Command Palette
Search for a command to run...
CoInteract:通过空间结构化协同生成实现物理一致性的人机交互视频合成
CoInteract:通过空间结构化协同生成实现物理一致性的人机交互视频合成
Xiangyang Luo Xiaozhe Xin Tao Feng Xu Guo Meiguang Jin Junfeng Ma
摘要
合成人机交互(Human-Object Interaction, HOI)视频在电子商务、数字广告和虚拟营销领域具有广泛的实际应用价值。然而,目前的扩散模型尽管具备照片级的渲染能力,但在以下方面仍经常面临挑战:(i) 手部和面部等敏感区域的结构稳定性;(ii) 符合物理规律的接触(例如,避免手部与物体发生穿透)。我们提出了 CoInteract,这是一个端到端的 HOI 视频合成框架,能够根据人物参考图像、产品参考图像、文本提示词(text prompts)以及语音音频进行条件生成。CoInteract 在 Diffusion Transformer (DiT) 主干网络中引入了两种互补的设计。首先,我们提出了一种“人类感知混合专家模型”(Human-Aware Mixture-of-Experts, MoE),该模型通过空间监督路由将 tokens 分发给轻量级的区域专用专家,从而在极低的参数开销下提升了细粒度的结构保真度。其次,我们提出了“空间结构化协同生成”(Spatially-Structured Co-Generation),这是一种双流训练范式,通过联合建模 RGB 外观流和辅助 HOI 结构流来注入交互几何先验。在训练阶段,HOI 流会对 RGB tokens 进行注意力机制处理,其监督信号能够正则化共享的主干网络权重;在推理阶段,HOI 分支会被移除,从而实现零开销的 RGB 生成。实验结果表明,CoInteract 在结构稳定性、逻辑一致性和交互真实感方面均显著优于现有方法。
一句话总结
CoInteract 是一个用于人机交互(human-object interaction)视频合成的端到端框架。该框架利用集成了 Human-Aware Mixture-of-Experts 以保证结构保真度的 Diffusion Transformer 主干网络,以及通过双流空间结构协同生成(Spatially-Structured Co-Generation)范式注入几何先验,在结构稳定性、逻辑一致性和交互真实感方面显著优于现有方法。
核心贡献
- 本文引入了 CoInteract,这是一个用于语音驱动的人机交互视频合成的端到端框架,能够以人物和产品参考图像、文本提示词以及语音音频为条件进行生成。
- 将 Human-Aware Mixture-of-Experts (MoE) 直接嵌入 Diffusion Transformer 主干网络中,通过空间监督路由策略提高手部和面部等敏感区域的结构保真度。
- 提出了一种空间结构协同生成范式,利用双流训练方法通过辅助 HOI 结构流注入交互几何先验,在不增加推理开销的情况下实现了卓越的结构稳定性和交互真实感。
引言
合成人机交互 (HOI) 视频对于电子商务、数字广告和虚拟营销等应用至关重要。虽然目前的扩散模型可以生成逼真的结果,但在手部和面部等敏感区域往往难以维持结构稳定性,并且经常无法保持符合物理规律的接触,从而导致手部与物体相互穿透等问题。本文利用 Diffusion Transformer (DiT) 主干网络引入了 CoInteract,这是一个将结构先验直接嵌入生成过程的端到端框架。其贡献包含两个方面:实现 Human-Aware Mixture-of-Experts (MoE) 通过空间监督路由来提高手部和面部的细粒度保真度;提出一种空间结构协同生成范式,使用辅助结构流在训练期间引导模型学习交互几何,而不会在推理阶段增加计算开销。
方法
本文利用 CoInteract,这是一个用于语音驱动的人机交互 (HOI) 视频合成的端到端框架,该框架基于共享的 Diffusion Transformer (DiT) 主干网络来生成结构稳定且符合物理规律的视频。该框架运行在双重参考图像(角色身份和产品)以及保持时间连续性的运动帧上。与纯粹在 RGB 空间运行的传统视频扩散模型不同,CoInteract 通过统一的协同生成范式,显式地将交互结构和身体层面的一致性注入到共享的 DiT 主干网络中。

如下图所示,该框架在单个 DiT 主干网络内共同生成 RGB 外观流 zr 和辅助 HOI 结构流 zh。HOI 结构流被构建为一个去除纹理、类似剪影的 3 通道渲染图,通过将恢复的人体网格投影到图像平面并融合投影的物体掩码(mask)获得。这产生了一个像素对齐的结构目标,在丢弃 RGB 纹理的同时强调了交互边界。两个流使用具有相同 patch 大小且模态特定的 patch embedding 层进行 token 化,并输入到共享的 DiT 块中。在每个 DiT 块内,各流共享所有 transformer 参数,但采用流特定的调制参数(自适应层归一化中的 scale 和 shift),使主干网络能够在不复制完整模型的情况下,为外观和结构专门化特征统计量。
模型使用联合流匹配(flow-matching)目标进行训练,该目标同时监督两个流:
Lflow=Lr+λhLh. Lr=Et,z0,z1[∥vr−vθ(zr,t,t,c)∥22],Lh=Et,z0,z1[∥vh−vθ(zh,t,t,c)∥22].此处,v 表示目标速度场,t 是扩散时间步,c 表示包括文本、音频、双重参考图像和运动潜变量在内的条件输入。除非另有说明,超参数 λh 设置为 1。
为了无缝集成从历史运动、静态参考到双流生成潜变量等异构模态,该框架采用了 3D Rotary Positional Encoding (3D RoPE)。如下图所示,每个 token 都被分配了一个由 3D RoPE 编码的 3D 坐标 (h,w,t)。空间坐标的分配方式使得两个流沿宽度维度进行拼接,具有不同的水平坐标(例如,RGB 为 w∈[0,W],HOI 为 w∈[−W,0]),同时共享相同的垂直和时间索引,从而通过相对位置距离实现跨流对齐。通过构建时间轴来强制执行时间因果关系和参考锚定:历史运动帧 (t<0) 被分配负索引以鼓励因果连续性,而静态参考图像被映射到远场时间位置(例如,t=30,31),将其视为全局身份锚点。形式上,任何 token x 的位置编码为:
Pos(xi,j,k)=RoPE3D(hi,wi′,tk),其中 wj′ 考虑了 HOI 流中的虚拟宽度偏移。这种统一的映射鼓励注意力机制尊重所有输入之间的结构和时间关系。
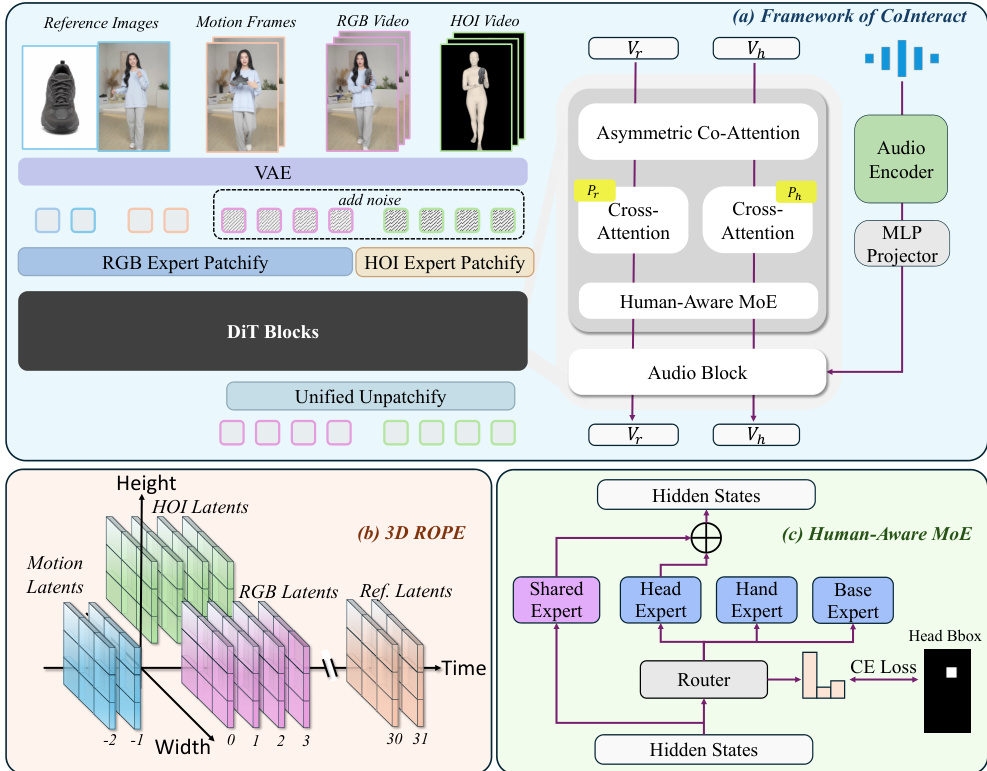
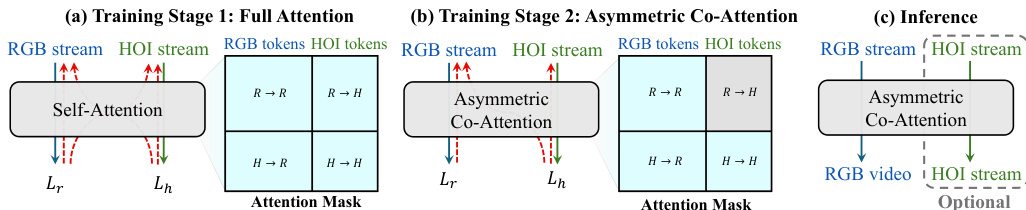
为了在注入交互结构监督的同时保持推理效率,该框架采用了带有非对称协同注意力(Asymmetric Co-Attention)机制的两阶段训练策略。在阶段 1,在两个流之间应用全双向注意力以建立耦合并实现快速收敛。在阶段 2,强制执行非对称注意力掩码。令 Tr 和 Th 分别表示 RGB 流和 HOI 流的 token 集合。掩码 M 定义为:
Mi,j=⎩⎨⎧1,1,0,if i∈Tr,j∈Tr,if i∈Th,j∈Tr∪Th,otherwise.在此掩码下,RGB 查询仅关注 RGB tokens,使 RGB 路径独立于 HOI 分支,从而可以在推理时以零开销移除。相反,HOI 查询会同时关注两个流,利用更清晰的 RGB 特征来预测交互结构。至关重要的是,Lh 通过 HOI←-RGB 交叉注意力反向传播到共享的 DiT 参数中,即使在移除 HOI 分支时,也能将交互结构监督传递给 RGB 生成器。
为了解决由于手部和面部的高频细节和关节复杂性导致的伪影问题,该框架结合了 Human-Aware Mixture-of-Experts (MoE) 模块。该模块通过空间监督路由器 R 将 tokens 路由到区域专门的专家。该模块包括一个作为快捷路径复用原始 DiT FFN 的共享专家(Shared expert),以及三个实现为小型 FFN 的轻量级专家(Head, Hand, Base),这引入了适度的参数开销。token xi 的路由概率计算如下:
G(xi)=Softmax(Wq⋅sg[hi]),其中 sg[⋅] 在路由前对隐藏状态应用停止梯度操作。利用面部和手部的边界框,路由器将对应区域内的 tokens 分配给 Ehead 或 Ehand,而其余 tokens 则由基础专家处理。通过交叉熵路由损失强制执行专门化:
Lroute=−i∑k∈{head,hand,base}∑1(yi=k)log(G(xi)k),其中 yi 是地面真值区域标签。总训练目标结合了流匹配损失和路由损失:
Ltotal=Lflow+ηLroute.
该框架的数据整理过程将原始 HOI 视频转换为配对的 RGB 和 HOI 结构表示。首先,使用 Qwen-Edit 进行实体解耦以创建独立的个人和产品参考,随后通过验证模块过滤不匹配的三元组。对于几何监督,使用 SAM3 获取物体掩码,并使用 SAM3D-body 恢复人体网格并将其投影到图像平面。投影的人体渲染与物体掩码融合,形成去除纹理的 HOI 结构流。RGB 视频和 HOI 流均通过预训练的 VAE 编码到共享的潜空间中。此外,现成的检测器提供面部和手部的边界框,作为训练期间 MoE 路由器的显式监督。
实验
评估通过定量指标、定性视觉分析和人类用户研究,将 CoInteract 与多个基线模型进行对比,以评估视频质量、人机交互 (HOI) 合理性、参考一致性和视听对齐度。结果表明,CoInteract 在保持高时间相干性和场景一致性的同时,实现了卓越的交互合理性、手部结构稳定性和身份保留。消融实验进一步验证了双流协同生成和 Human-Aware MoE 对于防止高频区域出现物理不合理性和结构崩溃至关重要。
通过一组涵盖视频质量、人机交互、参考一致性和视听对齐的指标,将 CoInteract 与多个基线进行对比。结果显示,CoInteract 在大多数指标上达到了最佳或具有竞争力的性能,尤其在交互合理性、手部质量和参考保真度方面表现出色。该方法在定量评估和用户研究中均表现出强大的性能,定性结果突出了其维持连贯的人机交互和结构一致性的能力。CoInteract 在大多数评估指标中获得了最高或具有竞争力的结果,特别是在交互合理性和手部质量方面。CoInteract 在参考一致性方面优于基线,与身份和产品参考均保持了强对齐。在涵盖所有标准的用户研究中,CoInteract 的平均排名最低,在交互合理性方面的优势最为显著。
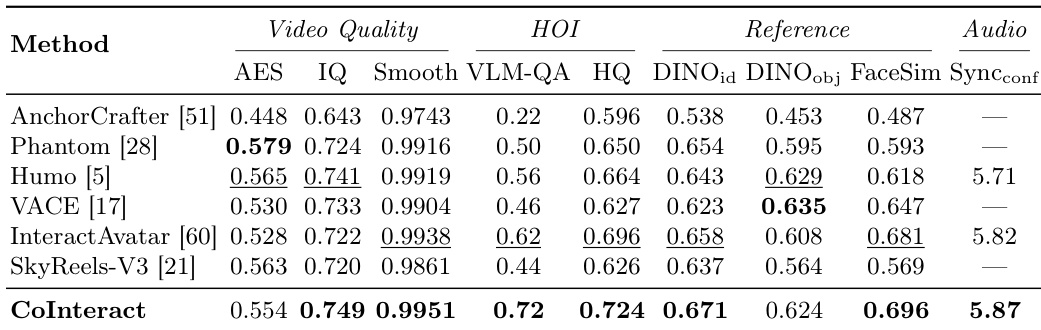
{"summary": "通过对 CoInteract 与多个基线进行定量和定性评估,重点关注交互合理性、参考一致性和视觉质量。结果显示,CoInteract 在大多数指标上实现了最佳性能,特别是在人机交互和结构保真度方面,用户研究排名证实了其在交互合理性和一致性方面的优越性。消融实验进一步证明了双流协同生成和 Human-Aware Mixture-of-Experts 架构等关键组件的重要性。", "highlights": ["CoInteract 在大多数指标上实现了最佳性能,特别是在交互合理性和结构保真度方面。", "该模型在用户研究排名中优于基线,尤其是在交互合理性和一致性方面。", "消融实验证实,双流协同生成和 Human-Aware Mixture-of-Experts 对于维持交互质量和结构稳定性都至关重要。"]}

通过消融研究评估 CoInteract 中关键组件的影响,对比了包含与不包含 Human-Aware MoE、HOI 协同生成和非对称注意力掩码的变体。结果显示,移除 HOI 流会导致交互合理性出现最显著的下降,而 MoE 组件对于维持细粒度结构保真度至关重要。非对称掩码在没有显著性能损失的情况下提高了效率,完整模型在多个指标上实现了最佳的整体结果。移除 HOI 流会导致交互合理性大幅下降,表明其对物理交互约束的重要性。Human-Aware MoE 组件对于维持细粒度结构保真度至关重要,特别是在手部和面部区域。与完整模型相比,非对称注意力掩码在极小的性能权衡下提高了推理效率。
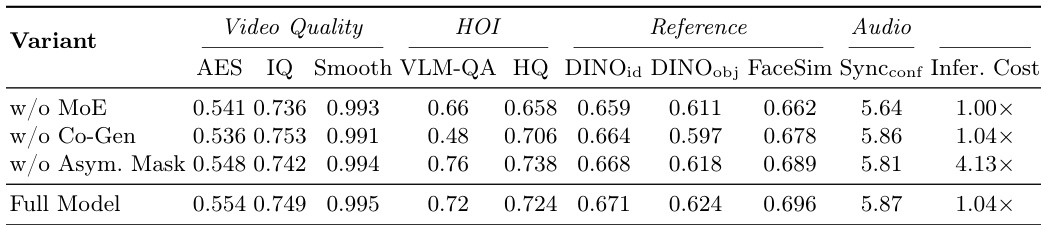
通过定量指标和用户研究对 CoInteract 与多个基线进行评估,以衡量视频质量、交互合理性和参考一致性。结果表明,CoInteract 在维持连贯的人机交互和结构保真度方面表现出色,同时紧密遵循身份和产品参考。消融研究进一步验证了关键组件的必要性,表明 HOI 协同生成流对于物理交互约束至关重要,而 Human-Aware MoE 对于细粒度结构细节必不可少。