Command Palette
Search for a command to run...
DR-Venus:仅需 1 万条开源数据,迈向前沿边缘规模深度研究 agent
DR-Venus:仅需 1 万条开源数据,迈向前沿边缘规模深度研究 agent
摘要
基于小语言模型的边缘侧深度研究 agents,因其在成本、延迟和隐私方面的优势,在实际部署中具有极高的吸引力。在这项工作中,我们通过提高数据质量和数据利用率,研究了如何在有限的开源数据下训练出强大的小型深度研究 agent。我们推出了 DR-Venus,这是一款完全基于开源数据构建、面向边缘侧部署的前沿 4B 规模深度研究 agent。我们的训练方案包含两个阶段。在第一阶段,我们采用 agentic 有监督微调(SFT)来建立基础的 agent 能力,通过严格的数据清洗结合长程轨迹(long-horizon trajectories)的重采样,来提升数据质量与利用率。在第二阶段,我们应用 agentic 强化学习(RL),以进一步提高在长程深度研究任务中的执行可靠性。为了使 RL 在这种场景下对小型 agent 产生显著效果,我们在 IGPO 的基础上,设计了基于信息增益(information gain)和格式感知正则化(format-aware regularization)的轮次级奖励(turn-level rewards),从而增强了监督密度并优化了轮次级的信用分配(credit assignment)。DR-Venus-4B 完全基于约 1 万条开源数据构建,在多个深度研究基准测试中,其表现显著优于此前参数量在 9B 以下的 agent 模型,同时缩小了与更大规模(30B 级别)系统之间的差距。我们的进一步分析表明,4B 规模的 agents 已经展现出了令人惊讶的强大性能潜力,这不仅凸显了小模型在部署方面的前景,也体现了在此场景下测试时扩展(test-time scaling)的价值。我们开源了模型、代码及核心训练方案,以支持针对边缘侧深度研究 agents 的可复现研究。
一句话总结
Venus 团队推出了 DR-Venus,这是一款前沿的 4B 参数深度研究 Agent,专为边缘规模部署而设计。通过由 agentic supervised fine-tuning 和基于信息增益及格式感知正则化的 agentic reinforcement learning 组成的两个阶段训练方案,该 Agent 仅利用 10K 个开源数据样本,便在 9B 参数以下的模型中显著超越了以往模型,并接近 30B 级系统的性能。
核心贡献
- 本文介绍了 DR-Venus,这是一款 4B 参数的深度研究 Agent,专为边缘规模部署而设计,完全基于约 10K 个开源数据样本进行训练。
- 研究人员开发了一种两阶段训练方案,包括使用经过清洗和重采样的长程轨迹进行 agentic supervised fine-tuning (SFT),随后进行 agentic reinforcement learning (RL),该 RL 利用基于信息增益和格式感知正则化的轮次级(turn-level)奖励。
- 实验结果表明,DR-Venus-4B 在多个深度研究基准测试中显著优于现有的 9B 参数以下的 agentic 模型,并缩小了与规模大得多的 30B 级系统之间的性能差距。
引言
能够进行迭代搜索和证据合成的深度研究 Agent 对于复杂的信息寻求任务至关重要,然而在边缘设备上部署这些 Agent 需要小语言模型在成本、延迟和隐私方面进行优化。目前最先进的研究 Agent 通常依赖于海量的参数量或闭源数据集,这在基于开源数据训练的高性能小规模 Agent 领域留下了空白。小模型特别容易受到噪声训练轨迹的影响,并在 reinforcement learning 过程中面临重大挑战,因为稀疏奖励往往会导致训练不稳定。通过引入 DR-Venus,这些问题得到了解决。DR-Venus 是一个 4B 参数的 Agent,通过包含轨迹重采样的 agentic supervised fine-tuning 和使用轮次级奖励的 agentic reinforcement learning 的两个阶段过程进行训练。这种方法显著提高了数据利用率和监督密度,使 4B 模型能够超越 9B 参数以下的大型模型,并缩小与 30B 级系统的性能差距。
数据集

为了使用高度精选的开源数据训练边缘规模的深度研究 Agent,研究人员开发了 DR-Venus 数据集。数据集详情如下:
- 数据集组成与来源: 起始于 10,001 条原始 REDSearcher 轨迹。经过多阶段清洗和精炼过程,最终训练集包含 18,745 个实例。
- 数据处理与过滤:
- 环境对齐: 所有轨迹都被转换为标准化的交互格式,包括特定的消息模式、系统提示词以及工具调用/响应协议,以确保训练与在线推理之间的一致性。
- 工具裁剪与去重: 为了匹配部署环境,除了搜索(search)和浏览(browse)外,移除了所有工具交互。在轮次级别而非丢弃整个轨迹的方式来裁剪不允许的工具调用。此外还移除了 15,728 个重复的工具交互,主要是冗余的浏览事件。此阶段保留了 10,000 条有效轨迹。
- 正确性过滤: 使用 Qwen3-235B-A22B-Instruct-2507 作为评判模型来验证最终答案的准确性。这一步保留了 9,365 条高质量轨迹。
- 训练策略与重采样: 为了强调深度研究所需的长程规划能力,在 SFT 期间采用了轮次感知重采样策略。对于 0 到 50 轮的轨迹分配 1x 采样权重,51 到 100 轮分配 2x 权重,超过 100 轮的轨迹分配 5x 权重。这一过程将最终训练集扩展到 18,745 个实例,并将长程轨迹(超过 100 轮)的比例从 13.29% 显著提升至 33.21%。
方法
研究人员利用两阶段训练框架开发了 DR-Venus,这是一款能够通过与外部环境进行长程交互来解决复杂信息寻求任务的深度研究 Agent。整体方法围绕两个互补目标构建:提高训练数据质量和增强数据利用率。该框架首先将深度研究任务公式化为一个长程推理与行动问题,其中 Agent 必须迭代地进行推理、调用工具、收集证据并产生最终答案。这一过程基于一个配备了可执行动作 A(包括搜索、浏览和回答动作)的正式环境 E。在每个轮次 t,Agent 生成一个轮次输出 ut=(τt,at),其中 τt 代表中间推理,at 是相应的工具或回答动作。交互历史 h<t 根据 Agent 的输出和环境的响应进行更新,形成一个捕捉推理、动作和观察完整序列的轨迹 H。
训练流水线的第一阶段是 agentic supervised fine-tuning (SFT),用于赋予模型基础的 agentic 能力。研究人员使用了来自先前建立的系统 REDSearcher 的轨迹,但应用了多阶段数据过滤和构建流水线,以减轻冗余、结构失配和噪声监督。清洗后的轨迹被序列化为自回归序列,模型使用标准的 next-token prediction 目标进行训练,损失函数仅在 Agent 生成的 token 上计算,即具体的推理轨迹 τt 和动作 at,同时对环境观察 ot 进行掩码处理。这确保了模型学习推理、工具使用和答案生成的结构化交互模式,而不会被无关或噪声的环境数据干扰。SFT 阶段为长程交互提供了稳定的基础,使模型能够有效利用有限的开源数据监督。
第二阶段采用 agentic reinforcement learning (RL) 来优化模型性能,并解决残留的失败模式,如格式错误、冗余推理和低效的工具使用。为了克服高质量开源 RL 数据匮乏的问题,研究人员采用了基于信息增益的策略优化(Information Gain-based Policy Optimization, IGPO),这是一种通过构建密集的轮次级奖励信号来提高数据效率的算法。该方法的核心是信息增益 (IG) 奖励,它根据每一轮对模型生成正确答案概率的提升程度来评估该轮次。形式上,轮次 t 的 IG 奖励被定义为当前策略在当前轮次前后,正确序列对数概率之差,从而捕捉该轮次对提高正确答案置信度的贡献程度。该奖励仅针对非回答轮次进行计算,而回答轮次则依赖于基于正确性的结果奖励(outcome rewards)。
为了进一步优化奖励设计,研究人员引入了一种浏览感知(browse-aware)的 IG 分配策略,该策略专门在浏览轮次计算 IG 奖励,并将其传播到自上次浏览动作以来的所有先前搜索轮次。这反映了在深度研究任务中,浏览动作与搜索动作具有不同的信息价值。此外,应用了轮次级格式惩罚,以确保所有轮次格式的一致性,避免在长轨迹中对格式正确的轮次进行粗粒度的不公平惩罚。随后,格式调整后的奖励在每个 rollout 组内进行归一化,以平衡轮次级 IG 与结果奖励的量级,并引入可选的 IG-Scale 机制,在结果监督较弱的情况下自适应地重新缩放 IG 奖励以保持平衡。
最终的奖励信号是一个折扣累积奖励 R~i,t,它通过对归一化和缩放后的轮次级奖励应用折扣因子 γ 来纳入未来的奖励信息。这种密集的监督信号被分配到轮次 t 策略生成输出中的每一个 token,从而在整个交互过程中实现有效的信用分配(credit assignment)。策略优化使用 IGPO 目标进行,该目标结合了 GRPO 风格的方法与轮次级信用分配。目标函数包含一个裁剪代理项以确保更新稳定,以及一个 KL 散度惩罚项以防止过度偏离参考策略。这一全面的奖励和优化框架使 DR-Venus 能够实现更高的执行可靠性,并将性能推向长程 agentic 任务的前沿。
实验
研究人员在涵盖深度研究、网页浏览和多步信息寻求的六个基准测试中评估了 DR-Venus,以验证 agentic SFT 和 RL 训练流水线的有效性。结果表明,在开源数据上进行高质量的 supervised fine-tuning 可以使 4B 小模型建立起足以媲美更大规模 Agent 的强大基线,而 agentic RL 则进一步增强了可靠性、工具使用的稳定性以及长程性能。最终研究发现,有效的数据利用和密集的奖励设计可以弥补模型规模的不足,使边缘规模的 Agent 能够获得极具竞争力的研究能力。
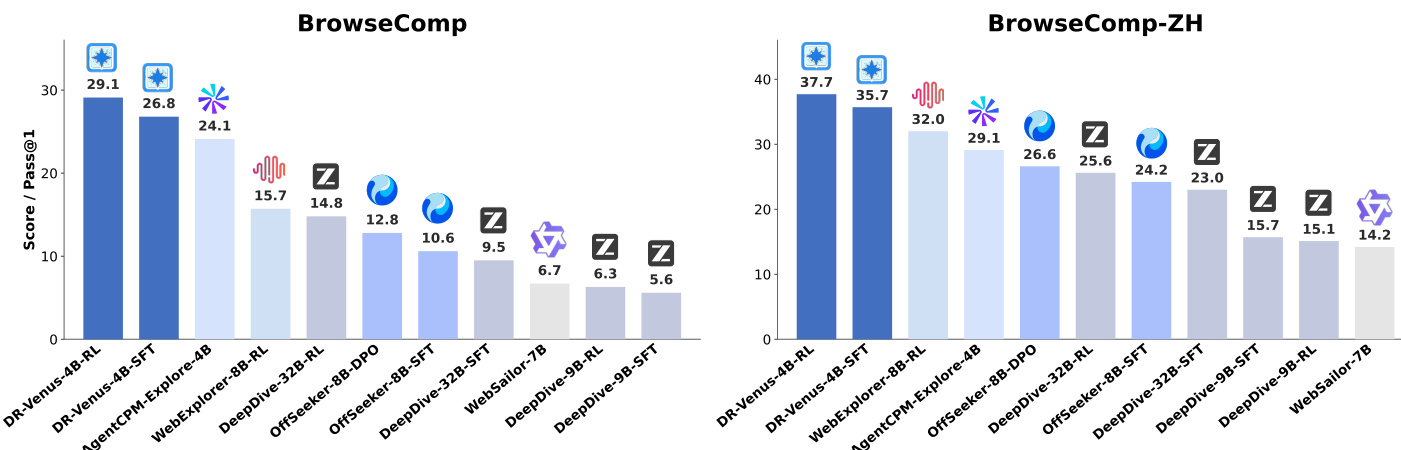
研究人员在两个基准测试中将小模型 Agent DR-Venus 与各种基线进行了对比,结果显示 DR-Venus-4B-SFT 建立了强大的基线,而 DR-Venus-4B-RL 进一步提升了性能。结果表明,在开源数据上的有效训练和 reinforcement learning 可以使小模型实现具有竞争力的性能,在需要深度研究和工具使用的长程任务中,性能往往能超越更大的模型。DR-Venus-4B-SFT 在多个基准测试中优于多个 4B–9B 参数的 Agent,并达到或超过了更大的 30B 级模型。Agentic RL 在大多数基准测试中提升了性能,这种提升与更好的格式化和更可靠的工具使用有关。DR-Venus-4B-RL 在 BrowseComp-ZH 上实现了高性能,超越了更大的模型,并在测试时扩展(test-time scaling)下展示了强大的能力。
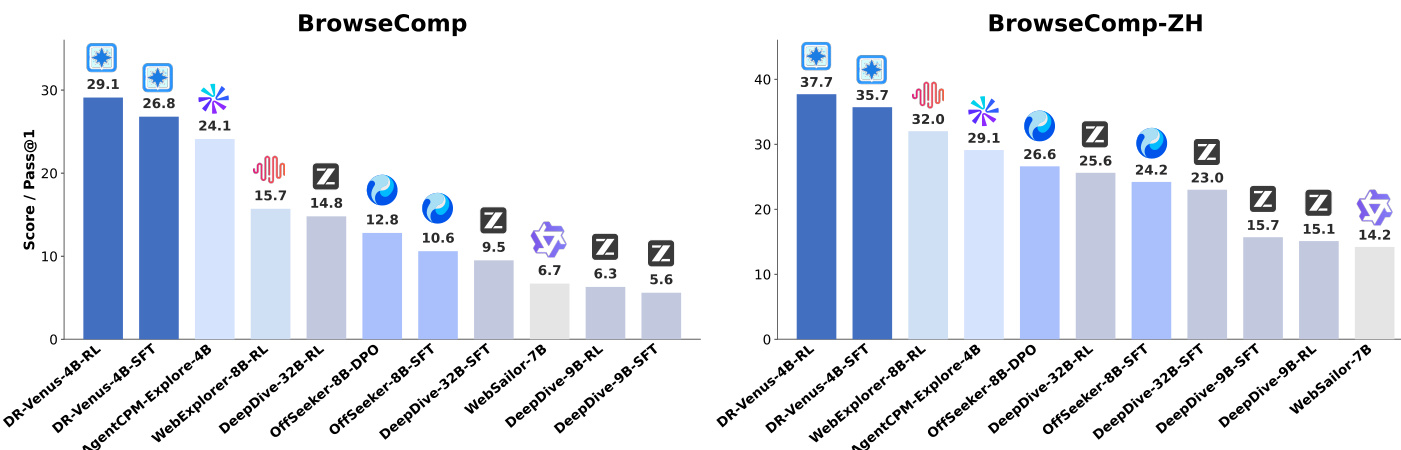
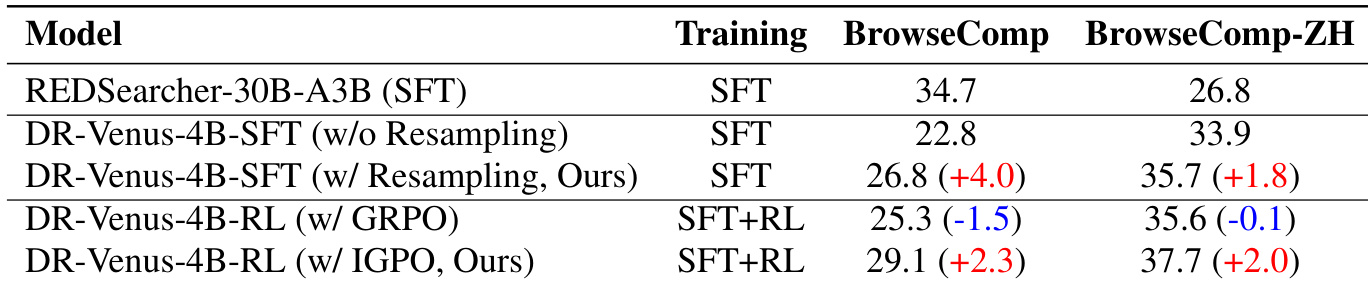
研究人员在两个基准测试中对比了具有不同训练配置的 DR-Venus 模型的性能,强调了重采样和 reinforcement learning 的影响。结果显示,在 supervised fine-tuning 期间加入重采样可以提升相对于基线的性能,而使用 IGPO 的 reinforcement learning 进一步增强了结果,尤其是在 BrowseComp 上。这些改进归功于更好的工具使用和更可靠的长程执行。在 supervised fine-tuning 期间进行重采样在两个基准测试中都提升了相对于基线的性能。使用 IGPO 的 reinforcement learning 带来了持续的增益,而 GRPO 则几乎没有提升。模型的性能与有效的工具使用(尤其是浏览)强相关,而这一点通过 reinforcement learning 得到了增强。
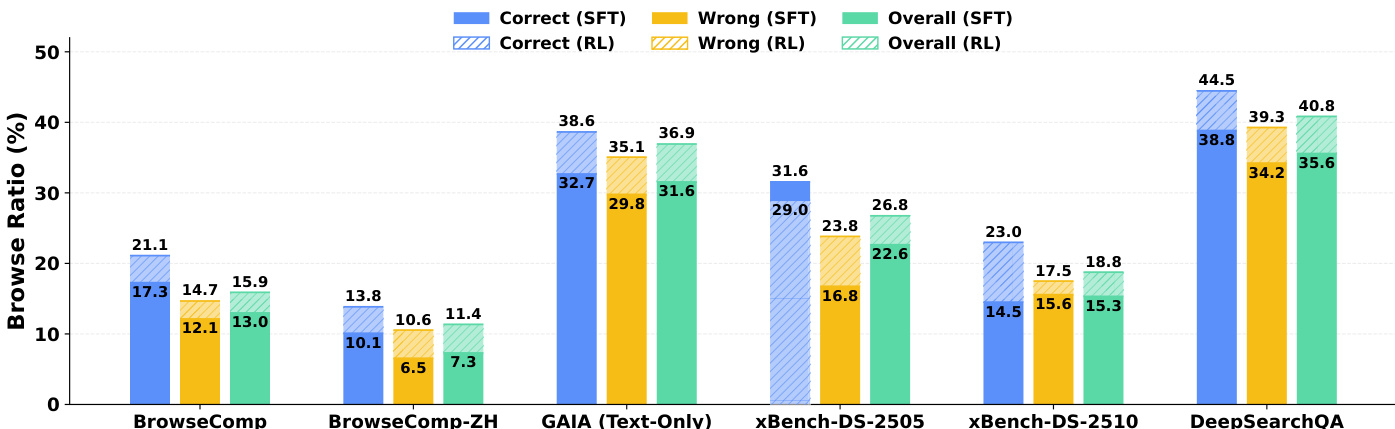
研究人员分析了 Agent 在多个基准测试中的工具使用行为,重点关注了在 supervised fine-tuning (SFT) 和 reinforcement learning (RL) checkpoint 下,正确轨迹与错误轨迹的浏览比例。结果显示,成功的轨迹始终表现出比失败轨迹更高的浏览比例,这表明更深入的证据检查对于任务成功至关重要。Reinforcement learning 通过提高整体浏览比例并加强浏览行为与任务正确性之间的对齐,增强了这一模式,特别是在 SFT 模型此前表现出反直觉趋势的场景中。在所有基准测试中,正确轨迹的浏览比例始终高于错误轨迹,表明更深入的证据收集与成功相关。Reinforcement learning 增加了整体浏览比例,并扩大了正确轨迹与错误轨迹之间的差距,从而提高了工具使用与任务结果的对齐度。RL 通过促进更有效的证据收集,纠正了工具使用中的反直觉模式(例如错误轨迹的浏览量多于正确轨迹的情况)。
研究人员对小规模深度研究 Agent DR-Venus 进行了全面评估,在多个基准测试中将其性能与更大的基础模型及经过训练的 Agent 进行了对比。结果显示,DR-Venus-4B-SFT 建立了强大的基线,在单个基准测试上优于多个 30B 级模型,而 DR-Venus-4B-RL 进一步提升了性能,达到了与更大模型竞争的结果,并证明了 reinforcement learning 在增强长程任务可靠性方面的有效性。分析强调,高质量的训练数据和有效的数据利用可以弥补模型规模的局限性,且 reinforcement learning 通过增强工具使用(特别是浏览)来改善证据收集和任务成功率。DR-Venus-4B-SFT 在单个基准测试上优于多个 30B 级 Agent,证明了模型规模并非性能的唯一决定因素。DR-Venus-4B-RL 在大多数基准测试中均优于 SFT 基线,增益归功于更好的格式准确性、工具使用和执行可靠性。Reinforcement learning 增加了浏览比例,特别是对于正确轨迹,表明证据收集得到改善且工具使用更加有效。
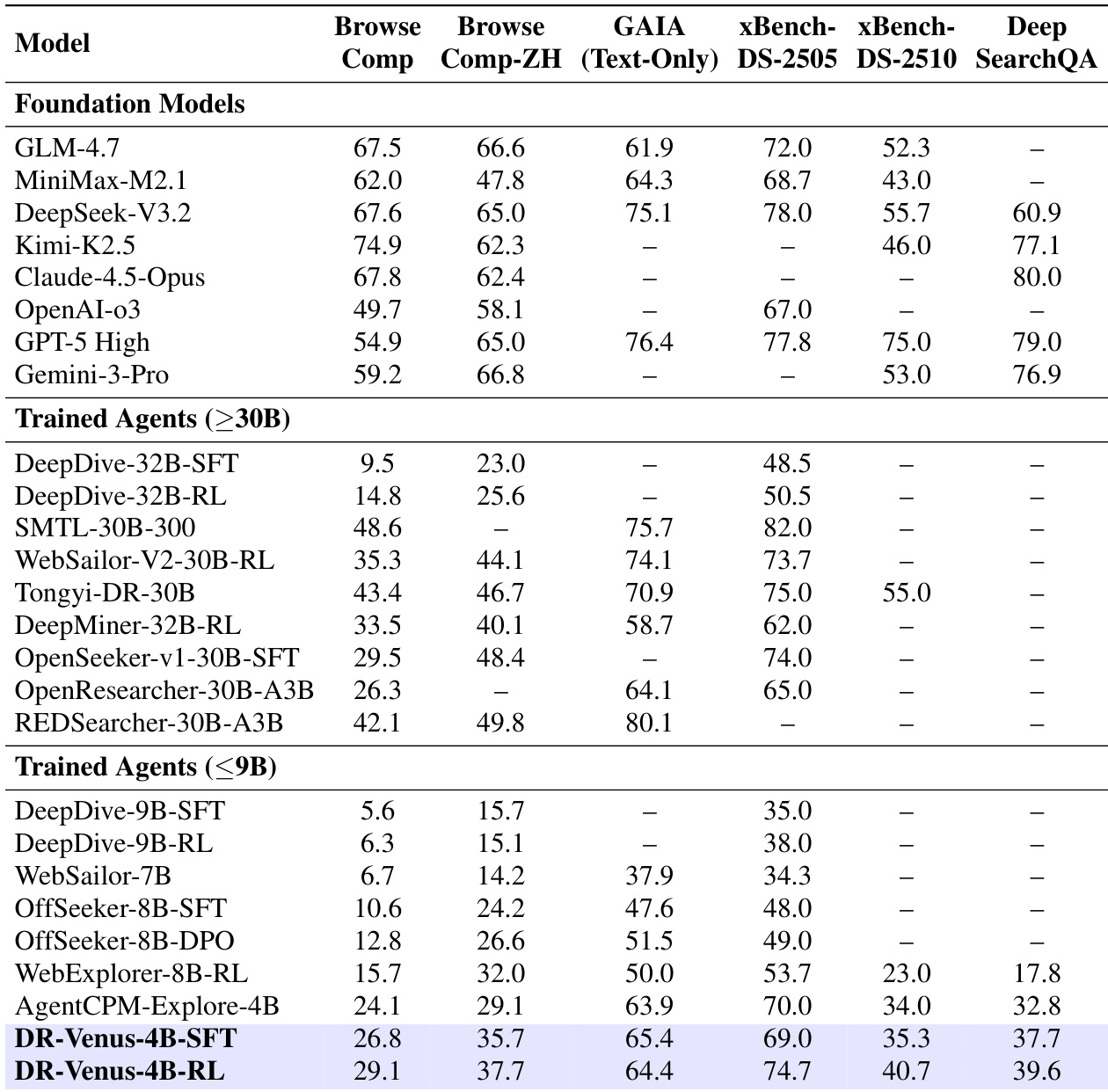
研究人员在多个基准测试中将 DR-Venus 小模型 Agent 与各种基线及更大的基础模型进行对比,以验证 supervised fine-tuning 和 reinforcement learning 的影响。结果表明,在开源数据上的有效训练和 agentic reinforcement learning 使小模型能够获得具有竞争力的性能,在长程研究任务中往往能超越大得多的模型。具体而言,reinforcement learning 通过增强工具使用的可靠性并利用增加的浏览行为促进更深入的证据收集,从而提高了任务成功率。