Command Palette
Search for a command to run...
TEMPO:扩展大语言推理模型的测试时训练(Test-time Training)规模
TEMPO:扩展大语言推理模型的测试时训练(Test-time Training)规模
Qingyang Zhang Xinke Kong Haitao Wu Qinghua Hu Minghao Wu Baosong Yang Yu Cheng Yun Luo Ganqu Cui Changqing Zhang
摘要
测试时训练(Test-time training, TTT)在推理阶段针对无标签测试实例调整模型参数,从而不断扩展模型超越离线训练能力的边界。尽管取得了初步进展,但现有的针对大型推理模型(LRMs)的 TTT 方法很快就会进入瓶颈期,且无法从额外的测试时计算中获益。由于缺乏外部校准,随着策略模型的演进,自生成的奖励信号会日益发生漂移,从而导致性能停滞和多样性崩溃。我们提出了 TEMPO,这是一个 TTT 框架,它将针对无标签问题的策略优化与针对有标签数据集的周期性评论家(critic)重新校准交替进行。通过利用期望最大化(EM)算法将这一交替过程形式化,我们揭示了先前的方法可以被解释为缺失了关键校准步骤的不完整变体。重新引入这一步骤可以收紧证据下界(ELBO),并实现持续的性能提升。在多种模型家族(Qwen3 和 OLMO3)及推理任务上的实验表明,TEMPO 在保持高多样性的同时,将 OLMO3-7B 在 AIME 2024 上的表现从 33.0% 提升至 51.1%,并将 Qwen3-14B 从 42.3% 提升至 65.8%。
一句话总结
通过使用 Expectation-Maximization 算法将策略优化(policy refinement)与周期性 critic 重校准(critic recalibration)的形式化交替过程相结合,TEMPO 框架能够防止奖励漂移(reward drift)和多样性崩溃(diversity collapse),从而实现大型推理模型测试时训练(test-time training)的规模化。该框架将 OLMO3-7B 在 AIME 2024 上的表现从 33.0% 提升至 51.1%,将 Qwen3-14B 从 42.3% 提升至 65.8%。
核心贡献
- 本文引入了 TEMPO,这是一个测试时训练框架,利用 actor-critic 交替优化来防止大型推理模型中的奖励漂移和多样性崩溃。
- 该工作通过 Expectation-Maximization (EM) 算法将测试时训练过程形式化,并指出先前的方法之所以失败,是因为忽略了在有标签数据上进行周期性 critic 重校准这一关键的 E-step。
- 实验结果表明,TEMPO 能够在不同的模型家族中实现持续的性能提升,例如在保持高输出多样性的同时,将 OLMO3-7B 在 AIME 2024 基准测试中的准确率从 33.0% 提高到 51.1%。
引言
大型推理模型 (LRMs) 通常依赖于静态参数,无法纳入推理过程中获取的新知识。测试时训练 (TTT) 试图通过在无标签测试数据上调整模型参数来扩展推理能力,从而解决这一问题。然而,现有的 TTT 方法依赖于启发式的自生成奖励信号,随着模型的内部奖励偏离真实正确性,会导致性能进入平台期并引发输出多样性崩溃。本文利用 Expectation-Maximization (EM) 框架提出了 TEMPO,这是一种 TTT 方法,它将无标签问题的策略优化与有标签数据集上的周期性 critic 重校准交替进行。通过重新引入这一关键的重校准步骤,TEMPO 提供了一种稳定的训练信号,从而在各种推理任务中实现持续的性能增长并保持高输出多样性。
方法
受 Expectation-Maximization (EM) 算法的启发,本文提出了测试时 Expectation-Maximization 策略优化 (TEMPO),该框架通过在两个核心模块(critic 校准与策略优化)之间交替进行,使大型推理模型 (LRMs) 在测试阶段能够持续实现自我改进。整体架构以迭代循环的方式运行,模型利用有标签和无标签数据来优化其行为。
该过程始于使用有标签数据集 DL 通过带验证和奖励的强化学习 (RLVR) 程序对策略模型和 critic 模型进行初始化。随后,框架进入两个不同步骤的迭代交替。在被称为 critic 校准的 E-step 中,更新 critic 模型以确保其奖励预测保持在外部监督的基础上。这是通过在有标签数据 DL 上训练 critic 模型 Vϕ(x,yt) 来实现的,使其学习在 token 层面预测生成响应的正确性。通过最小化预测值与真实二值正确性指标之间的均方误差 (MSE) 来优化 critic,从而确保其提供可靠且经过校准的响应质量衡量标准。生成的 critic 作为正确响应后验分布的代理,使模型能够对其自身的生成内容进行重新加权。
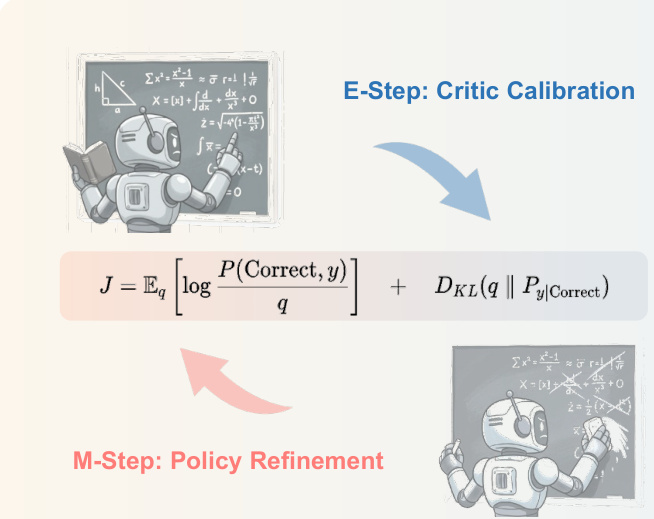
在 M-step(即策略优化)中,模型使用校准后的 critic 来指导其在无标签测试数据上的自我改进。通过最大化加权极大似然目标来更新策略参数 θ,其中权重源自 critic 对响应最后一个 token 的预测值 Vϕ(x,yT)。该目标通过策略梯度框架实现,其中 critic 的最终价值作为整个响应轨迹的真实奖励 R。为了稳定训练,每个 token y1:t 处的 critic 中间价值预测被用作基准 bt,每个 token 的优势 At 计算为最终奖励与基准之间的差值,At=R−Vϕ(x,y1:t)。随后利用该优势信号来更新策略,强化有助于产生高质量输出的行为。
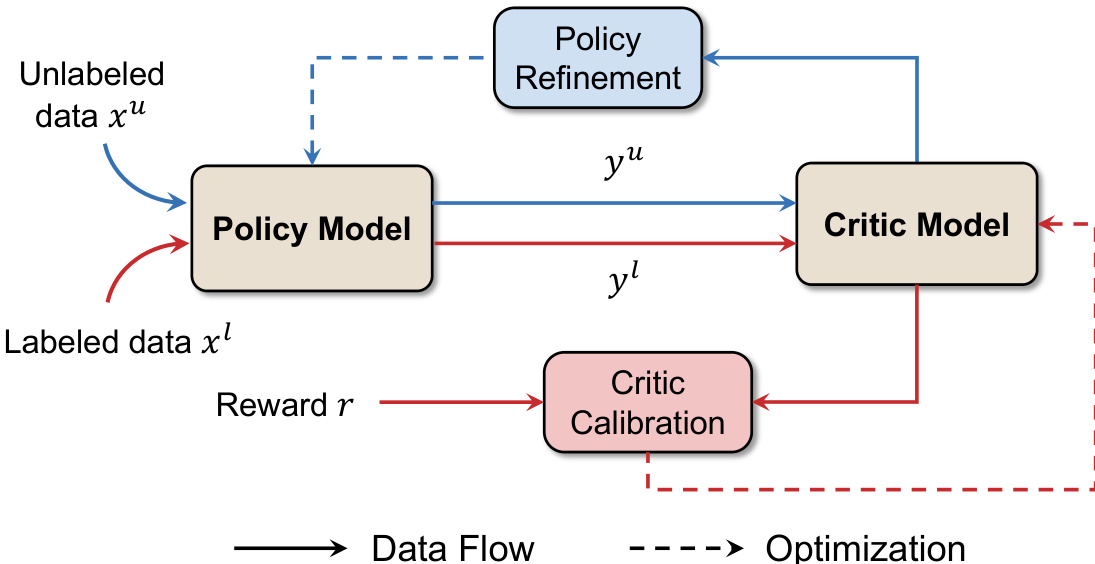
系统的数据流结构旨在支持这种交替过程。无标签数据 xu 被输入到策略模型中以生成响应 yu,随后由 critic 模型进行评估。有标签数据 xl 用于提供奖励 r,直接为 critic 校准过程提供信息。由虚线表示的优化流显示,critic 根据有标签数据进行周期性更新,而策略则根据 critic 对其自身输出的评估进行优化。这种校准与优化的持续循环使模型能够在开放式推理问题上实现持续的自我改进。
实验
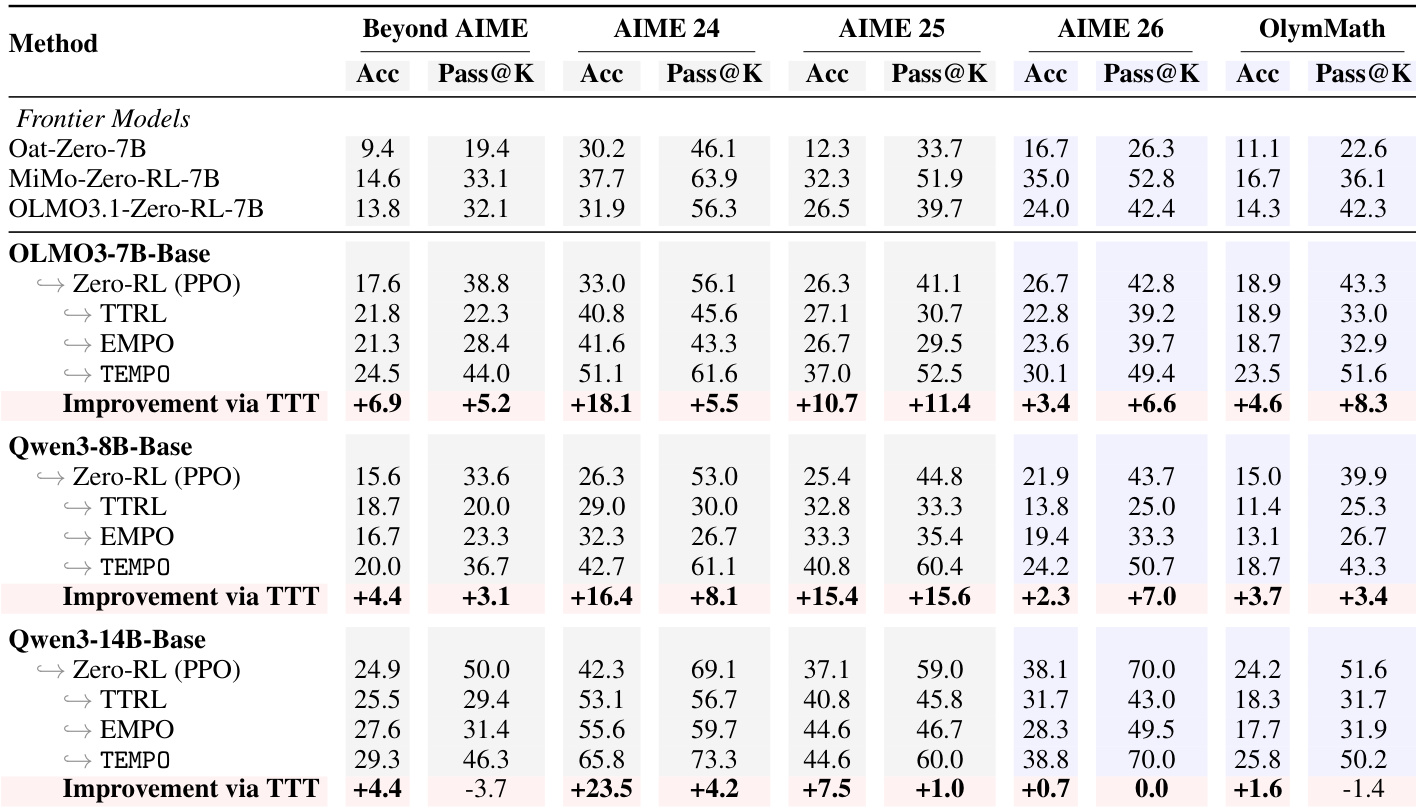
通过使用各种基础模型和基准测试,在数学和通用领域推理任务上对 TEMPO 进行评估,以验证其有效性。实验表明,TEMPO 实现了超越标准强化学习上限的持续可扩展性,并保持了高输出多样性,没有出现基准方法中常见的推理崩溃现象。此外,结果证实了该框架在不同推理领域中的通用性,并验证了其交替训练设计对于防止自我改进过程中 critic 失配的重要性。
通过在多个模型和基准测试上评估 TEMPO,证明了其在数学和通用推理任务中均一致优于基准方法。结果显示,TEMPO 相比 zero-RL 基准实现了显著提升,保持了高输出多样性,并通过测试时训练维持了性能增长而未进入平台期。该方法的有效性归功于其交替训练设计,该设计防止了奖励信号漂移并实现了持续的自我改进。TEMPO 在不同模型规模和基准测试中均一致优于基准,在准确率和 pass@k 指标上取得了实质性进展。TEMPO 在测试时训练期间保留了输出多样性,避免了其他收敛于狭窄推理模式的方法所出现的崩溃。TEMPO 中的交替训练设计对于持续改进至关重要,因为冻结的 critic 会导致性能随时间停滞。
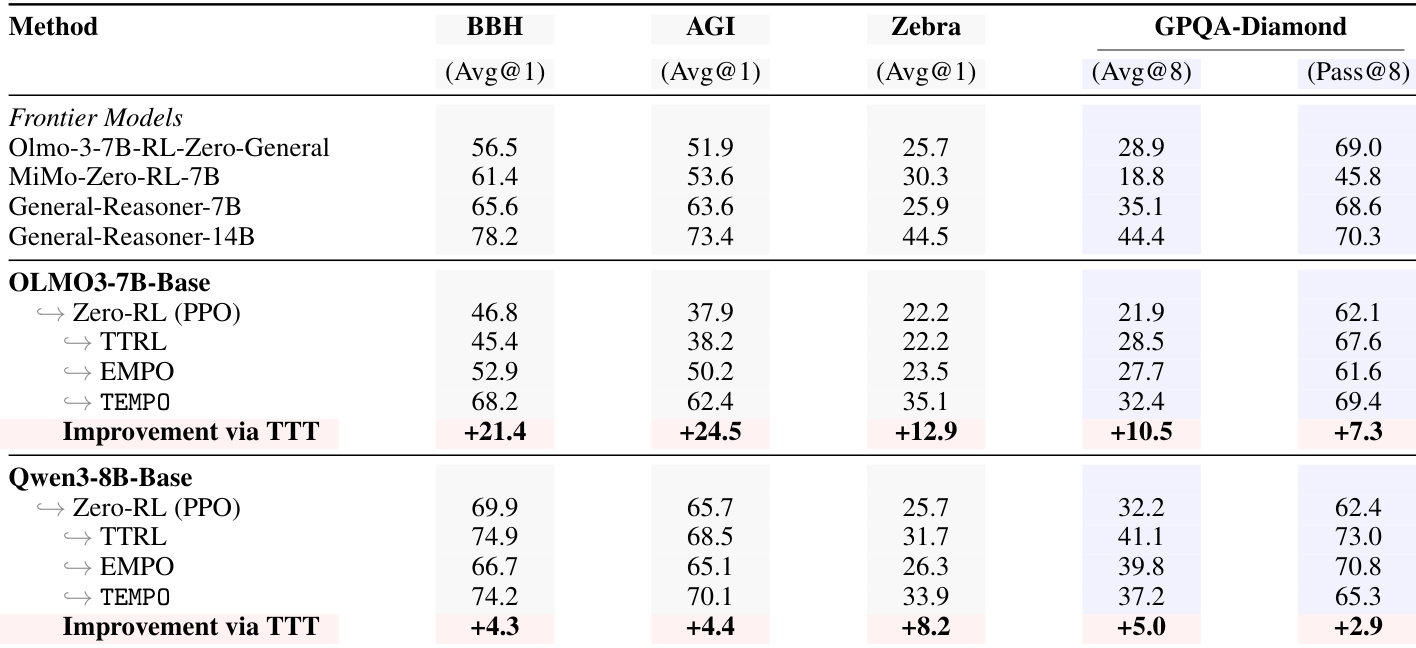
在数学推理之外的通用推理任务上评估 TEMPO,并将其与 PPO、TTRL 和 EMPO 等基准进行比较。结果显示,TEMPO 在多个基准和模型上均取得了显著改进,特别是在 GPQA-Diamond 等复杂领域,同时保持了极高的输出多样性。即使从已收敛的模型开始,该方法仍表现出强劲的性能提升,表明其在利用测试时数据进行持续能力提升方面非常有效。TEMPO 在包括 BigBenchHard、AGI Eval、ZebraLogic 和 GPQA-Diamond 在内的多种推理任务中取得了实质性改进,优于 TTRL 和 EMPO 等基准。该方法保持了高输出多样性,避免了其他自训练方法中出现的崩溃,从而带来了 pass@k 指标的持续增长。TEMPO 在收敛点之后仍能持续改进,证明了在新型数据上进行测试时训练能够实现超越标准 RLVR 限制的性能增长。
在各种模型规模和推理基准(包括数学和通用推理任务)上对 TEMPO 进行评估,以将其性能与标准强化学习和测试时训练基准进行比较。实验表明,TEMPO 一致地提高了推理能力并保持了高输出多样性,而不会出现其他方法中观察到的性能崩溃或停滞。这些结果表明,交替训练设计有效地防止了奖励信号漂移,并通过测试时训练实现了持续的自我改进。