Command Palette
Search for a command to run...
近未来策略优化
近未来策略优化
Chuanyu Qin Chenxu Yang Qingyi Si Naibin Gu Dingyu Yao Zheng Lin Peng Fu Nan Duan Jiaqi Wang
摘要
具有可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)已成为后训练(post-training)阶段的核心方案。在 On-policy 探索中引入合适的 Off-policy 轨迹可以加速 RLVR 的收敛并提升性能上限,然而,如何寻找此类轨迹的来源仍是关键挑战。现有的混合策略方法要么从外部教师模型中导入轨迹(质量高但分布差异大),要么重放过去的训练轨迹(分布接近但质量受限),这两者都无法同时满足最大化有效学习信号 S=Q/V 所需的“足够强”(具有更高的 Q 值,能提供更多待学习的新知识)与“足够近”(具有较低的 V 值,更易于吸收)的条件。为此,我们提出了近未来策略优化(Near-Future Policy Optimization, NPO),这是一种简单的混合策略方案,旨在从策略自身的“近未来”中学习:即同一训练进程中的后续 checkpoint 是辅助轨迹的天然来源,它既比当前策略更强,又比任何外部来源更接近,从而直接在轨迹质量与方差成本之间实现了平衡。我们通过两种人工干预方式验证了 NPO 的有效性:早期引导(early-stage bootstrapping)和后期平台期突破(late-stage plateau breakthrough)。此外,我们还提出了 AutoNPO,这是一种自适应变体,能够根据在线训练信号自动触发干预,并选择能使 S 最大化的引导 checkpoint。在基于 GRPO 算法的 Qwen3-VL-8B-Instruct 模型上,NPO 将平均性能从 57.88 提升至 62.84,而 AutoNPO 则将其进一步推升至 63.15,在加速收敛的同时提升了最终的性能上限。
一句话总结
为了加速具有可验证奖励的强化学习,研究人员提出了近未来策略优化(Near-Future Policy Optimization, NPO)。这是一种混合策略方案,通过利用模型自身的后续 checkpoint 作为辅助轨迹,在平衡轨迹质量与方差成本之间实现有效学习信号的最大化。
核心贡献
- 本文引入了近未来策略优化(NPO),这是一种混合策略方案,利用同一训练运行中后续 checkpoint 的轨迹来引导当前策略。该方法提供的辅助轨迹比历史回放(replay)更强,同时比外部教师模型更接近当前分布,从而有效地平衡了轨迹质量与方差。
- 本研究提出了 AutoNPO,这是一种自适应变体,通过监测奖励停滞和熵下降等在线训练信号,实现引导时机与选择的自动化。该框架会自动触发干预,并选择能够使有效学习信号的经验估计值最大化的特定引导 checkpoint。
- 实验结果通过在早期引导(bootstrapping)和后期平台突破(plateau breakthrough)场景中的成功手动干预,证明了 NPO 的有效性。该方法通过将优化时间作为特权信息,展示了桥接混合策略 RLVR 与自教(self-taught)方法的能力,从而提升了收敛速度和性能。
引言
具有可验证奖励的强化学习(RLVR)是增强大语言模型推理能力的关键训练后方法。虽然纯 on-policy 探索是标准做法,但在训练早期往往面临正确轨迹稀疏的问题,或者在后期进入性能平台期。现有的混合策略方法试图通过使用外部教师(这会引入高分布方差)或回放过去轨迹(受限于旧 checkpoint 的质量)来解决此问题。研究人员利用一种称为近未来策略优化(NPO)的时间方法来填补这一空白。通过使用同一训练运行中较晚的 checkpoint 作为辅助轨迹源,NPO 提供的学习信号既比当前策略强,在分布上也比外部模型更接近。这有效地平衡了信号质量与方差成本,从而实现了加速收敛和更高的性能上限。
方法
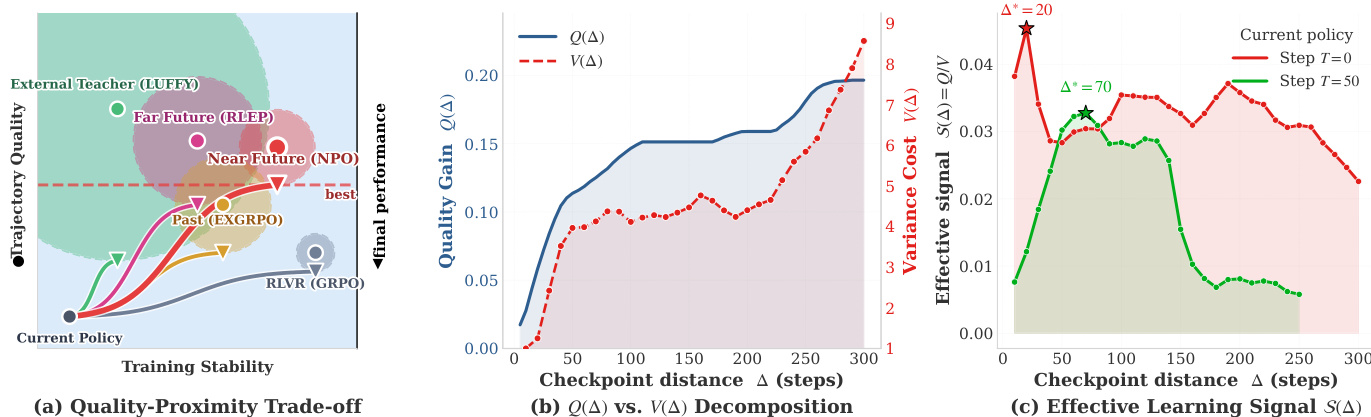
研究人员提出了近未来策略优化(NPO),该方法通过利用同一训练运行中近未来 checkpoint 的轨迹来引导当前策略,从而增强具有验证的强化学习(RLVR)。其核心见解在于,off-policy 引导的有效性受限于轨迹质量与方差成本之间的权衡。轨迹质量 Q(Δ) 衡量了源策略能够正确解决的 prompt 比例,它随当前策略与 checkpoint 之间的距离 Δ 的增加而增加。相比之下,由于结合不同策略的轨迹时使用重要性采样(importance weighting)而产生的方差成本 V(Δ),则随 Δ 近似呈指数级增长。因此,有效学习信号 S(Δ)=Q(Δ)/V(Δ) 呈现出 U 型曲线,在平衡这些竞争因素的最佳 checkpoint 距离 Δ∗ 处达到峰值。如下图所示,现有的方法(如远未来回放、过去轨迹回放和外部教师)处于质量与稳定性权衡平面的次优区域,而 NPO 通过使用既强大又与当前策略分布接近的近未来策略,瞄准了高 S 区域。
NPO 框架通过引入选择性引导机制修改了标准的 RLVR 训练循环。在当前策略为 π(t) 的训练步 t,该方法额外训练 Δ 步以获得近未来 checkpoint π(t+Δ)。随后回退到第 t 步,并使用 π(t+Δ) 为当前策略难以处理的 prompt 提供引导轨迹。具体而言,对于一个 prompt x,当前策略采样一组 n 个 on-policy 轨迹 {oi}i=1n。计算 on-policy 通过率 p^(x),如果 p^(x) 低于阈值 τgate 且预计算缓存中存在经验证正确的引导轨迹 ox′,则将 rollout 组中的第 n 个位置替换为 ox′。生成的组 GNPO(x) 用于计算组相对优势(group-relative advantages),并通过 clipped objective 更新策略,且仅对引导位置应用重要性采样修正。该过程的实现方式确保在 NPO 段期间不会产生额外的 rollout 成本,因为引导轨迹是离线缓存的。
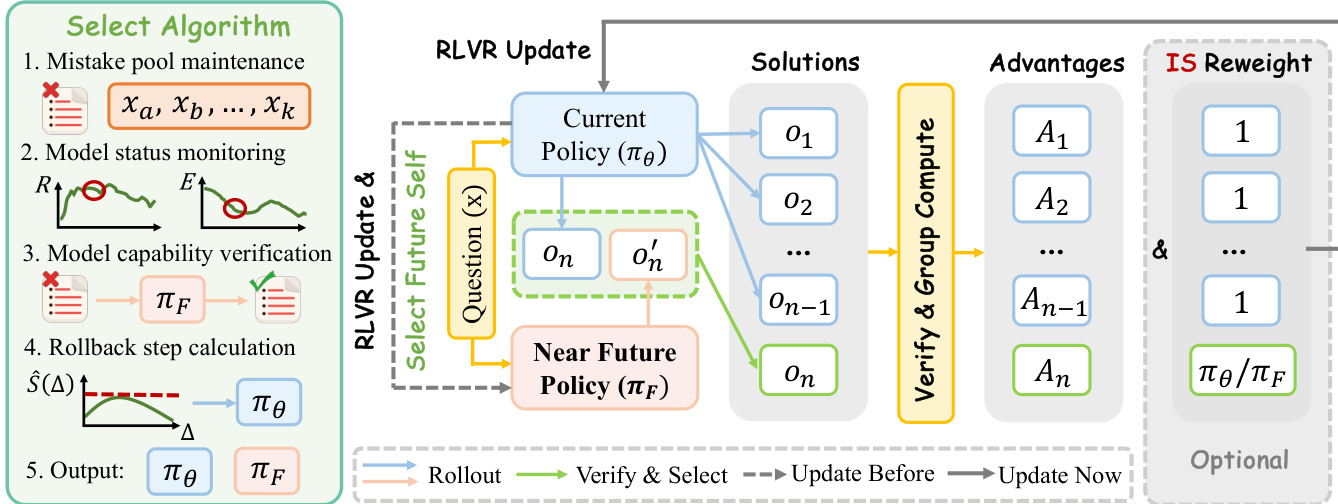
为了验证该方法,研究人员引入了两种手动干预:早期引导(early-stage bootstrapping)和后期平台突破(late-stage plateau breakthrough)。早期干预使用短时间的探测段(scout segment)生成近未来 checkpoint 来引导初始训练阶段,从而加速从冷启动状态的收敛。后期干预使用超越性能平台期的 checkpoint 来引导平台段的回放,使策略能够突破其 on-policy 上限。这些干预证明了近未来引导在不同训练阶段都是有益的。在此基础上,研究人员提出了 AutoNPO,这是一种自动执行干预过程的自适应变体。AutoNPO 维护一个当前策略失败的 prompt 错误池,并利用训练日志中的在线信号来确定何时进行干预以及回退多远。干预触发基于奖励停滞和熵下降的组合,而回退距离通过最大化有效学习信号的经验估计值 S^(Δ)=Q^(Δ)/V^(Δ) 来选择,其中 Q^(Δ) 是当前策略在从 t−Δ 开始的段内失败的 prompt 上的通过率,而 V^(Δ) 是根据当前策略与回退策略之间的每 token KL 散度估计的方差代理。这种自适应控制器复用了现有的训练信号并避免了大量开销,实现了在标准 RLVR 之上即插即用且保持目标的改进。
实验
研究人员在八个多模态推理基准测试中,将 NPO 及其变体与几种强化学习基线进行了对比,以验证针对性轨迹干预的有效性。结果表明,NPO(特别是自动化版本)通过提供及时的引导,防止了策略过早崩溃并保持了健康的探索,表现优于现有方法。通过策略性地注入高质量轨迹,该方法成功突破了性能平台,并在不需要复杂的重要性采样修正的情况下实现了卓越的推理深度。
研究人员在多模态推理基准测试上将 NPO 方法与多个基线进行了对比,结果显示手动和自动 NPO 变体均一致优于现有的强化学习方法。AutoNPO 实现了最高的平均准确率并在多个单独任务中领先,证明了针对性干预可以在不需要精确重要性采样修正的情况下改善训练动态。结果表明,NPO 的近策略引导能够在保持探索并避免策略过早崩溃的同时,实现有效且稳定的提升。AutoNPO 获得了最高的平均准确率并在多个基准测试中领先,优于包括 GRPO 和基于回放的方法在内的所有基线。NPO 在整个训练过程中保持了更高的策略熵,防止了过早崩溃并支持了更高的后期性能上限。由于其近策略引导的特性,NPO 不需要进行重要性采样修正,在不牺牲收益的情况下简化了方法。
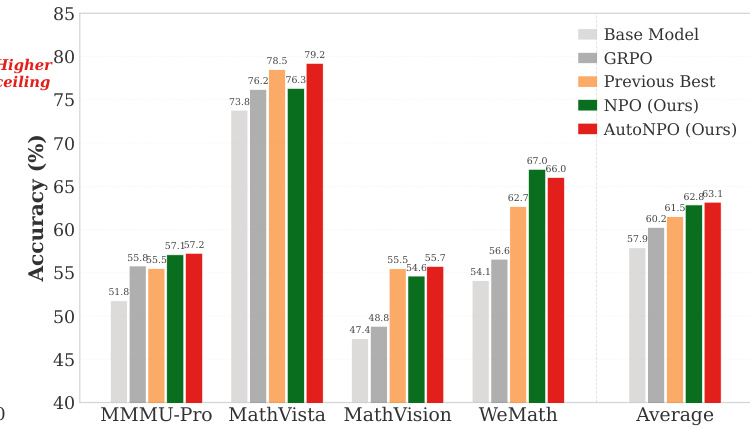
研究人员使用 Qwen3-VL-8B-Instruct 作为基础模型,在多模态推理基准测试上评估了 NPO 及其变体与多个基线的表现。结果显示,NPO 方法(尤其是 AutoNPO)比所有基线都实现了更高的平均性能,其提升由增强训练动态并维持策略探索的针对性干预所驱动。NPO 变体在多个基准测试中均优于所有基线,其中 AutoNPO 获得了最高的总分。AutoNPO 通过针对性干预维持更高的策略熵并避免过早崩溃,从而改善了训练动态。研究发现,由于近策略引导的作用,NPO 不需要重要性采样修正,这在不牺牲性能的情况下简化了实现。
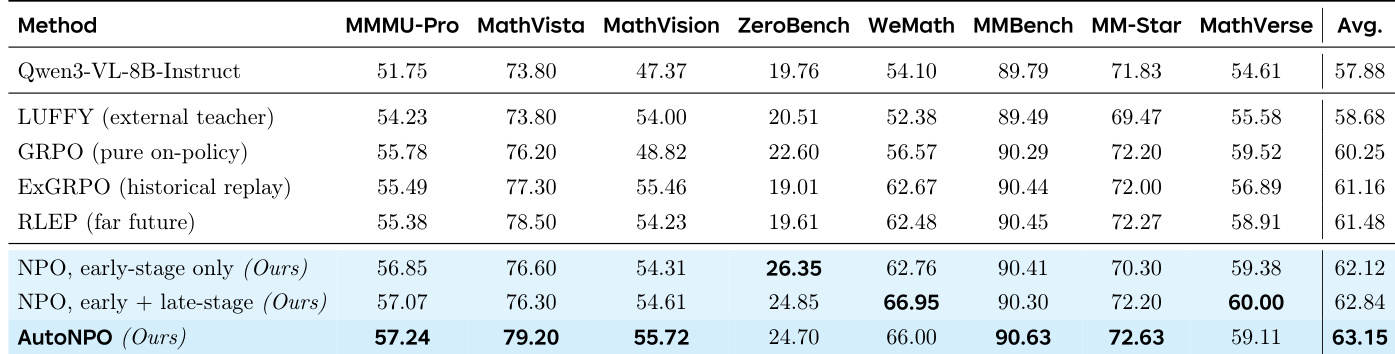
研究人员使用 Qwen3-VL 基础模型在多模态推理基准测试上,将 NPO 方法及其变体与几种强化学习基线进行了对比。实验表明,NPO(特别是自动化的 AutoNPO 变体)通过针对性干预增强训练动态,表现始终优于现有方法。这些结果表明,近策略引导能有效维持策略熵并防止过早崩溃,从而在不需要复杂重要性采样修正的情况下实现稳定的提升。