于物理控制之间的差距。结果表明,该框架实现了比依赖复杂 6D 位姿的方法更高的运动精度和成功率,同时也表现出强大的文本可控性和对多物体场景的泛化能力。
通过使用多个指标的成功率,将该方法与基准进行对比评估,结果显示该方法在模仿人机交互运动方面实现了更高的成功率。结果表明,所提出的方法在人体和物体追踪精度方面均优于基准,特别是在放宽阈值的情况下。即使使用 2D 物体轨迹而非 6D 位姿,该方法仍表现出鲁棒的性能,突显了混合模仿目标的有效性。DeVI 在所有评估指标和阈值下均实现了比基准更高的成功率。该方法在人体和物体追踪精度方面均优于基准,尤其是在放宽约束的情况下。DeVI 使用 2D 物体轨迹表现出鲁棒的性能,证明了混合模仿目标的有效性。
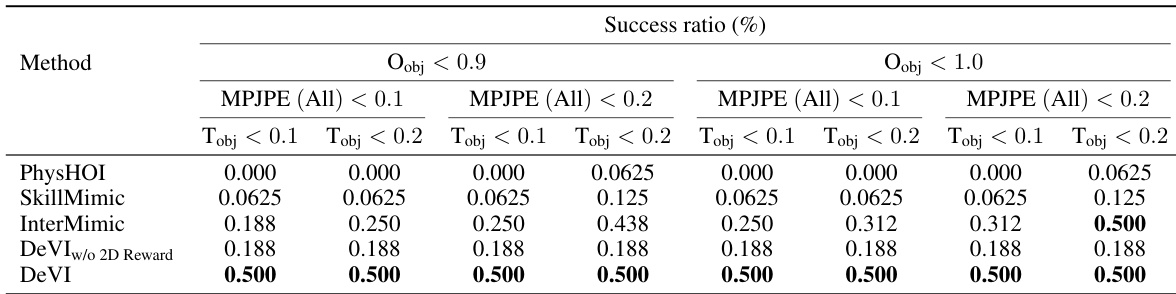
在涉及人机交互的数据集上,使用人体和物体运动精度指标将 DeVI 与多个基准进行对比。结果显示,DeVI 在人体运动追踪和物体轨迹方面实现了更低的误差,特别是在手部和根部关节位置,并在成功率方面优于基准。消融研究确认了视觉 HOI 对齐对于准确的手物交互的重要性,并证明与 6D 位姿追踪相比,使用 2D 物体轨迹作为奖励是有效的。DeVI 在人体运动追踪和物体轨迹精度方面优于基准,特别是对于手部和根部关节位置。视觉 HOI 对齐显著改善了人体运动与视频帧及 3D 物体的对齐程度,增强了交互的真实感。使用 2D 物体轨迹作为奖励比 6D 位姿追踪带来更好的性能,表明这是一种更有效且实用的模仿方法。
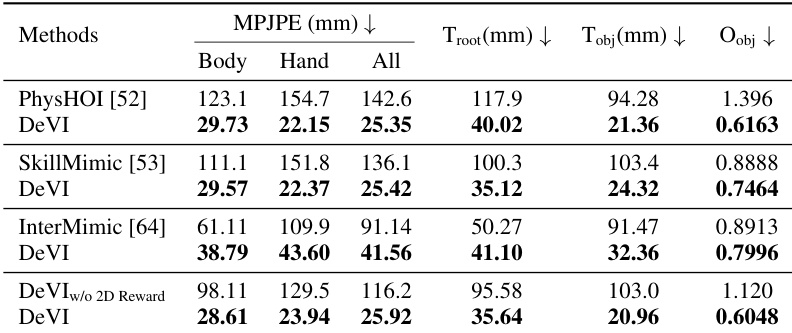
通过比较包含和不包含对齐组件的结果,评估了框架中视觉 HOI 对齐的有效性。结果表明,结合视觉 HOI 对齐显著改善了生成的 3D 人体运动与输入视频之间的对齐程度,特别是对于手部关节,并提高了手物交互的准确性。与没有对齐的基准相比,该方法在人体姿态追踪方面实现了更低的误差,并具有更好的物体接触精度。视觉 HOI 对齐改善了 3D 人体运动与输入视频的对齐,特别是手部关节。带有视觉 HOI 对齐的方法实现了更好的接触精度,并减少了交互过程中手与物体之间的距离。结合视觉 HOI 对齐使得仿真运动中的手物交互更加准确且合理。
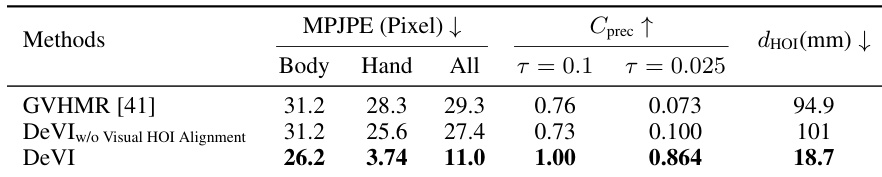
使用人体和物体运动精度指标将 DeVI 与多个基准进行对比,以验证其模仿人机交互的能力。结果表明,DeVI 实现了卓越的追踪精度和更高的成功率,特别是在手部和根部关节定位方面。消融研究进一步确认,视觉 HOI 对齐显著增强了交互的真实感和接触精度,而使用 2D 物体轨迹则提供了一个鲁棒且有效的模仿目标。