Command Palette
Search for a command to run...
UniT:迈向人类到人形机器人策略学习与世界建模的统一物理语言
UniT:迈向人类到人形机器人策略学习与世界建模的统一物理语言
Boyu Chen Yi Chen Lu Qiu Jerry Bai Yuying Ge Yixiao Ge
摘要
扩展人形机器人基础模型正面临着机器人数据匮乏的瓶颈。虽然海量的第一视角(egocentric)人类数据提供了一种可扩展的替代方案,但由于运动学(kinematic)的不匹配,如何跨越异构具身(cross-embodiment)之间的鸿沟仍然是一个根本性的挑战。我们提出了 UniT(Unified Latent Action Tokenizer via Visual Anchoring,通过视觉锚定的统一潜在动作 Tokenizer),这是一个为“人到人形机器人”迁移建立统一物理语言的框架。基于“异构运动学共享通用视觉后果”这一理念,UniT 采用了一种三分支交叉重建机制:动作分支通过预测视觉信息,将运动学锚定到物理结果上;视觉分支通过重建动作,从而过滤掉无关的视觉干扰因子(confounders)。同时,融合分支将这些经过纯化的模态协同整合到一个具身无关(embodiment-agnostic)的共享离散潜在空间中,用以表示物理意图。我们在两种范式下对 UniT 进行了验证:1. 策略学习(VLA-UniT):通过预测这些统一的 tokens,该方法有效地利用了多样化的人类数据,在人形机器人仿真基准测试和真实世界部署中,均实现了最先进(state-of-the-art)的数据效率和鲁棒的分布外(OOD)泛化能力,并显著展示了零样本(zero-shot)任务迁移能力。2. 世界模型(WM-UniT):通过以统一 tokens 作为条件来对齐跨具身动力学,实现了直接从人类到人形机器人的动作迁移。这种对齐确保了人类数据能够无缝转化为增强的人形机器人视频生成的动作可控性。最终,通过诱导高度对齐的跨具身表示(通过 t-SNE 可视化经验证实,人类与人形机器人的特征收敛到了一个共享流形中),UniT 为将海量人类知识提炼为通用人形机器人能力提供了一条可扩展的路径。
一句话总结
UniT 通过一种三分支交叉重构机制为人类到人形机器人的迁移建立了统一的物理语言,该机制将异构运动学锚定到离散潜在空间中的共享视觉结果,从而通过 VLA-UniT 实现高效的策略学习,并通过 WM-UniT 实现直接的世界建模,以达到鲁棒的零样本任务迁移。
核心贡献
- 本文引入了 UniT,这是一个通过与具体体现无关(embodiment-agnostic)的物理意图的共享离散潜在空间,为人类到人形机器人的迁移建立统一物理语言的框架。
- 该方法利用了一种三分支交叉重构机制,其中动作预测视觉以将运动学锚定到物理结果,而视觉重构动作以过滤无关的视觉混淆因子。
- 实验表明,该框架在策略学习中实现了最先进的数据效率和鲁棒的分布外泛化能力,同时在世界建模范式中实现了直接的人类到人形机器人动作迁移。
引言
扩展人形机器人基础模型目前受到高质量机器人数据稀缺的限制。虽然大规模的人类运动数据集提供了一种可扩展的替代方案,但由于运动学不匹配和自由度不同,弥合人类与人形机器人体现之间的差距非常困难。现有方法通常依赖于劳动密集型的动作重定向,或者受到分布偏移以及光照和纹理等视觉混淆因子的影响。UniT(通过视觉锚定的统一潜在动作 Tokenizer)框架被用于建立一种共享的物理语言。通过采用三分支交叉重构机制,UniT 将异构运动学锚定到通用的视觉结果,有效地将与具体体现无关的物理意图提取到统一的潜在空间中。
数据集
利用多个数据集在仿真和真实世界环境中训练并评估模型:
-
数据集组成与来源
- RoboCasa GR1 台面仿真: 一个包含 24 个台面任务的基准测试,包括 18 个拾取与放置重排任务和 6 个关节任务(如打开橱柜或微波炉)。
- EgoDex 数据集: 用于研究人类到人形机器人迁移的人类演示集合。包括 basic_pick_place 子集(27,419 条轨迹)和 pouring 子集(3,205 条轨迹)。
- DROID 数据集: 一个大规模数据集,包含来自 564 个场景的 95,599 条多样化轨迹,由约 76,000 条成功轨迹和 19,000 条失败轨迹组成。
- 专用机器人数据: 用于预训练的 32,000 条机器人轨迹集合。
-
训练与评估方案
- 预训练: 模型在 32,000 条专用机器人轨迹和 30,000 条 EgoDex 轨迹的混合数据上进行预训练。
- 协同训练与微调: 对于人类到人形机器人的迁移,将 EgoDex basic_pick_place 子集与少量样本(few-shot)机器人子集(2,400 条轨迹)结合进行协同训练,随后仅在机器人数据上进行微调。
- RoboCasa 评估划分: 在两种方案下进行测试:全量数据(24,000 条轨迹)和少量样本(2,400 条轨迹)。
- 真实世界验证: 针对“拾取与放置”和“倾倒”两个特定任务,每个任务收集 120 条机器人轨迹。
-
泛化与测试场景
- RoboCasa 泛化: 测试涵盖三个维度:未见外观(新纹理)、未见组合(新的物体与容器配对)以及未见物体类型(新的物体类别)。
- 真实世界分布外 (OOD) 测试: 评估五个泛化维度:几何(新的 3D 形状)、干扰物(带有额外物体的场景)、目标(替代的放置目的地)、背景(变化的桌面纹理)以及组合(在多个已知物体中的指令遵循)。
方法
提出 UniT,这是一个统一的物理语言框架,旨在通过共享的离散潜在表示弥合人类与人形机器人动作空间之间的差距。UniT 的核心是一个视觉锚定的三分支 tokenizer,它将异构动作映射到统一的潜在空间,从而实现策略学习和世界建模的跨体现迁移。整体框架的操作流程是:首先使用具有共享 codebook 的残差量化 VAE (RQ-VAE) 将观测转换、动作和融合的视听运动特征编码到共享的离散潜在空间中。这一过程由交叉重构机制引导,以确保不同模态和体现之间的一致性。参考框架图 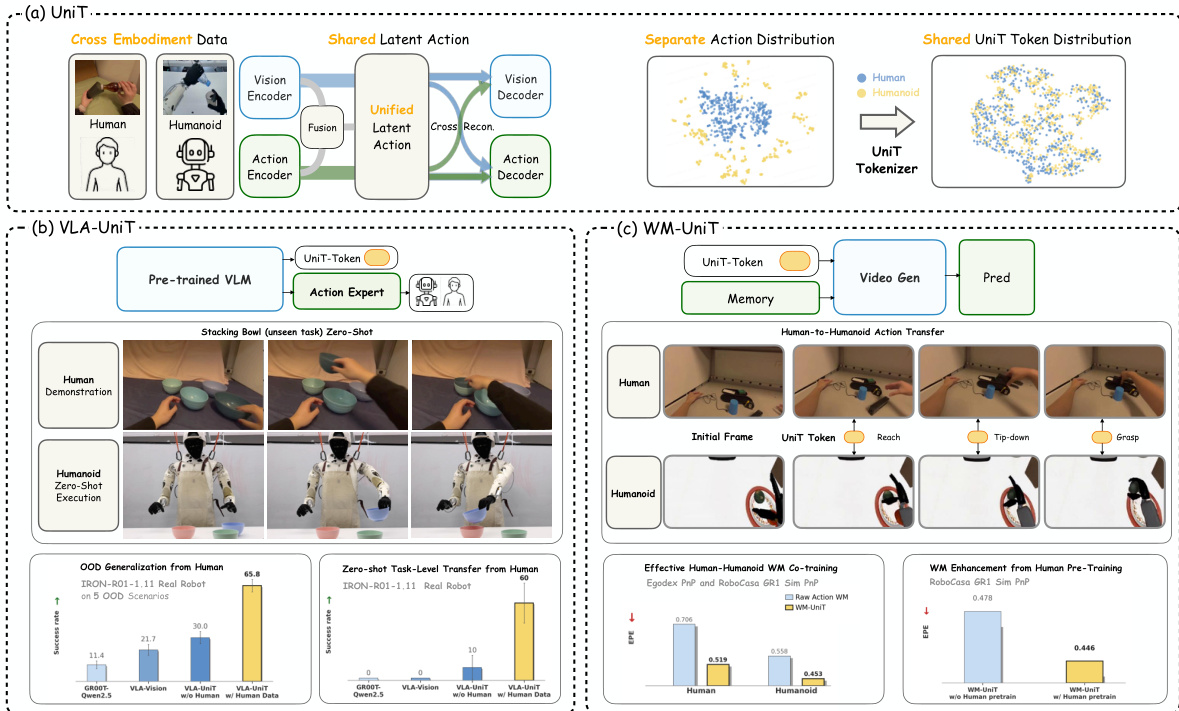 。
。
UniT tokenizer 架构由三个并行分支组成:视觉分支、动作分支和融合分支。视觉分支 Ev 作为逆动力学模型 (IDM),通过输入视觉观测对 (ot,ot+k) 的冻结 DINOv2 特征,提供跨不同体现的领域不变视觉锚点。动作分支 Ea 编码当前状态 st 和动作块 at:t+k。为了处理人类与人形机器人体现之间动作参数化的异构性,原始动作首先被填充到统一的最大长度,并通过体现特定的 MLP 进行投影,然后被总结为紧凑的潜在控制表示。融合分支 Em 结合视觉和动作分支的特征,生成融合的视听运动潜在表示,捕获互补的跨模态结构,从而产生更紧凑、更鲁棒的 token。如下图所示: 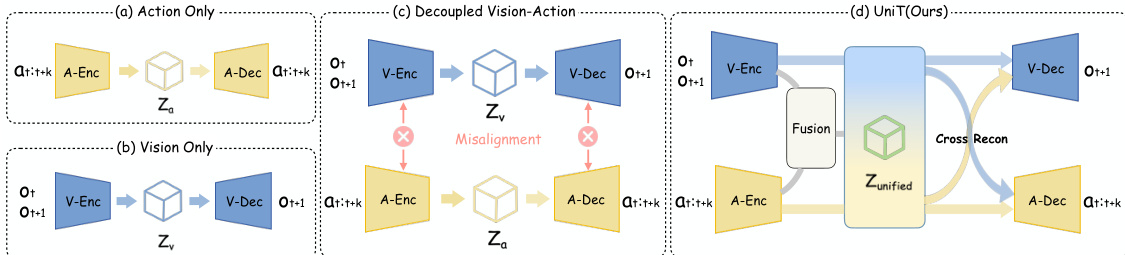 。
。
所有三个连续潜在表示都使用具有公共 codebook C 的残差量化 VAE (RQ-VAE) 量化到共享的离散空间中,从而产生统一的潜在动作 token。UniT 的核心机制是交叉重构,其中来自任何分支的每个量化 token z^i 都会由共享的视觉解码器 Dv 和体现特定的动作解码器 Dn 进行解码。视觉解码器在当前观测的条件下重构未来的视觉特征 f^t+k(i),并通过与地面真值未来特征 ft+k 的余弦相似度进行监督。动作解码器在当前状态 st 的条件下重构动作块 a^t:t+k(i)。这种双向约束强制要求捕获相似物理转换的 token 被映射到相近的 codebook 条目,无论体现如何,从而将异构的运动表示锚定到一个统一的流形中。训练目标聚合了所有三个分支的交叉重构损失和量化损失。
利用这种共享的 token 表示,UniT 被部署在两种互补的范式中。对于策略学习,VLA-UniT 将 UniT 集成到视觉-语言-动作 (VLA) 架构中。模型使用预训练的 VLM,根据当前观测和语言指令预测共享潜在空间中的 UniT token。随后,一个轻量级的流匹配(flow-matching)动作专家在相同的视觉-语言上下文中生成体现特定的动作。这种分解允许 VLM 学习统一的跨体现策略决策过程,而动作专家处理体现特定的控制生成。对于世界建模,WM-UniT 将 UniT token 用作通用的条件接口。动作分支的特征被用作动作条件视频生成模型的控制信号,而不是原始动作。这使得世界模型能够利用人类先验来预测未来的视觉观测,促进有效的人类到人形机器人动作迁移。使用 UniT token 作为控制接口确保了世界模型在部署时不会泄露未来观测,因为条件完全源自当前状态和动作块。 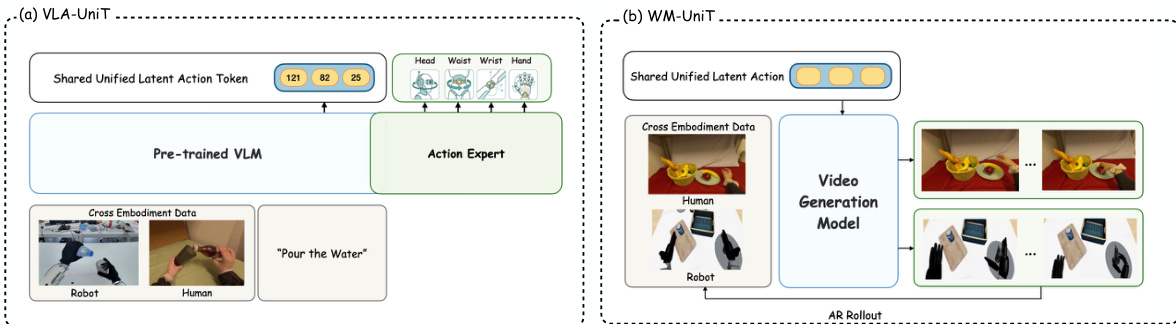
实验
实验在策略学习、世界建模和表示对齐任务中评估了 UniT tokenizer,以验证其建立统一物理语言的能力。结果表明,UniT 实现了卓越的数据效率、从人类到人形机器人演示的鲁棒跨体现迁移以及改进的零样本任务泛化。此外,研究结果证实,双向交叉重构以及视觉与动作之间的协同作用对于创建支持可控视频生成和与体现无关的下游表示的共享潜在空间至关重要。
表格比较了两种数据集下不同世界建模方法的效果:使用 DROID 的单体现设置,以及结合 EgoDex 和 RoboCasa-GR1 的人类-人形机器人协同训练设置。对于这两个数据集,WM-UniT 方法在大多数指标上始终优于基准方法,特别是在感知质量和可控性方面,这表明视觉锚定的 tokenization 提高了生成的保真度和跨体现对齐度。结果显示,与 Raw Action 和 WM-Action 相比,WM-UniT 实现了更高的 PSNR 和 SSIM,更低的 LPIPS 和 FVD,以及更好的 EPE,突显了通过交叉重构联合建模视觉和动作的优势。在协同训练场景中,WM-UniT 在人类和人形机器人数据上均表现出强劲性能,表明动力学在不同体现之间得到了有效迁移。WM-UniT 在单体现和人类-人形机器人协同训练设置下的多个指标中均取得了优异性能,表明生成质量和可控性的提升。与仅动作或原始动作基准相比,WM-UniT 中的视觉锚定 tokenization 带来了更好的感知相似度和更低的重构误差。WM-UniT 实现了有效的跨体现动力学迁移,这在协同训练设置中人类和人形机器人数据上一致的性能提升中得到了证实。
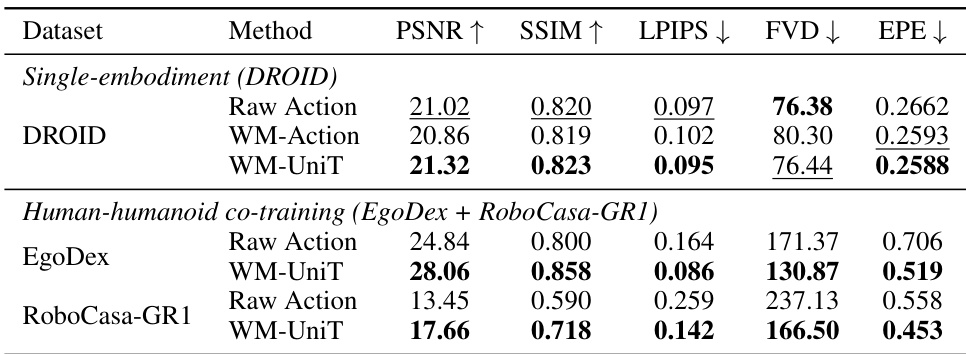
{"summary": "实验表明,VLA-UniT 在各种任务和设置中均取得了优于基准方法的性能。结果显示,VLA-UniT 在域内和分布外场景中均优于其他模型,在拾取与放置及关节操作等任务上的成功率有显著提高。该模型还表现出强大的数据效率,并受益于人类演示,从而增强了泛化和迁移能力。", "highlights": ["VLA-UniT 在域内和分布外任务中实现了比基准方法更高的成功率。", "VLA-UniT 显示出改进的数据效率,即使在训练数据有限的情况下也能表现良好。", "人类演示增强了 VLA-UniT 的性能,特别是在分布外和零样本泛化场景中。"]}
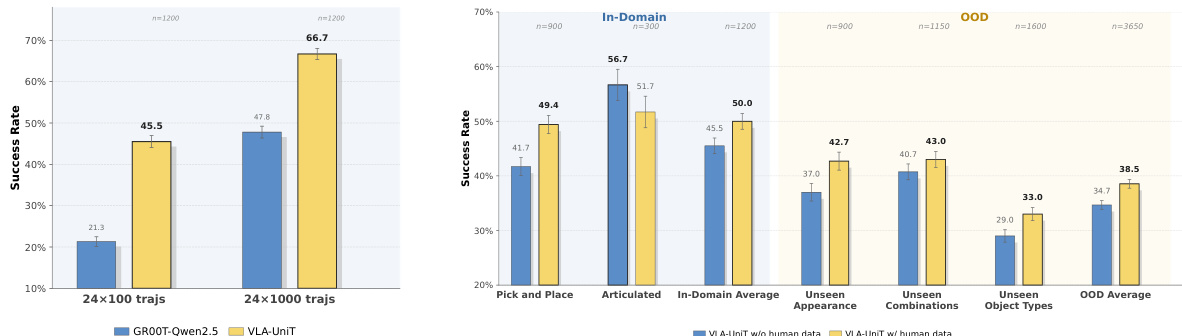
表格比较了 Raw Action 和 WM-UniT 在机器人到人类以及人类到机器人两个方向上,在语义、时间及几何一致性方面的跨体现条件性能。WM-UniT 在所有指标和两个迁移方向上均获得了比 Raw Action 更高的分数,表明在使用一种体现的动作作为条件来为另一种体现生成视频时,视频生成更加忠实且一致。结果突显了 UniT 在跨体现迁移过程中保持细粒度动作语义、量级敏感性和时间相干性的有效性。WM-UniT 在机器人到人类和人类到机器人的迁移方向上的语义、时间及几何一致性方面均优于 Raw Action。WM-UniT 在所有评估维度上均获得了更高的分数,表明实现了更忠实的跨体现视频生成。WM-UniT 相对于 Raw Action 的改进证明了视觉锚定 tokenization 在跨体现迁移过程中保持动作语义和细粒度运动细节方面的有效性。
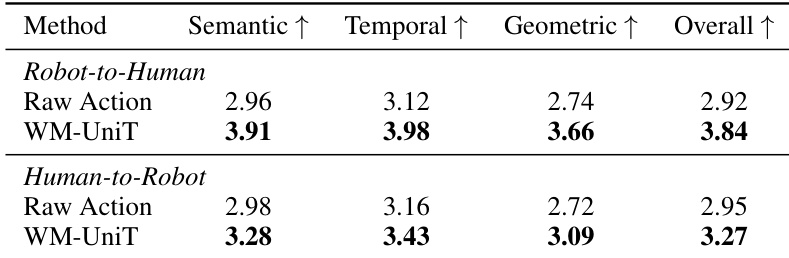
研究评估了 UniT 在实现策略学习和世界建模的跨体现迁移方面的有效性,重点关注其通过视觉锚定 tokenization 创建统一物理语言的能力。结果显示,与使用单模态或单向重构的基准方法相比,基于 UniT 的模型在域内和分布外设置中均取得了更优越的性能。视觉锚定表示实现了有效的人类到人形机器人迁移,提高了在真实世界部署中的泛化能力和零样本任务迁移能力。UniT 实现了有效的人类到人形机器人迁移,与单模态或单向基准相比,提高了域内和分布外性能。UniT 中的视觉锚定 tokenization 提供了一个共享的潜在空间,增强了跨体现对齐并实现了零样本任务迁移。基于 UniT 的模型在策略学习和世界建模任务中均优于基准方法,展示了双向交叉重构和视觉-动作协同作用的优势。
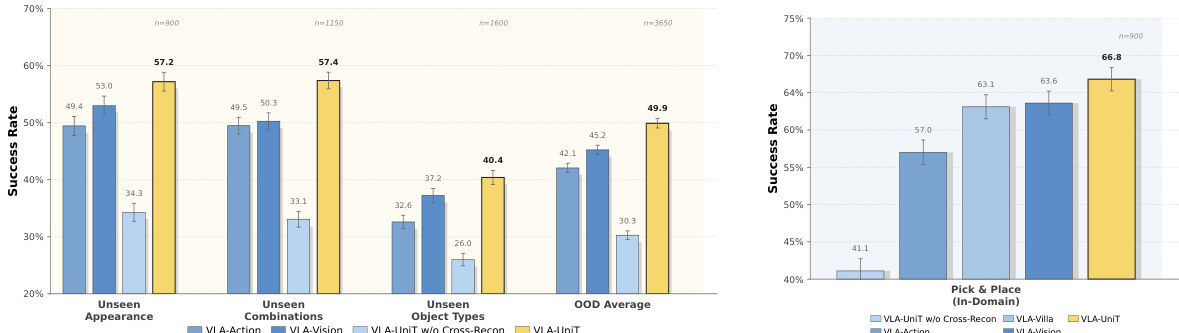
表格比较了世界建模系统 WM-UniT 在有无人类预训练两种配置下的表现。结果显示,包含人类预训练的完整配置在所有指标上均取得了更好的性能,表明人类数据增强了模型生成高质量且可控视频序列的能力。这种改进在帧保真度、感知相似度、视频真实感和可控性衡量标准中是一致的。带有人类预训练的 WM-UniT 在所有评估指标上均优于不带预训练的版本。完整配置实现了更高的 PSNR 和 SSIM,表明具有更好的帧保真度和感知相似度。完整配置显示出改进的可控性,表现为更低的 EPE 和 FVD 值。

实验在单体现和人类-人形机器人协同训练设置下对 WM-UniT 进行评估,以验证其在世界建模、跨体现迁移和策略学习方面的有效性。结果表明,视觉锚定 tokenization 在跨体现条件化过程中显著提高了感知质量、可控性以及细粒度动作语义的保留。此外,引入人类预训练增强了视频真实感并实现了有效的零样本任务迁移,在不同体现之间建立了统一的物理语言。