Command Palette
Search for a command to run...
PlayCoder:使 LLM 生成的 GUI 代码具备可玩性
PlayCoder:使 LLM 生成的 GUI 代码具备可玩性
Zhiyuan Peng Wei Tao Xin Yin Chenhao Ying Yuan Luo Yiwen Guo
摘要
大语言模型(LLMs)在代码生成领域已取得了显著成果,但其生成图形用户界面(GUI)应用程序(尤其是游戏)的能力研究仍显不足。现有的基准测试主要通过测试用例来评估正确性,这对于 GUI 应用程序而言是不够充分的,因为这类系统具有交互性、事件驱动性,并要求在连续的用户操作序列中实现正确的状态转换。因此,对其进行的评估应当考虑交互流(interaction flows)和 UI 逻辑,而非仅仅关注通过或失败的结果。为了研究这一问题,我们推出了 PlayEval,这是一个具有仓库感知能力(repository-aware)的基准测试,由 43 个使用 Python、TypeScript 和 JavaScript 编写的多语言 GUI 应用程序组成。不同于以往难以适配桌面环境的 GUI 基准测试,PlayEval 涵盖了六大主要 GUI 应用程序类别,并直接支持代码生成评估。我们进一步提出了 Play@k 指标,用于衡量在 k 个生成的候选结果中,是否至少有一个能够实现无逻辑错误的端到端游玩。为了支持可靠的评估,我们开发了 PlayTester,这是一个基于 LLM 的 agent,能够执行面向任务的 GUI 试玩并自动检测逻辑违规。针对 10 个最先进的代码生成 LLMs 的实验表明,尽管它们的编译成功率很高,但 Play@3 的得分接近于零,这揭示了它们在生成逻辑正确的 GUI 应用程序方面存在重大缺陷。为了解决这一局限性,我们提出了 PlayCoder,这是一个多 agent、具有仓库感知能力的框架,能够在闭环中对 GUI 应用程序代码进行生成、评估和迭代修复。PlayCoder 显著提升了开源和闭源模型的函数正确性(functional correctness)与语义对齐度(semantic alignment),其 Exec@3 最高达到 38.1%,Play@3 最高达到 20.3%。案例研究进一步表明,该框架能够发现传统指标未能察觉的隐性逻辑漏洞,并通过针对性的编辑进行修复。
一句话总结
为了提高可运行 GUI 应用程序的生成质量,作者提出了 PlayCoder,这是一个具备 repository-aware 能力的多 Agent 框架,利用闭环控制和 PlayTester agent 进行交互式、面向任务的评估,从而检测并修复传统单元测试无法发现的隐性逻辑缺陷。
核心贡献
- 本文引入了 PlayEval,这是一个具备 repository-aware 能力的评估数据集,包含跨越六个主要类别的 43 个多语言 GUI 应用程序,旨在促进桌面平台的代码生成任务。
- 提出了一种名为 Play@k 的新评估指标,通过确定 k 个生成的候选方案中是否至少有一个能够实现无错误的应用游戏玩法,来衡量端到端的逻辑正确性,并由名为 PlayTester 的基于 LLM 的 agent 提供支持,实现自动化的交互式试玩。
- 研究展示了 PlayCoder,这是一个具备 repository-aware 能力的多 Agent 框架,利用闭环控制来编写、评估和优化 GUI 代码,通过达到高达 20.3% 的 Play@3 分数,在功能正确性和语义一致性方面实现了显著提升。
引言
大语言模型在代码生成方面取得了重大进展,但开发功能完备的图形用户界面 (GUI) 的能力仍然有限。虽然传统的基准测试侧重于编译成功率和单元测试通过率,但这些指标无法捕捉交互式应用(如游戏)所需的有状态、事件驱动的逻辑。因此,模型生成的代码往往可以在没有错误的情况下运行,但包含关键的行为缺陷,例如碰撞检测失效或事件处理失败,而这些缺陷能够通过标准的函数测试。
作者通过引入 PlayEval 来填补这些空白,这是一个旨在通过分层行为测试来评估 GUI 应用程序的 repository-aware 基准测试。提出了一种新颖的 Play@k 指标,用于衡量生成的代码是否可以进行无逻辑错误的端到端游玩。为了实现这一过程的自动化,作者开发了 PlayCoder,这是一个多 Agent 框架,利用名为 PlayTester 的专门的基于 LLM 的 agent 来驱动交互式试玩并检测语义违规。通过将这些行为诊断结果反馈到优化循环中,PlayCoder 实现了针对性的自动程序修复 (APR),显著提高了生成的 GUI 应用程序的功能正确性和语义一致性。
数据集
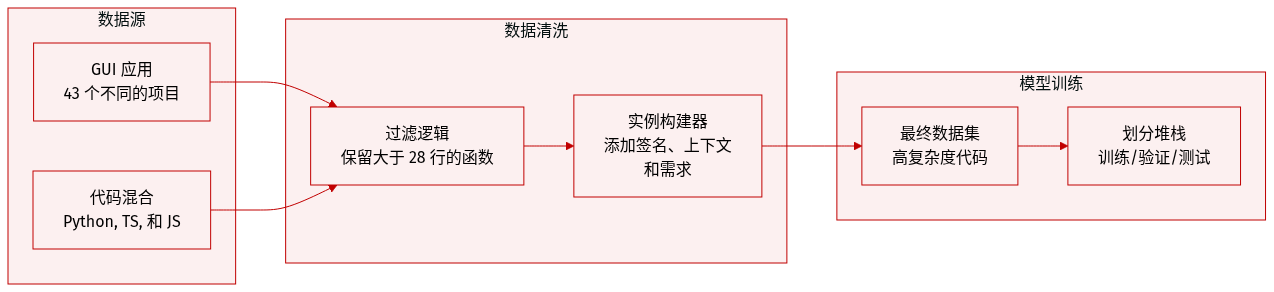
-
数据集组成与来源:作者引入了 PlayEval,这是一个由 43 个多样化 GUI 应用程序组成的 repository-aware 基准测试。该数据集涵盖三种编程语言:Python、TypeScript 和 JavaScript。应用程序分为六个类别:游戏模拟 (Game Emulation)、经典游戏 (Classic Games)、MMORPG 游戏、游戏引擎 (Game Engines)、独立应用程序 (Standalone Applications,如生产力工具和多媒体应用) 以及桌面小部件 (Desktop Widgets)。
-
选择与过滤标准:仓库的选择基于活跃的开发历史(至少 6 个月的维护)、社区验证(主要是拥有超过 100 个 GitHub stars 的项目)以及功能的完整性。为了确保基准测试侧重于行为丰富的代码而非简单的工具函数,作者应用了一项过滤规则,即在排除 docstrings 和装饰器后,函数必须至少包含 28 行代码。
-
数据处理与元数据构建:每个评估实例通过三部分结构构建:
- 函数签名 (Function Signature):精确的方法声明,包括参数类型和返回规范。
- 需求 (Requirements):使用 GPT-4o-mini 生成并由专家手动验证的关于函数用途和行为的自然语言描述,以确保高质量。
- 仓库上下文 (Repository Context):从代码库中提取的相关 import、类定义和相关函数。为了维持真实的开发环境,作者使用 git checkout 将仓库恢复到特定状态。
-
复杂度与评估:该数据集旨在通过高结构复杂度对模型进行压力测试,其特征是每个文件的平均圈复杂度为 10.2,平均嵌套深度为 11.0 层。对于 ground truth,作者利用了原始仓库的单元测试,但指出现实世界的项目通常测试覆盖率有限。
方法
作者提出了 PlayCoder,这是一个专为 repository-aware GUI 应用程序代码生成设计的多 Agent 框架,通过涉及两个专门 agent 的结构化“测试与修复”循环运行:PlayDeveloper 和 PlayRefiner。整体工作流程从需求描述、仓库上下文和函数签名开始,这些信息被结合起来生成候选代码。该代码经过行为测试,并根据结果由 PlayRefiner 执行自动程序修复 (APR) 以优化应用程序。该过程不断迭代,直到生成的代码同时满足语法和行为标准。
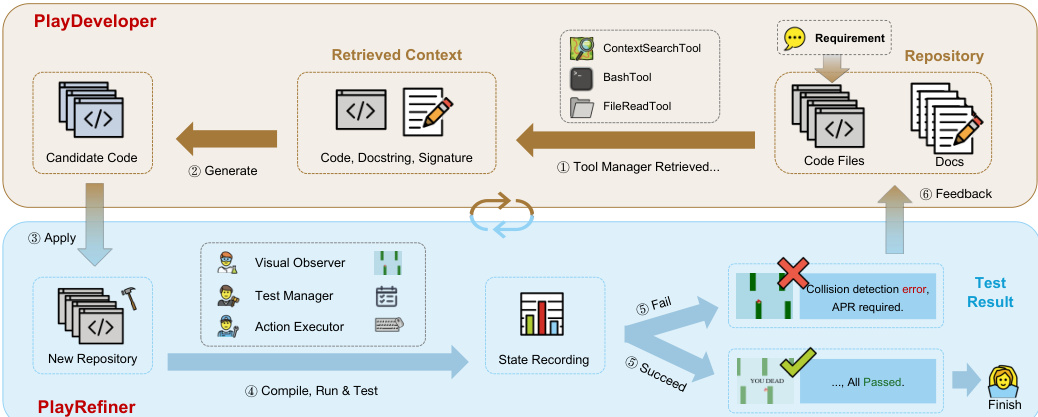
框架的架构如图所示,展示了两个 agent 之间的交互。PlayDeveloper 作为代码生成 agent,通过从仓库中检索相关的代码模式和模块结构,以感知上下文的方式运行。它利用了一个模块化的工具生态系统,包括用于检索代码示例和 import 模式的 ContextSearchTool、用于访问文件的 FileReadTool、用于执行 shell 命令的 BashTool 以及用于维持对话会话的 ConversationTool。该 agent 使用带有标准需求-代码示例的 few-shot prompting 来生成具备 repository-aware 能力的代码。

PlayRefiner 作为自动程序修复 agent,负责诊断并修复测试过程中发现的行为问题。它协调一组核心工具:用于在修复期间检索 repository-aware API 和 import 模式的 ContextSearcher、用于语法和 AST 检查的 Validator,以及用于在沙箱中运行程序以捕获运行时和行为信号的 Executor。修复过程遵循五个阶段的循环:诊断 (Diagnosis) 将编译器输出、运行时日志和测试报告汇总为可操作的失败摘要;补丁生成 (Patch Generation) 在检索到的上下文指导下提出最小化编辑;补丁应用 (Patch Application) 原子化地写入更改;构建与运行时验证 (Build & Runtime Validation) 编译并执行应用程序;迭代优化 (Iterative Refinement) 重复此循环,直到达到固定预算或满足行为标准。
行为测试阶段使用 PlayTester 框架进行,该框架集成了三个专门组件。Visual Observer 通过使用平台特定 API 的截图来捕获应用状态,并缓存最近的帧以检测状态变化。Action Executor 将测试策略转化为具体的 GUI 操作(如点击、输入和滚动),并包含安全机制。Test Manager 使用视觉语言模型,通过处理截图和文本上下文来规划测试并生成策略,并针对目标驱动型(如游戏)和覆盖率驱动型(如非游戏应用)测试方案设有不同的 prompt 模板。整个过程由 AgentTrajectory 工具提供全面的日志支持,该工具记录了 LLM 交互、工具使用和执行轨迹,从而实现诊断和可重复性。应用程序在具有确定性种子 (deterministic seeding) 的沙箱环境中执行,以确保评估的公平性和可重复性。
实验
研究人员使用 PlayEval 基准测试,针对各种最先进的 LLM 和 agentic 基准模型,评估了专为 GUI 代码生成设计的多 Agent 框架 PlayCoder 的有效性。实验验证了将自动程序修复与基于视觉的行为测试相结合的必要性,以检测传统单元测试无法捕获的隐性逻辑故障。结果表明,PlayCoder 在多种编程语言中均显著优于现有方法,并通过在每个消耗的 token 上实现更高的行为正确性,提供了卓越的成本效益。
表格展示了 PlayEval 基准测试的详细分解,该基准测试包含跨越六个类别的 43 个项目,包括游戏模拟、经典游戏和 MMORPG 游戏。项目在规模和复杂度上存在显著差异,代码行数、函数数量和类数量等指标在不同类别间表现出实质性差异,该基准测试总计包含 2,104 个测试用例。基准测试涵盖了复杂度各异的六个类别,包括游戏模拟、经典游戏和 MMORPG 游戏。项目规模在不同类别间存在显著变化,部分项目超过 120,000 行代码,而其他项目不足 3,000 行。所有项目共计 2,104 个测试用例,每个项目的测试用例数量从 24 到 1,539 不等。

作者在 GUI 应用程序代码生成基准测试上评估了各种语言模型和增强方法,重点关注执行、通过率和行为验证指标。结果显示,即使是性能顶尖的模型,其行为正确率也很低,且现有的增强策略带来的提升有限,这凸显了生成语义正确的 GUI 应用程序所面临的挑战。所提出的 PlayCoder 框架通过将自动程序修复与动态 GUI 测试相结合,在不同模型和语言中均优于所有基准模型,展示了卓越的有效性和成本效益。顶尖模型的行为正确率较低,在所有语言中,从执行到行为验证的性能均出现大幅下降。现有的增强方法相对于基础模型仅提供有限且不一致的改进,未能弥补 GUI 应用程序的性能差距。PlayCoder 在不同模型和语言中均优于所有基准,在行为验证方面实现了最高的有效性和成本效益。
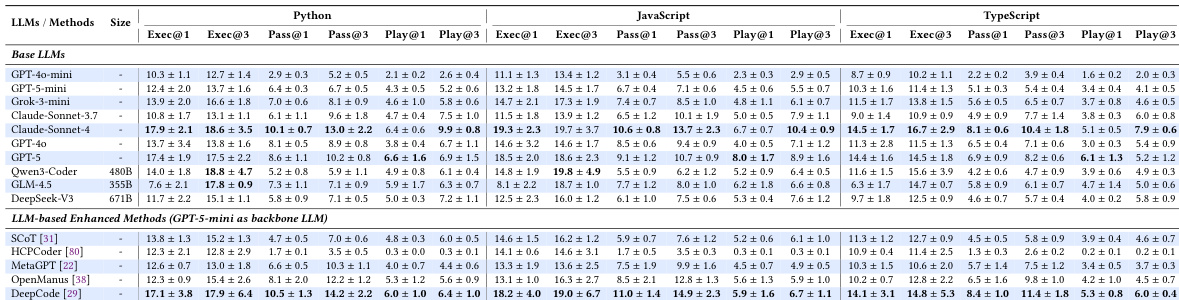
{"summary": "作者在 GUI 应用程序开发基准测试上评估了各种 LLM 和代码生成方法的性能,重点通过交互式测试衡量行为正确性。结果表明,现有方法在行为验证方面表现挣扎,特别是在 TypeScript 中;而提出的 PlayCoder 框架通过结合自动程序修复、视觉反馈和动态交互,显著优于基准方法。该框架在不同 LLM 之间表现出一致的有效性,并比其他 agentic 方法实现了更高的效率。", "highlights": ["PlayCoder 在不同 LLM 和编程语言下均优于所有基准方法,通过迭代修复和视觉反馈实现了卓越的行为验证。", "现有方法相对于基础模型的改进有限,在行为验证方面存在显著性能差距,尤其是在 TypeScript 等静态类型语言中。", "PlayCoder 在多样化的 LLM 架构中展示了强大的成本效益和一致的性能,强调了自动修复和 GUI 反馈组件的重要性。"]}
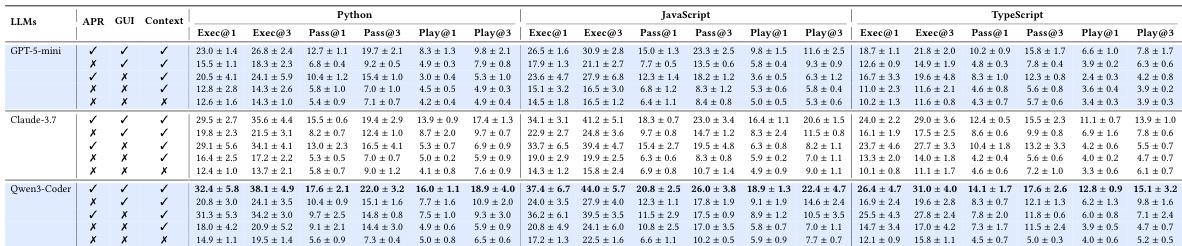
作者在交互式 GUI 应用程序基准测试上评估了各种大语言模型和代码生成方法,重点通过自动化测试衡量行为正确性。结果显示,即使是性能顶尖的模型,其行为验证率也很低,从基础执行到交互式测试的性能出现了大幅下降,且现有的增强策略提供的改进有限。所提出的 PlayCoder 框架通过将迭代修复与视觉反馈相结合,在多种语言和模型中均优于所有基准,展示了卓越的有效性和成本效益。PlayCoder 在多种编程语言和模型中,在执行和行为验证方面均显著优于所有基准方法。现有增强策略在行为正确性方面的改进有限,性能从执行到交互式测试时大幅退化。PlayCoder 在每个消耗的 token 上实现了更好的性能,与其它方法相比展示了极高的成本效益。

作者在交互式 GUI 应用程序基准测试上评估了各种代码生成方法的性能,重点关注执行、通过率和行为验证指标。结果显示,包括先进的基于 LLM 的方法在内的现有方法在行为正确性方面表现挣扎,特别是在 TypeScript 中,而提出的 PlayCoder 框架在所有指标上均表现出显著改进,并在不同模型间保持了一致的有效性。现有的代码生成方法在行为验证性能方面表现有限,尤其是在 TypeScript 中,大多数无法获得较高的 Play@k 分数。PlayCoder 在不同模型和编程语言中均优于所有基准方法,实现了卓越的执行和行为验证指标。该框架的有效性在多样化的 LLM 架构中是一致的,消融实验证实了自动程序修复和视觉反馈组件的关键作用。
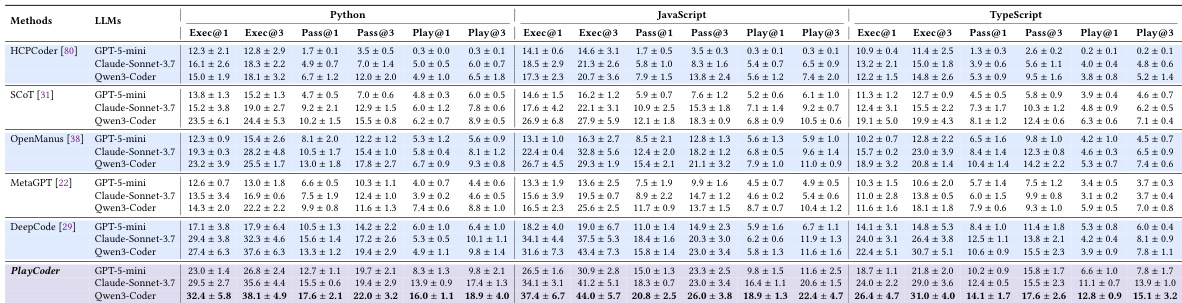
作者在 PlayEval 基准测试上评估了各种大语言模型和增强策略,该基准测试由从游戏模拟到 MMORPG 的多样化 GUI 应用程序项目组成。实验表明,现有方法难以实现行为正确性,从基础执行转向交互式测试时性能出现显著下降。相比之下,提出的 PlayCoder 框架通过将自动程序修复与视觉反馈相结合,优于所有基准,在多种编程语言和模型架构中展示了卓越的有效性和成本效益。