Command Palette
Search for a command to run...
EnergAIzer:面向 AI 工作负载的快速且准确 GPU 功耗估算框架
EnergAIzer:面向 AI 工作负载的快速且准确 GPU 功耗估算框架
Kyungmi Lee Zhiye Song Eun Kyung Lee Xin Zhang Tamar Eilam Anantha P. Chandrakasan
摘要
随着人工智能(AI)工作负载推动数据中心功耗持续增长,准确的 GPU 功率估算对于实施主动式电源管理至关重要。然而,现有的功率模型面临的可扩展性瓶颈并非源于建模技术本身,而在于获取这些模型所需的硬件利用率输入数据。传统方法依赖于昂贵且耗时的仿真或硬件性能剖析,这在需要快速预测的场景下难以实用。本文提出了 EnergAIzer,旨在通过开发一种轻量级解决方案来预测利用率输入数据,从而突破这一可扩展性瓶颈,将估算等待时间从数小时缩短至数秒。我们的核心洞察在于,AI 工作负载中的内核(Kernel)通常采用特定优化手段,从而形成结构化模式,这些模式可以从解析层面决定内存流量和执行时间线。我们利用这些模式构建了一个性能模型,将其作为经验数据拟合的分析骨架,该模型还能自然地揭示模块级的利用率信息随后,预测出的利用率被输入至我们的功率模型中,以估算动态功耗。在 NVIDIA Ampere GPU 上的测试表明,EnergAIzer 实现了 8% 的功率估算误差,其精度与依赖详尽的循环级仿真或硬件剖析的传统功率模型相当。我们展示了 EnergAIzer 在频率缩放和架构配置探索方面的能力,包括以仅 7% 的误差预测 NVIDIA H100 的功耗。总之,EnergAIzer 为 AI 工作负载提供了快速且准确的功率预测,为电源感知型设计探索铺平了道路。
一句话总结
EnergAIzer 通过结构化内核模式预测硬件利用率输入,解决了估算 AI 工作负载动态 GPU 功耗的可扩展性瓶颈,而非依赖昂贵的仿真或硬件分析,将估算等待时间从数小时缩短至数秒,在 NVIDIA Ampere GPU 上功耗误差为 8%,在 NVIDIA H100 上误差为 7%,从而支持快速的功耗感知设计探索。
核心贡献
- 这项工作提出了 EnergAIzer,一种轻量级解决方案,通过预测硬件利用率输入将估算等待时间从数小时减少到数秒。该系统消除了传统方法所需的昂贵仿真或硬件分析需求。
- 该方法利用 AI 工作负载内核中常见的结构化模式构建性能模型,作为经验数据拟合的分析框架。这种方法分析性地确定内存流量和执行时间线,同时自然暴露模块级利用率以进行准确的功耗估算。
- 实验表明,EnergAIzer 在 NVIDIA Ampere GPU 上实现了 8% 的功耗误差,与需要详尽周期级仿真的传统模型保持竞争力。该框架还支持频率扩展和架构配置的探索,成功预测 NVIDIA H100 的功耗,误差仅为 7%。
引言
AI 工作负载正推动数据中心功耗显著增加,使得准确的 GPU 功耗估算对于优化资源分配和硬件设计至关重要。传统功耗模型依赖昂贵的周期级仿真或物理硬件分析来获取必要的利用率输入,造成了阻碍快速设计探索的可扩展性瓶颈。现有的轻量级性能模型无法捕获准确功耗预测所需的特定模块活动和内存层次结构细节。作者提出了 EnergAIzer,这是一个利用 AI 内核固有的结构化优化模式来无需仿真即可分析性预测硬件利用率的框架,将估算时间从数小时减少到数秒,同时保持竞争力精度。
数据集
- 数据集组成和来源: 作者提供了一个预收集的数据库用于经验拟合和真实测量以验证预测。这些工件托管在 EnergAIzer Github 仓库和 Zenodo 存档上。
- 关键细节: 数据支持单内核级功耗和延迟估算,以及 AI 工作负载的端到端估算。包含脚本来复现不同 AI 工作负载和 GPU 配置探索的实验。
- 数据用途: 数据库用于经验拟合,而测量数据用于验证。该框架允许用户调整工件以进行 GPU 功耗和能量预测。
- 处理和要求: 执行需要在 x86-64 或 Arm 机器上的虚拟环境中使用 Python3。用户需要 200 MB 磁盘空间以及 Linux 或 Mac OS 环境。除非自定义数据库收集,否则不需要 GPU 机器。
方法
EnergAIzer 框架旨在通过分离一次性离线训练和快速在线推理来预测 GPU 上 AI 工作负载的延迟和功耗。系统以 AI 工作负载、GPU 架构配置和功耗设置作为输入,生成端到端延迟和平均功耗估算。此工作流程的关键组件是内核配置预测器,它使用在离线数据库上训练的决策树从张量形状推断优化参数(如分片和流水线),消除了推理期间物理分析的需求。
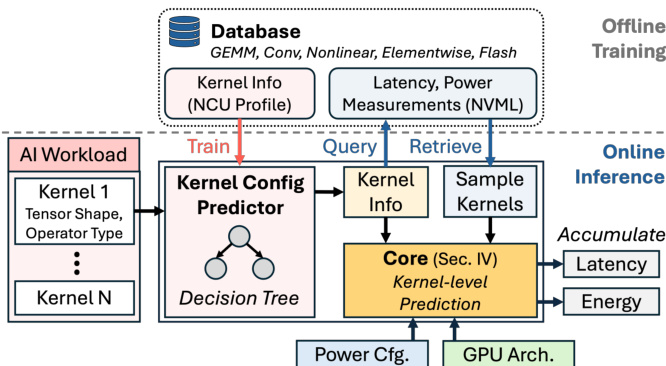
系统的核心在于 EnergAIzer Core,它通过三阶段流水线执行内核级预测。如框架图所示,核心通过抽象模块、性能模型和最终功耗模型处理内核信息、GPU 架构细节和功耗配置,以输出延迟和功耗估算。
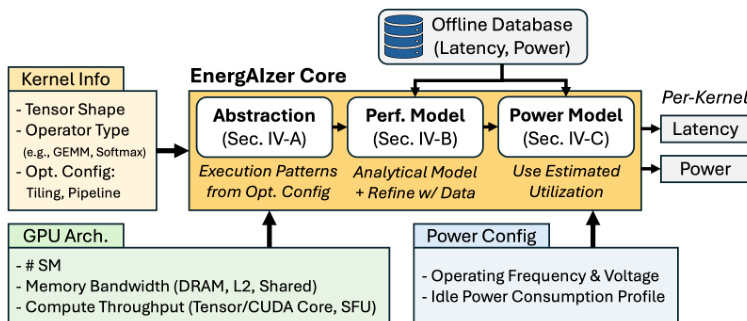
抽象模块基于主导 AI 内核(如 GEMM、Softmax 和 FlashAttention)中发现的常见软件优化选择建立工作负载表示。张量在线程块、warp 和指令级别分层划分为片,这决定了内存流量和工作分布。例如,线程块级片决定全局内存流量和 SM 分布,而 warp 级片定义共享内存使用情况。作者根据这些分片参数和理想的线程块洗牌分析性地推导出 DRAM、L2 缓存和共享内存的内存流量。这种分析方法与测量的硬件计数器值高度一致,如各种内核类型的验证图所示。
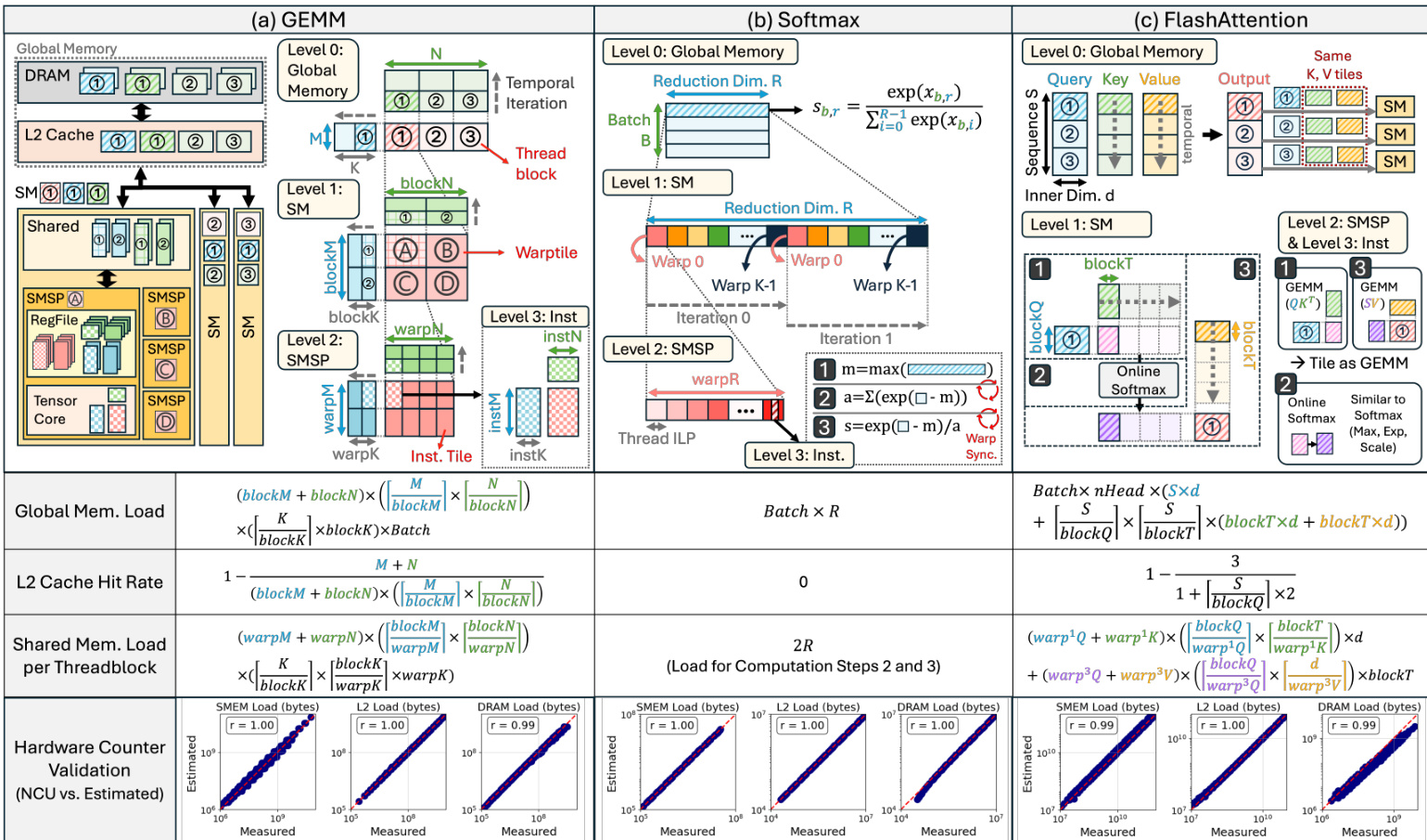
抽象之后,性能模型构建粗粒度执行时间线以暴露模块级利用率。该时间线映射数据加载、存储和计算等操作,并根据流水线策略确定其重叠。例如,在 GEMM 内核中,多阶段流水线允许全局内存加载与共享内存加载重叠,Tensor Core 计算隐藏延迟。操作的理想延迟计算为工作量除以模块带宽或并发度。为了解决难以分析建模的次要影响(如内核启动开销或内存库冲突),作者应用经验校正。校正后的延迟计算为 t^corrected=λ×tideal+ε,其中系数拟合到离线数据库以最小化预测误差。不同内核的时间线构建,包括序幕、主循环和尾声的不同阶段,在执行时间线图中可视化。
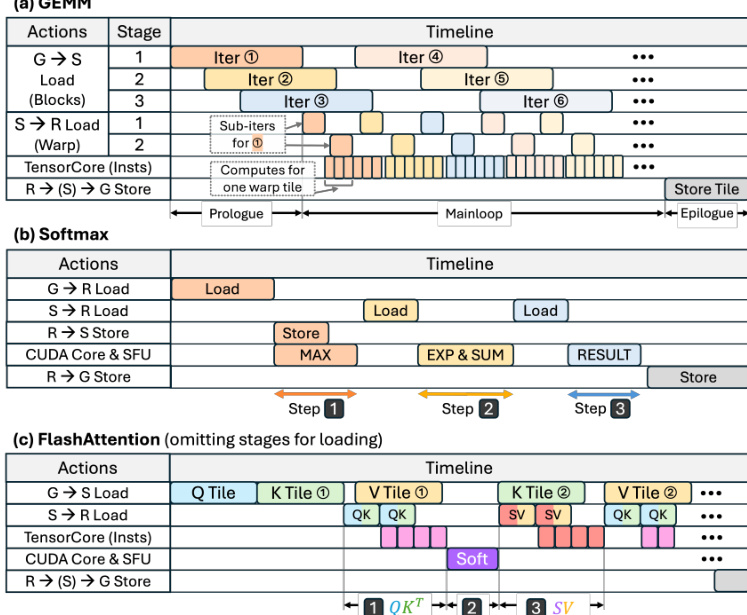
最后,功耗模型利用推导出的时间线估算功耗。模块级利用率计算为模块活动时间与总内核延迟的比率,其中活动时间是参与该模块的所有操作延迟之和。此利用率信息结合功耗配置设置(如工作频率和电压),允许系统估算动态功耗。离线训练过程涉及通过 NVML 收集延迟和功耗测量,并通过 NCU 收集内核信息,以训练决策树并拟合经验校正系数,确保在各种张量形状和内核类型上具有高准确性,而无需运行时分析。
实验
EnergAIzer 在 NVIDIA A100 和 A10 GPU 上使用不同的语言和视觉工作负载进行评估,以验证其延迟和功耗估算准确性以及设计空间探索能力。实验表明,该框架实现了具有竞争力的预测误差,同时与传统硬件分析工具相比提供了数量级更快的推理时间。此外,该系统成功预测了新 GPU 架构和算法配置(如电压频率扩展和精度变化)的性能,而无需收集新数据。
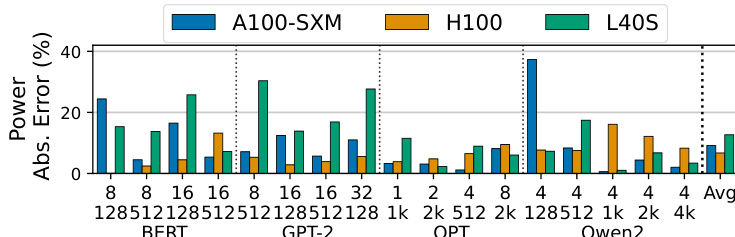
作者评估了其框架在不同 GPU 架构上的功耗估算准确性,具体比较了 A100-SXM、H100 和 L40S 模型。结果表明模型能够跨代泛化,尽管准确性取决于所使用的特定硬件架构和内存技术。该图表显示了 A100-SXM、H100 和 L40S GPU 在 BERT、GPT-2、OPT 和 Qwen2 模型上的功耗估算误差。L40S 通常显示出比其他两种架构更高的误差率,特别是在 GPT-2 和 OPT 配置中。H100 显示出具有竞争力的误差率,通常低于 A100-SXM 基线,表明具有稳健的跨代预测能力。
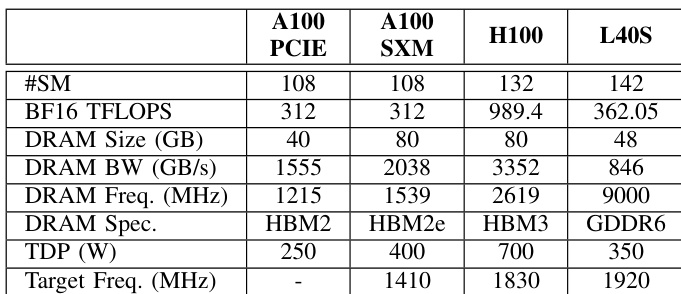
作者展示了四种不同 GPU 架构的硬件规格比较,以展示其框架探索设计选择的能力。数据对比了 A100 变体与 H100 和 L40S 等新一代,突出了计算吞吐量和内存技术的差异。此设置允许系统测试跨相似和不同硬件代的功耗预测准确性。规格涵盖了四种不同 GPU 型号的计算性能、内存容量和功耗限制。像 H100 这样的新架构显示出比 A100 系列高得多的计算吞吐量和内存带宽。L40S 配置的独特之处在于使用 GDDR6 内存,不同于其他列出的 GPU 中发现的 HBM 变体。
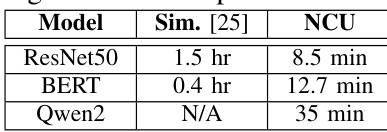
该表比较了基于仿真的估算和 NCU 分析在不同深度学习模型上的时间成本。仿真方法显示最耗时,需要数小时完成,而 NCU 分析更快但仍需要数分钟。此数据支持论文的观点,即与所提出的轻量级框架相比,现有方法具有不切实际的墙钟时间。对于测试的模型,基于仿真的估算比 NCU 分析需要显著更多的时间。NCU 分析持续时间随模型扩展,在 Qwen2 模型上耗时最长。仿真方法不适用于 Qwen2 模型,指示为缺失值。
作者将其轻量级预测方法与仿真和硬件分析基线进行比较,展示了墙钟时间从数小时或数分钟大幅减少到数秒。所提出的方法在现代 GPU 架构(如 Ampere 和 Hopper)上实现了具有竞争力的准确性,而先前的方法通常局限于旧一代或需要显著更长的处理时间。预测时间减少到数秒,比需要数分钟或数小时的方法提供了巨大的加速。该框架支持最近的 GPU 架构(如 Ampere 和 Hopper),不像局限于旧一代的基线。准确性保持低且具有竞争力,表现优于仿真并与硬件分析相当。
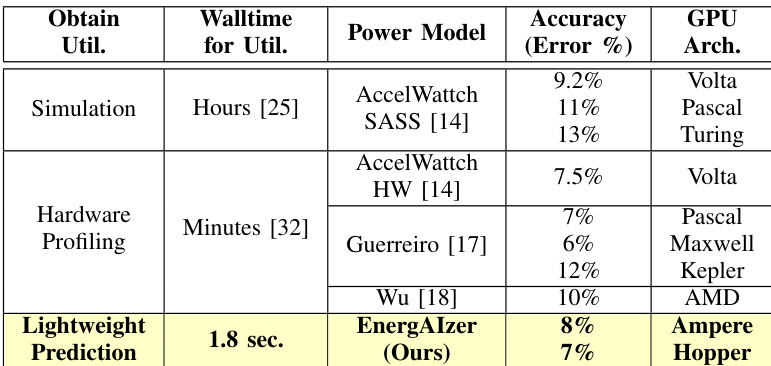
该评估评估了跨不同 GPU 架构(包括 A100、H100 和 L40S)的功耗估算准确性,展示了框架跨硬件代泛化的能力,尽管误差率不同。比较仿真和分析基线的实验表明,现有方法产生不切实际的墙钟时间,而所提出的轻量级方法提供了预测延迟的大幅减少。总体而言,该框架在现代架构上保持竞争力准确性,同时在速度和硬件兼容性方面显著优于先前的方法。