Command Palette
Search for a command to run...
LLaDA2.0-Uni:通过扩散大语言模型统一多模态理解与生成
LLaDA2.0-Uni:通过扩散大语言模型统一多模态理解与生成
摘要
我们提出了 LLaDA2.0-Uni,这是一个统一的离散扩散大语言模型(dLLM),能够在原生集成的框架内支持多模态理解与生成。其架构结合了全语义离散 tokenizer、基于 MoE 的 dLLM 骨干网络以及扩散解码器(diffusion decoder)。通过利用 SigLIP-VQ 将连续视觉输入离散化,该模型能够在骨干网络内对文本和视觉输入实现块级掩码扩散(block-level masked diffusion),同时由解码器将视觉 tokens 重构为高保真图像。通过在骨干网络中引入前缀感知(prefix-aware)优化,并在解码器中采用少步蒸馏(few-step distillation)技术,模型的推理效率在并行解码的基础上得到了进一步提升。得益于精心策划的大规模数据和定制化的多阶段训练流水线,LLaDA2.0-Uni 在多模态理解方面能够媲美专门的视觉语言模型(VLM),同时在图像生成与编辑方面表现出强大的性能。其对交错式生成与推理(interleaved generation and reasoning)的原生支持,为下一代统一基座模型建立了一种具有前景且可扩展的范式。代码和模型已发布于:https://github.com/inclusionAI/LLaDA2.0-Uni。
一句话总结
LLaDA2.0-Uni 是一个统一的离散扩散大语言模型,通过结合基于 MoE 的 backbone 和扩散 decoder,将多模态理解与生成集成在单一框架内,利用 SigLIP-VQ 进行视觉离散化,并采用块级掩码扩散(block-level masked diffusion)来实现交错推理与高保真图像合成。
核心贡献
- 本文介绍了 LLaDA2.0-Uni,这是一种统一架构,集成了全语义 tokenizer、16B MoE 离散大语言模型 backbone 以及扩散 decoder,通过共享的块级掩码预测目标实现多模态理解与生成。
- 该方法通过使用 SigLIP-VQ tokenizer 将视觉输入映射为语义丰富的离散 tokens,使得文本和图像能够在单一共享空间内进行建模,从而实现交错生成与推理。
- 该框架通过将 backbone 中的前缀感知优化与 decoder 中的少步蒸馏相结合,提升了推理效率,在多模态理解、图像生成和编辑基准测试中均取得了强劲性能。
引言
多模态模型旨在弥合视觉理解与图像生成之间的鸿沟,以实现更高效的部署和更先进的推理能力。虽然目前的统一模型通常依赖自回归架构或混合范式,但现有的掩码扩散方法在语义理解能力差、因过度压缩导致视觉质量损失以及文本建模不可靠等方面面临挑战。通过利用 16B Mixture-of-Experts 扩散大语言模型 (dLLM) backbone,LLaDA2.0-Uni 被提出,该框架通过共享的块级掩码扩散目标统一了两种模态。通过利用新型 SigLIP-VQ tokenizer 将视觉输入转换为离散语义 tokens,LLaDA2.0-Uni 在保持理解和生成基准测试高性能的同时,实现了无缝的交错生成与推理。
数据集
通过使用多种数据集,模型在多个专业能力方面进行了训练:
- 多模态理解:预训练涉及来自开源渠道的大量图像描述数据,并辅以专门的子集。这包括通过使用 PaddleOCR 和 Qwen3-VL 的由粗到精流水线生成的 OCR 数据,以及源自 Objects365 和 RefCOCO 的 grounding 和计数数据。对于后者,通过 Qwen3-VL-235B-A22B 进行检测置信度过滤和验证,并将坐标归一化到 [0, 1000] 范围。SFT 数据包含 6000 万个样本,其中纯文本与多模态数据的比例为 1:5,涵盖了 VQA 和数学推理等各种任务。质量通过一个两阶段流水线进行维护,该流水线使用 Qwen3-VL 进行查询审计,并使用 GPT-OSS 进行响应语义过滤。
- 图像生成:收集了超过 2 亿张网络图像,特别增加了包含人体和渲染文本的图像比例。通过三个阶段的清洗过程,针对分辨率(最小 512 像素)、压缩级别、美学(ArtiMuse 分数 > 60)和质量(DeQA-Score > 4.0)进行过滤,最终获得 1.4 亿张高质量图像。描述由 Qwen3-VL-235B-22B 生成,并结合了具有信息量的原始网络文本以确保描述的准确性。
- 图像编辑:该子集结合了多个开源数据集以及从生成数据集中创建的合成对。使用 Qwen3-VL-235B-22B 来精炼指令,并过滤掉编辑产生伪影或无明显变化的失败样本。
- 交错数据:从 Koala36M 视频语料库中构建交错序列。过滤标准包括时长(10 到 30 秒)、美学分数(> 4.0)、清晰度(> 0.7)和运动分数(> 4)。该过程保留了 600 万个片段,从中每 5 秒采样一帧以创建 2 到 6 帧的序列。随后使用 Qwen3-VL-235B-A22B 生成关于动作和场景变化的详细描述。
- 推理增强数据:为了支持思维链能力,引入了来自 Flux-6M、Zebra-CoT 和 Weave 的约 800 万个 SFT 样本。这些数据侧重于基于推理的图像生成和交错推理。
方法
LLaDA2.0-Uni 的架构被设计为一个用于多模态理解与生成的统一框架,构建在集成离散 tokenizer、扩散语言模型 backbone 和扩散 decoder 的核心流水线之上。这种设计使得使用共享的离散 token 表示可以对理解和合成任务进行端到端训练与推理。模型通过模块化框架处理输入,视觉数据首先被转换为语义 tokens,在多模态语言模型中进行处理,然后重建为高保真图像。
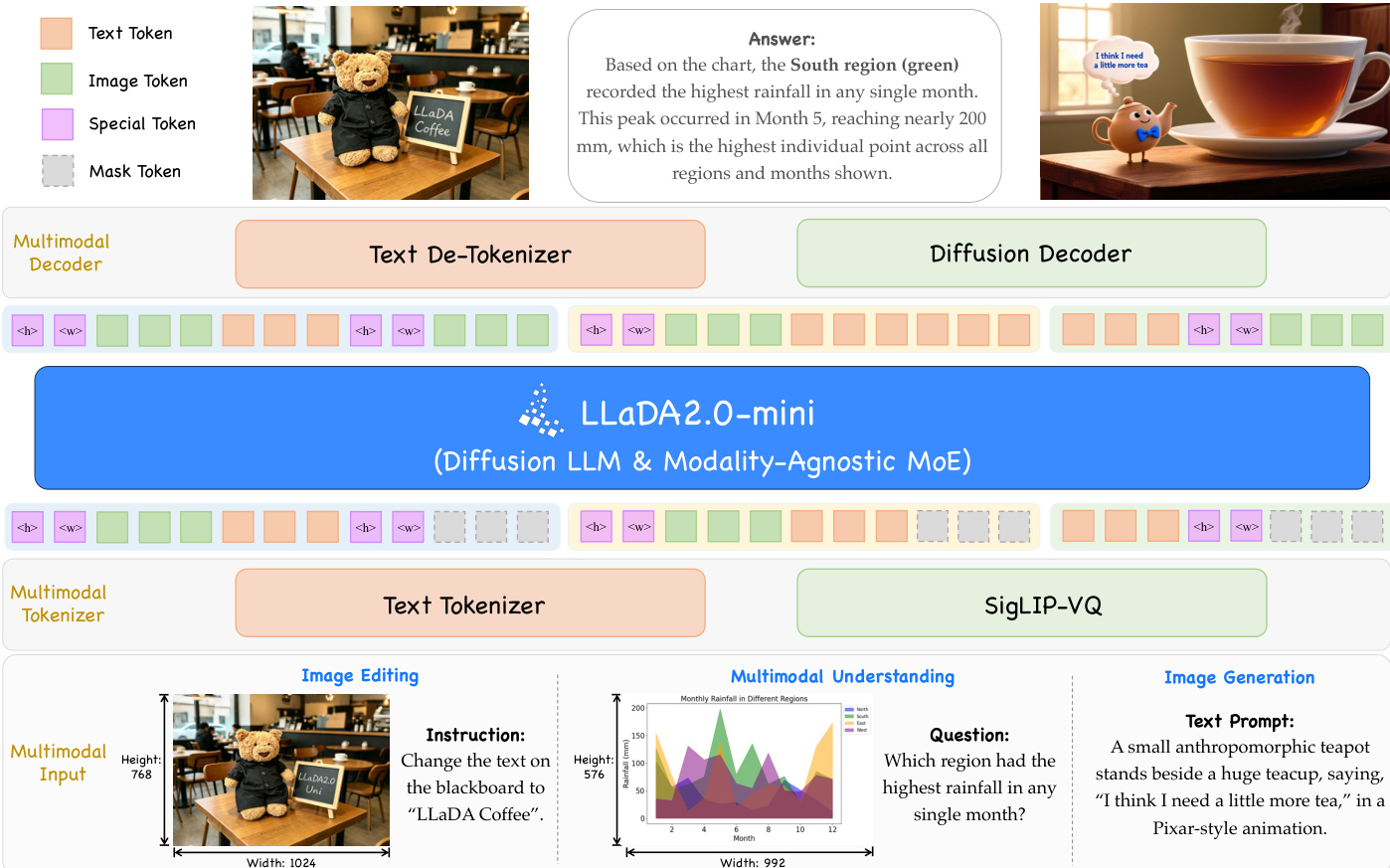
该过程始于 SigLIP-VQ tokenizer,它将连续的图像输入转换为离散的语义 tokens。该 tokenizer 利用预训练的 SigLIP2-g ViT 作为视觉特征提取器,随后使用向量量化器将特征映射到词表大小为 16,384、维度为 2,048 的 codebook 中。与基于重建的 VQ-VAE 不同,SigLIP-VQ 直接在理解任务上进行训练,优先考虑语义保真度而非像素级准确度。这产生了一种非常适合多模态推理但缺乏原生图像重建机制的 token 表示。为了解决这一局限性,采用了定制的扩散 decoder,它在离散 token 序列上运行以生成高分辨率图像。通过在展平的 1D 视觉序列中加入特殊的 <height> 和 <width> tokens,支持了 tokenizer 处理任意分辨率的能力,使模型无需修改架构即可处理不同维度的图像。
核心处理单元是一个 16B Mixture-of-Experts (MoE) 扩散语言模型,构建在 LLaDA-2.0-mini 架构之上。该 backbone 设计用于在统一的掩码预测目标下处理文本和视觉 tokens。为了集成视觉信息,模型的词表进行了扩展,包含了来自 SigLIP-VQ codebook 的 tokens,以及用于生成和理解的自定义特殊 tokens。输入嵌入层保留了预训练的语言嵌入,同时随机初始化新的视觉 token 嵌入。最终的预测头也进行了扩展以适应更大的词表,其中语言特定部分从预训练权重初始化以保留语言能力。为了确保训练的稳定性和效率,模型采用了块级注意力方案,该方案将注意力限制在预定义的块内,并选择性地在块之间启用。这种方法在保持全注意力模型并行解码速度的同时,减轻了由 SigLIP-VQ tokens 引入的自回归偏差。模型使用 1D Rotary Position Embedding (RoPE) 进行位置编码,2D 空间信息通过前述的 <height> 和 <width> tokens 进行编码。
扩散 decoder 是一个构建在 Z-Image-Base 之上的 6B 文本到图像模型,它将 dLLM 生成的离散视觉 tokens 作为调节信号。这不同于现有将文本提示与视觉 tokens 冗余结合的方法。Decoder 执行 2× 超分辨率,仅使用上采样后的语义 tokens 作为唯一的调节输入。为了降低标准 50 步采样过程的计算成本,decoder 采用了轻量级的基于一致性的蒸馏框架。该方法引入了一个双输出网络,同时预测标准速度场和一致性项。蒸馏目标结合了流匹配损失与一致性损失,在保持高图像质量的同时,实现了 8 步 CFG-free 推理。该蒸馏过程以三阶段方式进行训练:建立跨模态对齐的预热阶段,提高鲁棒性的多领域泛化阶段,以及增强美学细节的高保真精炼阶段。
训练流水线由三个不同的阶段组成,以逐步构建模型能力。第一阶段是视觉-语言对齐,侧重于使用高质量的图像-描述对和视觉知识数据集在 dLLM backbone 内对齐视觉和语言表示。采用渐进式任意分辨率方案来处理长视觉序列,生成任务从 256×256 开始,理解任务使用 800×800。第二阶段是多任务预训练,通过在多样化的多模态数据上进行训练来扩展模型能力,包括图像-文本交错数据、OCR、视觉计数以及图像编辑和风格迁移等各种生成任务。最后一个阶段是监督微调 (SFT),分为两个阶段进行:初始的 8k 上下文长度阶段用于指令遵循,随后的 16k 上下文长度阶段用于复杂的视觉推理和生成。

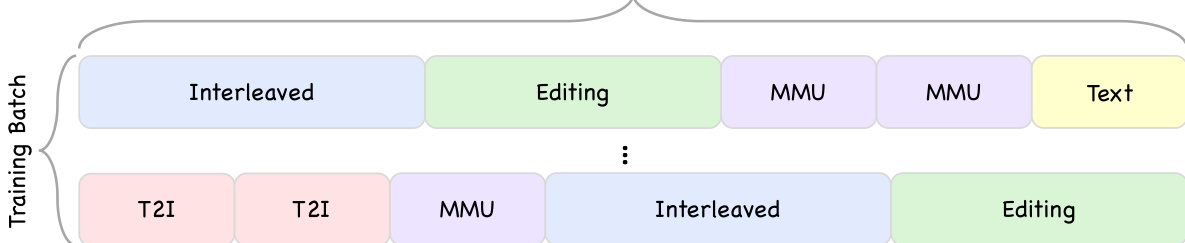
通过几种关键策略实现了训练优化。模型使用块扩散语言模型 (BDLM) 目标,该目标在块级掩码区域上运行,以在保持连贯上下文的同时实现并行解码。在 MoE 模型中,负载均衡对于防止专家崩溃至关重要,因此采用了无辅助损失机制,通过根据当前与理想专家负载之间的差异更新偏差项来促进均匀的工作负载分布。对于 SFT,引入了掩码 token 重加权损失来处理变长序列,其中损失根据每个样本中掩码 tokens 数量的平方根倒数进行加权,以平衡梯度贡献。此外还采用了互补掩码技术,通过从单个序列构建两个对立的训练实例来提高数据效率,确保每个 token 位置在每对样本中恰好出现一次未损坏的状态。通过离线预提取图像 tokens 消除了重复的编码器传递,并使用数据打包策略将多个较短样本连接成固定长度的序列,以最小化填充并提高 GPU 利用率,从而进一步提升了模型的训练效率。
实验
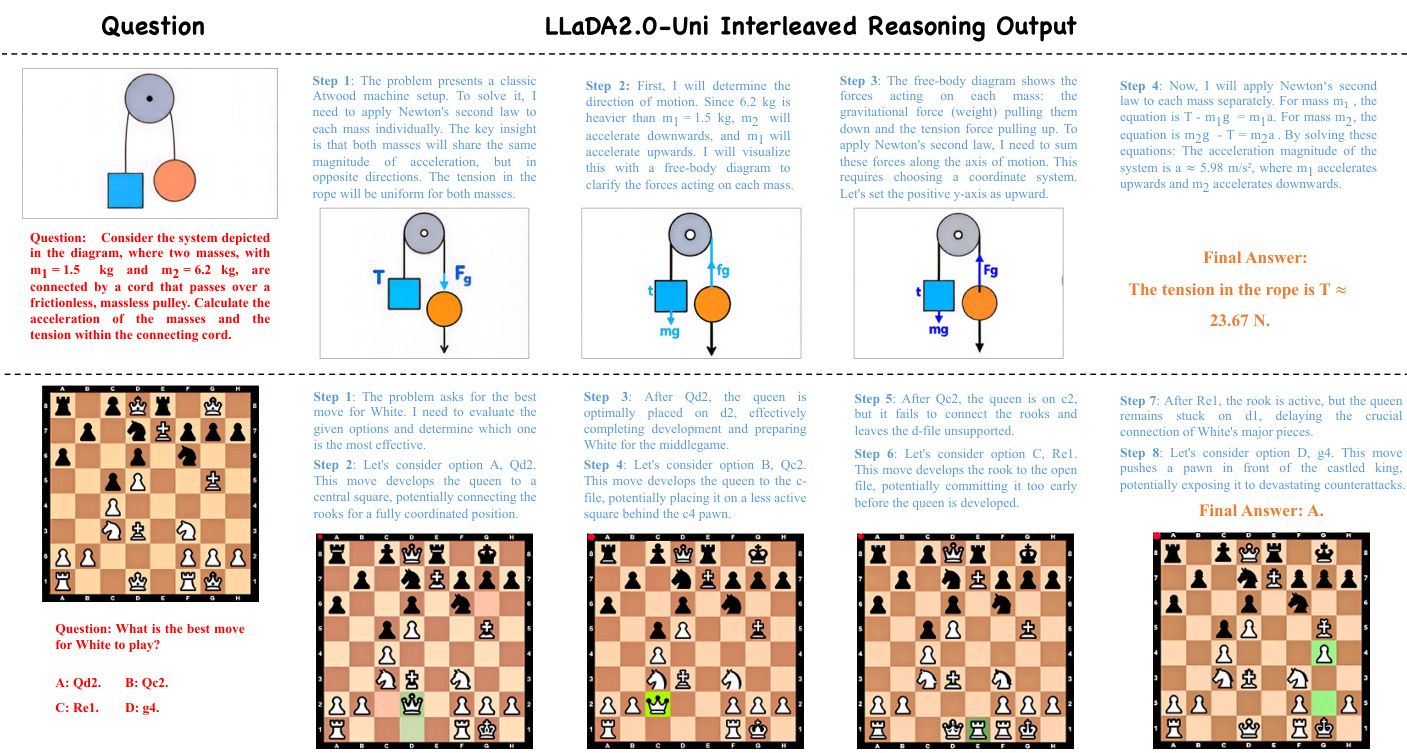
LLaDA2.0-Uni 在广泛的基准测试中进行了评估,以验证其多模态理解、文本到图像生成、基于指令的图像编辑以及交错生成能力。结果表明,该模型有效地缩小了统一架构与专业模型之间的差距,在推理、OCR 和组合图像生成方面的性能达到了顶尖专家水平。此外,该模型在多区域文本渲染和交错推理等复杂任务中表现出强大的能力,同时通过加速解码方法保持了高视觉质量。
表格概述了 LLaDA2.0-Uni 的训练阶段和目标,详细说明了从视觉-语言对齐到监督微调的过程。它突出了不同阶段的关键训练参数,如数据类型、分辨率、token 数量和序列长度,强调了模型在理解和生成能力方面的进展。LLaDA2.0-Uni 经历了三个阶段:视觉-语言对齐、多任务预训练和监督微调,每个阶段都有独特的数据类型和目标。模型的训练分辨率从 256 增加到 512,然后增加到 1024,表明其专注于提高图像生成质量。训练 tokens 和序列长度在各阶段显著增长,反映了模型预训练和微调过程日益增加的复杂性和规模。
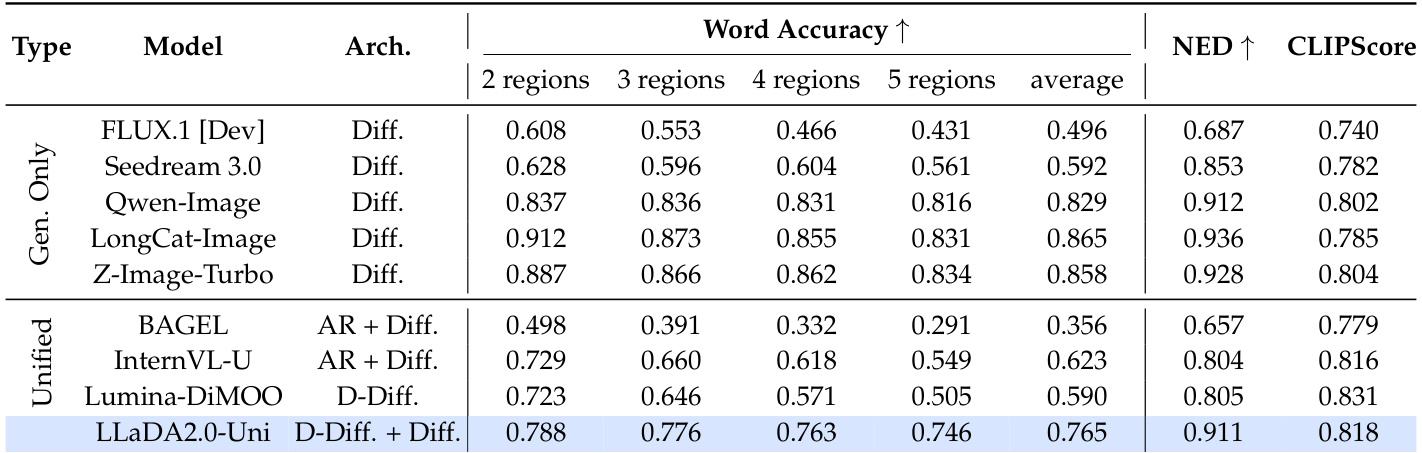
表格展示了各种模型在 CVTG-2K 基准测试中文本渲染性能的比较,重点是多区域文本生成。随着区域数量的增加,LLaDA2.0-Uni 展示了卓越的稳定性,与其他统一模型相比保持了更高的分数。结果显示,LLaDA2.0-Uni 在统一模型中整体性能领先,并在多个区域的文本渲染中保持了强大的连贯性。LLaDA2.0-Uni 在多区域文本生成的稳定性方面优于其他统一模型。LLaDA2.0-Uni 在 CVTG-2K 基准测试的统一模型中获得了最高总分。随着区域数量的增加,LLaDA2.0-Uni 保持了稳定的性能,而其他模型则表现出剧烈下降。
通过将标准扩散 decoder 与使用更少步骤的 turbo 版本进行比较,评估了性能和速度。结果显示,turbo decoder 在保持多个基准测试中具有竞争力的性能的同时,实现了显著的加速,分数和视觉质量的差异极小。在包括通用生成、文本到图像生成和推理引导的图像生成在内的各种任务中,性能保持一致。turbo decoder 在多个基准测试中实现了大幅加速,同时保持了与标准 decoder 相当的性能。GenEval、DPG 和 UniGenBench 等性能指标在 turbo decoder 下的下降极小,表明了鲁棒性。标准 decoder 和 turbo decoder 之间的视觉质量几乎无法区分,证实了输出保真度的一致性。

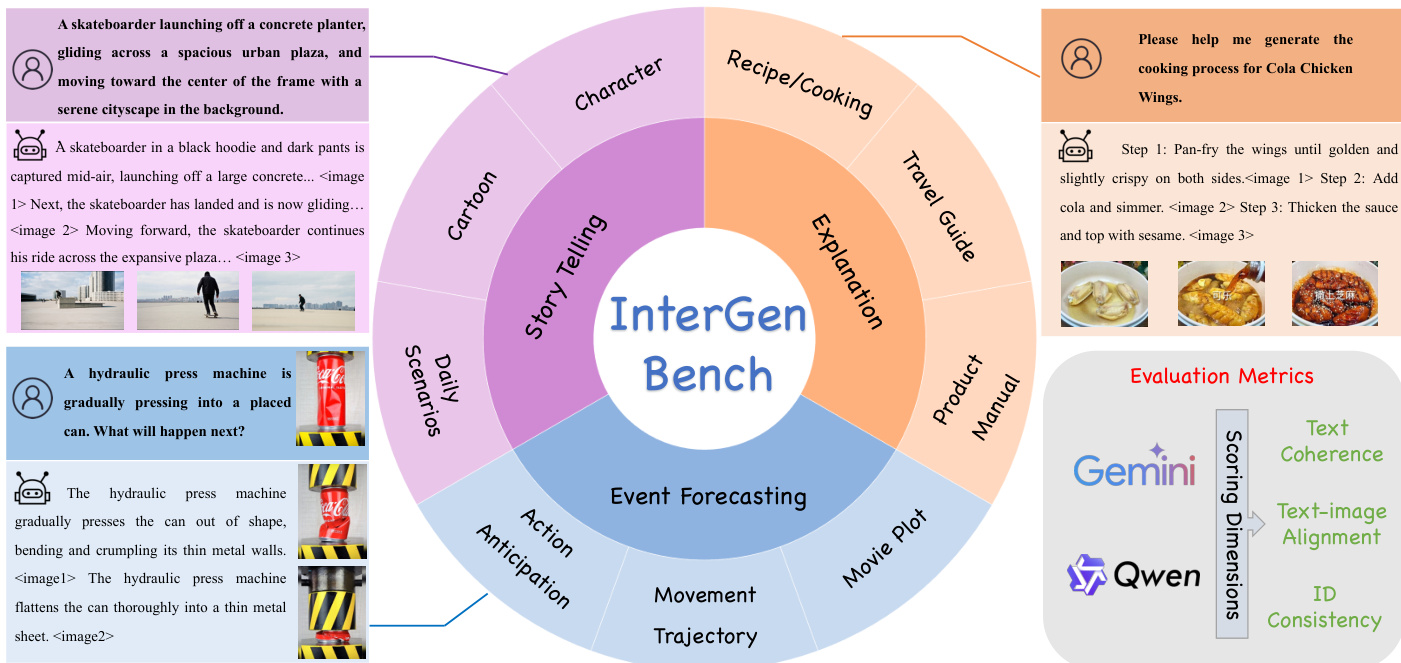
在 InterGen 基准测试上评估了 LLaDA2.0-Uni,并将其与 Emu3.5 在需要文本和图像理解的交错生成任务中进行了比较。结果显示,LLaDA2.0-Uni 在 Story Telling 和 Event Forecasting 方面优于 Emu3.5,同时在 Explanation 方面达到了相当的性能。该模型在不同的推理和叙事任务中展示了生成连贯且对齐的多模态输出的强大能力。LLaDA2.0-Uni 在 InterGen 基准测试的 Story Telling 和 Event Forecasting 中获得了比 Emu3.5 更高的分数。LLaDA2.0-Uni 在 Explanation 任务中表现与 Emu3.5 相当,表明了强大的多模态连贯性。LLaDA2.0-Uni 展示了鲁棒的交错生成能力,特别是在叙事和预测推理语境下。

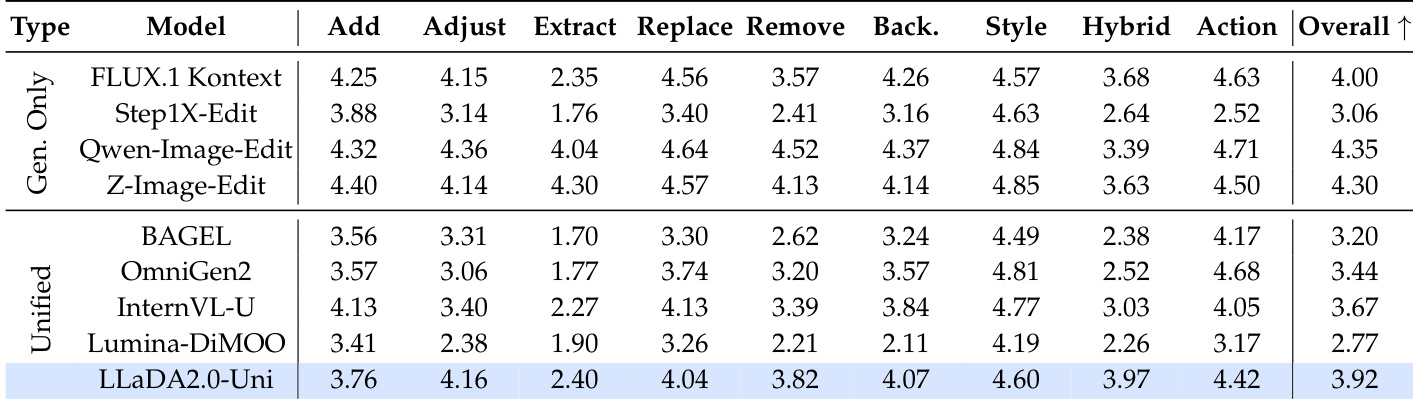
在基于指令的图像编辑任务上评估了 LLaDA2.0-Uni,并将其与专业模型和统一模型进行了比较。结果显示,LLaDA2.0-Uni 在统一模型中获得了最高总分,优于 OmniGen2 和 InternVL-U 等基线模型。它在 Adjust 和 Hybrid 编辑任务中表现尤为强劲,表明了强大的指令理解和执行能力。LLaDA2.0-Uni 在图像编辑基准测试的统一模型中获得了最高总分。LLaDA2.0-Uni 优于 OmniGen2 和 InternVL-U,在统一类别中排名第一。LLaDA2.0-Uni 在 Adjust 和 Hybrid 编辑任务中表现出色,展示了执行复杂指令的强大能力。
LLaDA2.0-Uni 通过一个渐进的三阶段训练过程开发,旨在增强视觉-语言对齐、多任务预训练和监督微调。在各种基准测试中的评估表明,该模型在多区域文本渲染稳定性、交错多模态生成和复杂的基于指令的图像编辑方面表现出色。此外,turbo decoder 的实现提供了显著的计算加速,同时保持了与标准 decoder 相当的视觉质量和性能。