Command Palette
Search for a command to run...
SWE-chat:来自真实用户在自然环境下编码智能体交互的研究
SWE-chat:来自真实用户在自然环境下编码智能体交互的研究
Joachim Baumann Vishakh Padmakumar Xiang Li John Yang Diyi Yang Sanmi Koyejo
摘要
尽管 AI 编程 Agent(智能体)正被大规模采用,但我们仍缺乏关于人们实际如何使用它们以及其输出在多大程度上具有实用价值的实证证据。我们发布了 SWE-chat,这是首个来自野外(真实环境)开源开发者的真实编码 Agent 会话的大规模数据集。该数据集目前包含 6,000 个会话,涵盖超过 63,000 个用户 prompt(提示词)和 355,000 个 Agent tool calls(工具调用)。SWE-chat 是一个动态数据集;我们的采集 pipeline(流水线)能够自动且持续地从公共仓库中发现并处理会话。借助 SWE-chat,我们对真实世界中编程 Agent 的使用情况及失效模式进行了初步的实证表征。我们发现编码模式呈现双峰分布:在 41% 的会话中,Agent 撰写了几乎所有的提交代码(即“氛围编程”/vibe coding),而在 23% 的会话中,人类编写了所有代码。尽管能力迅速提升,但在自然使用场景下,编程 Agent 的效率依然低下。仅有 44% 的 Agent 生成代码最终保留在用户的提交中,且 Agent 编写的代码比人类编写的代码引入了更多的安全漏洞。此外,在 44% 的所有交互轮次中,用户会对 Agent 的输出提出反对——通过修正、失败报告和中断等方式。
一句话总结
SWE-chat 是首个大规模的真实编码 agent 会话数据集,由开源开发者在野外环境中产生,包含 6,000 个会话、超过 63,000 个用户提示和 355,000 个 agent 工具调用。该数据集揭示了双峰编码模式,其中 41% 的会话中 agent 几乎编写了所有提交的代码("vibe coding"),而 23% 的会话中人类自己编写所有代码。此外,研究发现仅 44% 的 agent 生成代码存活至用户提交,且比人类编写的代码引入更多安全漏洞,用户在 44% 的所有回合中对 agent 输出提出异议。
核心贡献
- 本文介绍了 SWE-chat,这是一个从开源开发者处收集的包含 6,000 个真实世界编码 agent 会话的大规模数据集,其中包括超过 63,000 个用户提示和 355,000 个 agent 工具调用。SWE-chat 作为一个动态数据集发挥作用,其收集管道自动且持续地发现并处理来自公共仓库的会话。
- 这项工作提供了真实世界使用情况和故障模式的初步实证特征。分析显示编码模式呈双峰分布,在 41% 的会话中 agent 几乎编写了所有代码,而在 23% 的会话中人类编写了所有代码。
- 结果显示编码 agent 在自然环境中仍然效率低下,因为仅 44% 的 agent 生成代码存活至用户提交,且比人类编写的代码引入更多安全漏洞。此外,用户通过修正、故障报告和中断在 44% 的所有回合中对 agent 输出提出异议。
引言
AI 编码 agent 正在通过工具调用自主执行复杂任务来改变软件开发,但其在真实工作流中的集成仍知之甚少。当前基准测试依赖于策划的问题和固定解决方案,未能捕捉人机协作的迭代性质或开发者如何引导和修正 agent 输出。作者通过引入 SWE-chat 解决了这一问题,这是一个源自真实用户交互的数据集,记录了开发者在实际工作流中如何提示、覆盖和评估编码 agent。
数据集
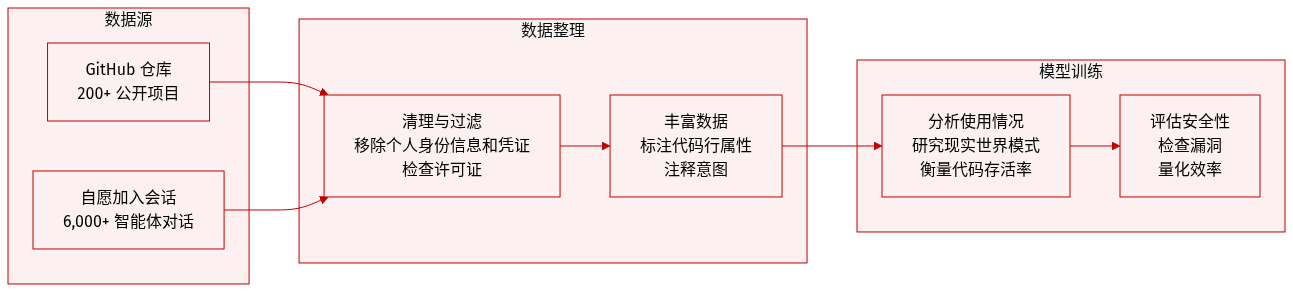
-
数据集构成与来源
- 作者介绍了 SWE-chat,这是一个从公共 GitHub 仓库收集的持续增长的真人-编码 agent 交互数据集。
- 数据源自选择加入 Entire.io 的 CLI 检查点日志记录的开发者,该记录在链接到代码提交的专用分支上记录会话转录。
- 收集范围涵盖 200+ 个仓库,包括与五个广泛使用的编码 agent 的交互,如 Claude Code、OpenCode、Gemini CLI、Cursor 和 Factory AI Droid。
-
关键细节与子集
- 截至 2026 年 4 月,该数据集包含 6,000 个会话,由超过 63,000 个用户提示和 355,000 个 agent 工具调用组成。
- 完整语料库包含 270 万个日志事件,涵盖流式进度事件、工具返回值,以及包含扩展思考痕迹的 200 个会话子集。
- 数据经过过滤,仅包含允许再分发的许可证的仓库以及开发者主动选择加入公共检查点日志记录的会话。
-
数据使用与分析
- 本文利用数据对真实世界编码 agent 使用情况和故障模式进行实证特征分析,而非用于模型训练。
- 研究人员分析交互行为和故障响应,以解决有关用户意图和 agent 效率的研究问题。
- 计算指标以量化代码存活率、每提交行的 token 成本以及 agent 输出引入的安全漏洞。
-
处理与元数据构建
- 作者应用隐私过滤器,使用 Microsoft Presidio 移除个人身份信息,并使用 TruffleHog 剥离凭证。
- 行级代码作者归属是使用影子分支上的临时检查点构建的,以区分人类和 agent 编写的行。
- 会话日志通过 LLM 评判器进行增强,添加了提示意图、用户角色和反驳的注释,并经过人类专家黄金标签验证。
- 在去除代码块并使用 UMAP 降低嵌入维度后,对英文提示执行主题聚类,以识别软件工程活动。
方法
该系统采用多阶段框架来分析编码 agent 交互,包括会话级角色分类、提示级意图分类和结构化评估流程。
会话角色分类器旨在对整个交互期间的用户行为模式进行分类。它处理编码会话的时间线,涵盖用户提示、模型响应、AI agent 编码操作(如文件编辑和工具调用)、提交以及可见的用户反应。如下图所示,时间线捕捉了用户和 agent 之间的基于回合的交换。

基于约束特异性、目标稳定性和修订行为等证据,模型将用户分配到以下四类之一:专家挑剔者、模糊请求者、改变主意者或其他。
作为补充,提示意图分类器在单个提示的粒度上运行。利用如 Qwen/Qwen3.5-27B 等模型,解码参数为 $temperature = 0.7$ 和 $top\_p = 0.8$,该模块为每个提示分配主要意图标签。标签包括创建新代码、重构、调试、理解、连接、git、测试或其他,从而允许在整个会话中精确跟踪用户目标。
最后,该框架包含一个评估流程,以在五个维度上评估会话质量。这些维度包括目标完成度、最终会话状态、agent 效率、代码和提交质量以及用户体验。评估依赖于转录中的具体证据,以判断请求是否得到解决、会话是否自然结束,以及 agent 是否在没有不必要重试的情况下表现出稳步进展。
实验
本研究通过将交互分类为纯人类、协作和 vibe coding 模式来分析真实世界的编码 agent 会话,以评估成功率、效率和安全影响。结果表明,虽然大多数请求得到满足,但完全自主的 vibe coding 被证明成本更高且更慢,同时以显著高于纯人类开发的速率引入安全漏洞。此外,交互模式揭示了 agent 自主性上升与用户监督之间的脱节,因为尽管人类频繁中断和修正,agent 很少寻求澄清。
作者针对人类黄金标准数据集评估了多个 LLM,该数据集包含 100 个样本,涵盖七个标注任务。结果显示模型性能取决于任务,特定模型在交互分析、仓库分类或会话评分方面表现出色。gpt-5.4-2026-03-05 模型在交互指标方面实现了最高准确率,包括提示反驳和用户角色。claude-opus-4-6 模型在分类仓库领域和目标受众方面表现出卓越性能。特定任务的领导者出现,qwen-3.5-27b 在提示意图方面表现最佳,claude-sonnet-4-6 实现了最高的会话成功相关性。
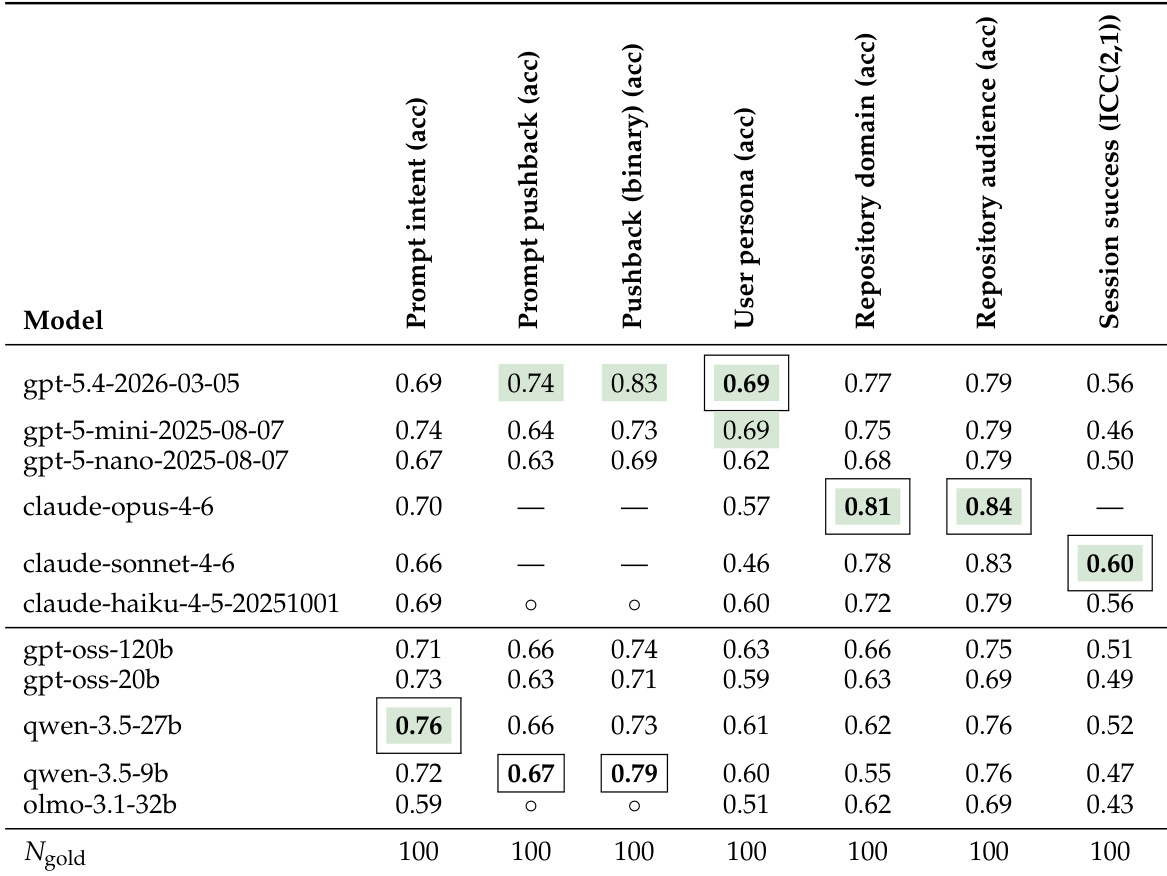
作者验证了其标注方案在关键交互维度(如提示意图、用户反驳和用户角色)上的一致性。两名人类标注者审查了会话样本,以确保这些类别的定义得到可靠应用。将提示反驳分类为二元类别在标注者之间产生了最高的一致性。识别特定用户角色被证明是最困难的,产生了最低的一致性分数。提示意图和反驳行为的总体分类在标注团队中保持了强一致性。

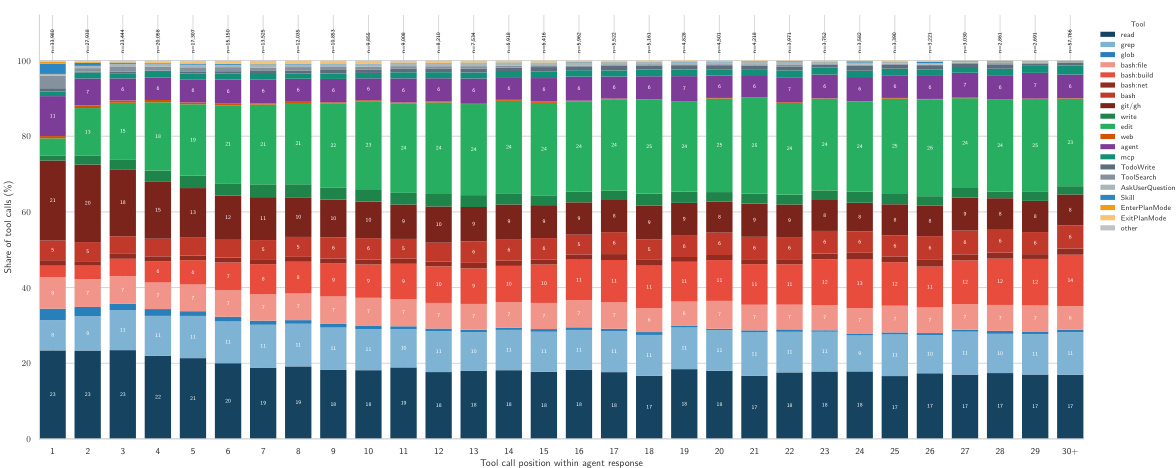
该图表可视化了 agent 响应轨迹中工具使用的顺序分布。它突出了一种独特的模式,即早期交互侧重于信息收集,而后期交互转向代码修改和执行。读取操作在最早的位置占主导地位,表明初始阶段的代码库探索。随着 agent 过渡到实现,写入和构建工具的份额在后期位置显著增加。研究工具如 grep 和 git 命令在轨迹开始时最为突出。
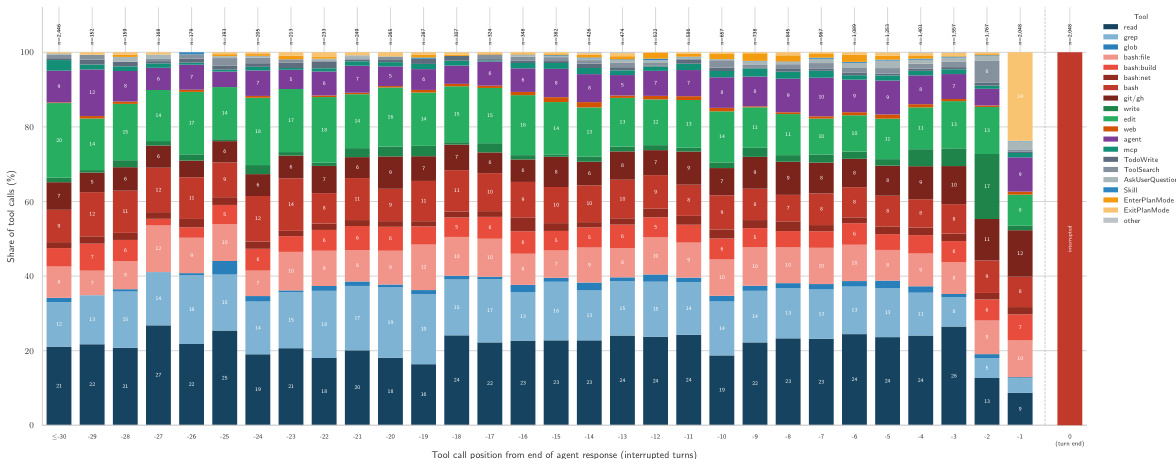
该图表说明了以硬性用户中断结束的 agent 轨迹中工具调用的分布。它揭示了一个清晰的进展,其中 agent 从 read 和 grep 等研究工具开始以理解代码库,然后在回合结束时转向 edit 和 bash:build 等操作工具。这种轨迹模式支持了用户经常在从规划到执行的关键过渡期间中断 agent 的发现。研究工具在 agent 轨迹的初始位置占主导地位。随着回合接近尾声,操作工具成为主要活动。中断经常发生在从规划到执行的过渡期间。
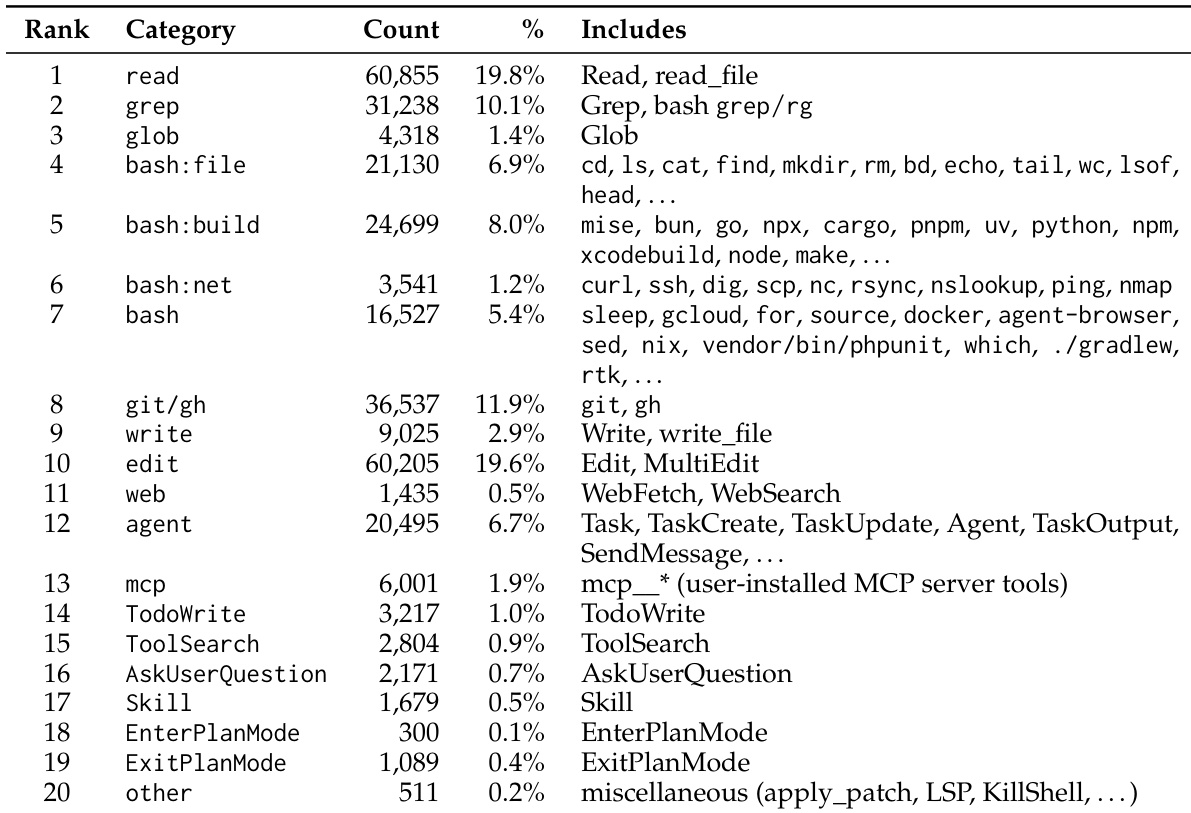
该表详细说明了编码 agent 进行的工具调用分布,显示读取和编辑文件是最常见的操作。版本控制和文本搜索也被高度利用,表明工作流侧重于导航和修改代码库。Shell 命令进一步按功能细分,构建操作发生的频率高于文件管理或网络任务。文件读取和编辑操作在工具使用分布中占主导地位,各占总量的近五分之一。版本控制和文本搜索命令是下一最常见的类别,突出了代码导航和修改的重要性。Shell 命令被细分为特定功能,构建任务出现的频率高于文件管理或网络操作。
该研究针对人类黄金标准评估了多个大型语言模型,涉及七个标注任务,揭示性能取决于任务,不同模型在交互分析或仓库分类等特定领域表现出色。人类标注者验证确认了提示意图和反驳等一般类别的强一致性,而识别特定用户角色被证明更具挑战性。此外,agent 轨迹分析表明从信息收集到代码执行的清晰进展,用户中断经常发生在此关键过渡阶段。