Command Palette
Search for a command to run...
AnyRecon:基于视频扩散模型的任意视角 3D 重建
AnyRecon:基于视频扩散模型的任意视角 3D 重建
Yutian Chen Shi Guo Renbiao Jin Tianshuo Yang Xin Cai Yawen Luo Mingxin Yang Mulin Yu Linning Xu Tianfan Xue
摘要
稀疏视图 3D 重建(Sparse-view 3D reconstruction)对于从随手拍摄的图像中进行场景建模至关重要,但对于非生成式重建(non-generative reconstruction)而言,这仍然是一个极具挑战性的任务。现有的基于扩散模型(diffusion-based)的方法通过合成新视角来缓解这一问题,但它们通常仅以一两个拍摄帧作为条件,这限制了几何一致性,并制约了在大规模或多样化场景中的可扩展性。我们提出了 AnyRecon,这是一个可扩展的重建框架,能够处理任意且无序的稀疏输入,在支持灵活的条件基数(conditioning cardinality)的同时,保留了显式的几何控制。为了支持长程条件约束(long-range conditioning),我们的方法通过预置的拍摄视图缓存(capture view cache)构建了一个持久的全局场景记忆,并取消了时间压缩,以在大视角变化下维持帧级对应关系。除了改进生成模型,我们还发现生成与重建之间的相互作用对于大规模 3D 场景至关重要。因此,我们引入了一种几何感知条件策略,通过显式的 3D 几何记忆和几何驱动的拍摄视图检索,将生成与重建进行耦合。为了确保效率,我们将 4 步扩散蒸馏(4-step diffusion distillation)与上下文窗口稀疏注意力(context-window sparse attention)相结合,以降低二次复杂度。大量实验表明,该方法在处理不规则输入、大视角间隔以及长轨迹场景时,展现出了稳健且具扩展性的重建能力。
一句话总结
AnyRecon 是一个可扩展的 3D 重建框架,能够从任意且无序的稀疏视图中进行重建。该框架利用持久的全局场景记忆和几何感知调节策略,以维持长程几何一致性和帧级对应关系,克服了现有基于 diffusion 的方法在可扩展性和一致性方面的局限。
核心贡献
- 本文介绍了 AnyRecon,这是一个用于从任意且无序的稀疏输入进行 3D 重建的可扩展框架,它利用带有全局场景记忆缓存的视频 diffusion 架构,以在巨大的视角变化中维持帧级对应关系。
- 提出了一种几何感知调节策略,通过包含显式 3D 几何记忆和几何驱动的捕获视图检索机制的闭环系统,将生成与重建耦合在一起。
- 该方法结合了 4 步 diffusion 蒸馏与上下文窗口稀疏 attention 以确保计算效率;实验表明,与现有基线相比,该方法在视图插值、外推以及大规模场景一致性方面表现出卓越的性能。
引言
稀疏视图 3D 重建对于将随机、不规则的捕获图像转化为沉浸式数字环境至关重要。虽然近期的基于 diffusion 的方法尝试通过合成新视图来弥补这一差距,但它们通常仅依赖于一两个参考帧,这限制了其维持全局几何一致性以及扩展到大规模场景的能力。此外,现有的视频 diffusion 框架通常为序列数据设计,因此并不适用于任意稀疏输入的无序且非序列特性。
AnyRecon 是一个可扩展的框架,能够实现从任意数量的无序视图中进行高质量重建。该框架引入了一种视频 diffusion 架构,利用全局场景记忆缓存并移除时间压缩,以在巨大的视角间隙中维持帧级对应关系。为了支持大规模环境,该框架实现了一种几何感知调节策略,通过显式 3D 几何记忆和几何驱动的视图检索,在生成与重建之间建立了一个闭环。
数据集

AnyRecon 使用 DL3DV-10K 数据集进行训练,这是一个包含高质量 3D 室内外场景的大规模集合。数据集的处理和使用总结如下:
- 数据集组成与划分:原始视频序列被划分为每个包含 40 帧的片段(clips)。每帧的处理分辨率为 512 × 896。
- 调节策略:为了增强生成先验并模拟不规则的输入场景,该框架实施了随机调节采样策略。对于每个片段,第一帧被固定为基础参考帧,同时随机选择额外的 N 个视图(其中 N 在 2 到 4 之间)。
- 采样分布:为了平衡窄基线插值与宽基线合成,额外的调节视图采用双概率方法进行采样。有 50% 的概率从前 20 帧中选择索引,另有 50% 的概率从完整的 40 帧窗口中选择。
- 数据处理与训练对:选定的调节视图通过前馈重建模块以建立初始 3D 几何记忆。随后,将生成的点云观测投影到目标新视角上,以生成渲染图像和可见性掩码,这些构成了几何控制生成模型的最终训练对。
方法
AnyRecon 框架作为一个用于稀疏视图 3D 重建的闭环系统运行,旨在处理任意且无序的输入序列,同时在长轨迹中维持几何一致性。整体架构由三个主要阶段组成:初始几何构建、新视图生成和几何更新,这些阶段共同构成了一个迭代优化循环。如框架图所示,该过程始于从输入视图构建初始 3D 几何记忆 Mgeo,这些视图被组织成捕获视图库 Icap。初始几何通过前馈点图估计方法(如 VGGT 或 π3)建立,为场景提供基础表示。
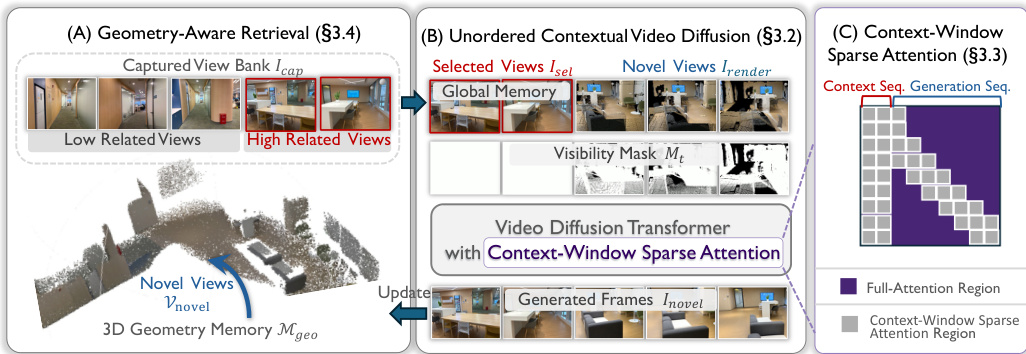
第二阶段涉及沿用户指定轨迹 Vnovel 合成新视图。为了管理计算复杂度,轨迹被分割,对于每个片段,几何感知检索过程从 Icap 中选择一个相关的视图子集 Isel。该检索过程由当前的 3D 几何记忆 Mgeo 引导,确保仅考虑对目标视角具有显著几何贡献的视图。选定的视图连同源自 Mgeo 的点云渲染 Irender 和可见性掩码 Mt,作为无序上下文视频 diffusion 模型的上下文输入。如第 3.2 节所述,该 diffusion 模块使用全局场景记忆来存储和查询检索到的参考视图,从而实现独立于时间顺序的灵活上下文注入。这种机制将生成过程与严格的时间依赖解耦,从而允许在任意视角间隙进行鲁棒合成。此外,该模型使用非压缩潜编码,其中逐帧的 2D VAE 保持了 latent token 与像素坐标之间的一一对应关系,避免了标准视频 diffusion 模型中因时间压缩而产生的特征缠绕。

为了确保计算效率,框架结合了两项关键优化。首先,上下文窗口稀疏 attention 机制将目标轨迹中每一帧的感受野限制在局部时间窗口和经选择性检索的几何对齐参考视图子集 Isel 内。通过将模型的 attention 集中在视觉相关的区域,这降低了与长序列相关的平方复杂度。其次,4 步 diffusion 采样策略通过将预训练模型蒸馏为仅需四步即可实现高质量生成的学生网络,从而加速推理。这是通过分布匹配蒸馏实现的,该方法通过使用带有停止梯度算子的伪回归目标来最小化学生分布与教师分布之间的 Kullback-Leibler 散度,以稳定训练。

最后一个阶段是几何更新过程,从新合成视图中重建的 3D 几何被用于更新全局记忆 Mgeo。该更新对于维持场景级一致性至关重要,因为它确保了新生成的轨迹片段被整合到全局场景表示中。如果没有此更新,重建的几何在不同轨迹片段之间会变得不完整且不一致,导致视觉失配。显式的记忆更新机制防止了误差累积和几何漂移,将每个新片段锚定在不断演化的全局结构中。这种递归循环——即新视图提供几何信息,而更新后的几何引导后续生成——实现了对长轨迹和大规模输入的扩展处理。几何感知检索策略根据视图对目标视角的几何贡献来选择调节视图,进一步增强了系统在遮挡和复杂空间布局下的鲁棒性。
实验
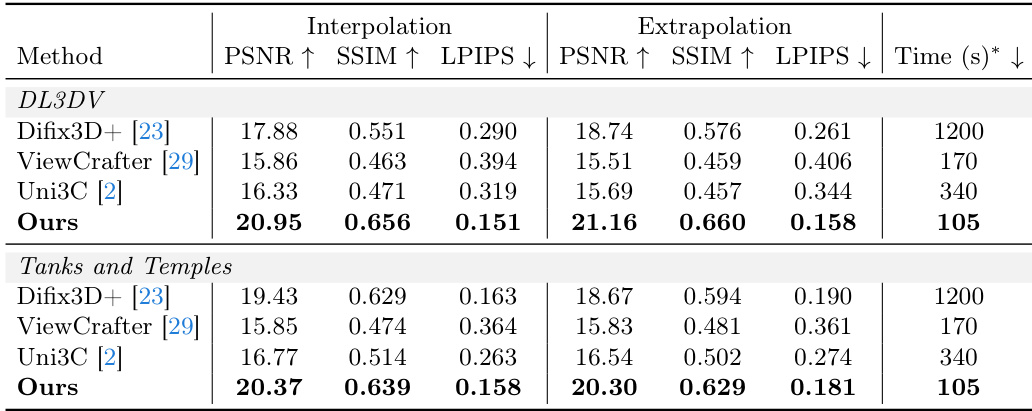
评估通过在 DL3DV 和 Tanks and Temples 数据集上使用插值和外推任务,将 AnyRecon 与最先进的基于 diffusion 的方法进行对比,以评估重建保真度和生成能力。结果表明,AnyRecon 通过利用全局场景记忆来抑制几何伪影并幻化出合理的场景内容,实现了卓越的结构完整性和外观一致性。消融实验进一步证实,避免时间压缩可以保留关键的高频细节,而模型蒸馏与稀疏 attention 的结合在不牺牲竞争力的视觉质量的前提下,显著提升了推理效率。
通过在两个数据集上针对插值和外推设置评估该方法,结果显示,与表现出结构不一致性和高延迟的基线相比,所提方法在所有指标上均实现了更优的质量,且推理速度显著加快。该方法在插值和外推任务中均优于所有基线,在所有评估指标上均达到了更高的质量。与其它方法相比,该方法展示了显著更快的推理速度,在两个数据集中均观察到最低的延迟。基线方法表现出结构不一致和较低的质量,特别是在处理巨大视角间隙和维持跨视图相干性方面。
消融实验评估了全局场景记忆对重建质量的影响。结果显示,引入全局场景记忆使所有指标均有所提升,表现为更高的 PSNR 和 SSIM 值以及更低的 LPIPS 分数,这表明具有更好的像素级准确度、结构完整性和感知质量。全局场景记忆的存在增强了模型在合成视图中保留精细细节并减少伪影的能力。引入全局场景记忆提高了 PSNR 和 SSIM,同时降低了 LPIPS,表明重建质量得到增强。与不含全局场景记忆的版本相比,带有全局场景记忆的模型实现了更好的结构完整性和感知质量。全局场景记忆有助于保留细粒度细节并减少合成视图中的伪影。

消融实验评估了不同时间压缩策略、推理效率技术以及全局场景记忆对重建质量和速度的影响。结果显示,完全的时间压缩会降低视觉保真度,而蒸馏与稀疏 attention 的结合在极小质量损失的情况下显著缩短了推理时间,且在全局记忆中保留原始捕获视图可提高结构和纹理的准确度。研究强调了效率与质量之间的权衡,突出了保留高频细节以及使用基于记忆的调节对于鲁棒 3D 重建的重要性。完全的时间压缩会导致视觉保真度明显下降,特别是在细粒度的结构细节方面。蒸馏与稀疏 attention 的集成在保持竞争力的重建质量的同时,大幅减少了推理时间。与依赖渲染点云图的基线相比,在全局记忆中保留原始捕获视图提高了结构完整性和纹理恢复能力。
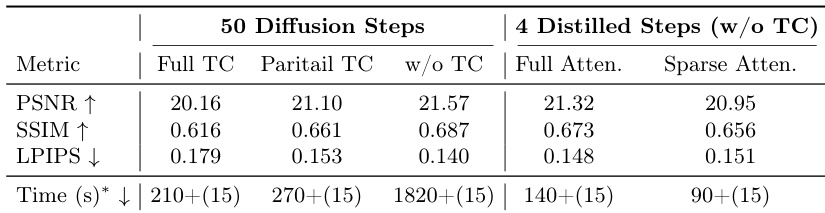
通过在插值和外推任务上的对比测试,以及对场景记忆和时间压缩策略的消融研究,评估了该方法与最先进的基于 diffusion 模型的性能。结果表明,所提方法在保持比现有基线更好的跨视图相干性的同时,提供了卓越的重建质量和更快的推理速度。此外,研究结果强调,利用全局场景记忆并将蒸馏与稀疏 attention 相结合,优化了计算效率与细粒度结构细节保留之间的平衡。