Command Palette
Search for a command to run...
MultiWorld:可扩展的多 agent 多视角视频世界模型
MultiWorld:可扩展的多 agent 多视角视频世界模型
Haoyu Wu Jiwen Yu Yingtian Zou Xihui Liu
摘要
视频世界模型(Video world models)在模拟响应用户或 agents 动作的环境动力学方面已取得了显著成功。这些模型通常被建模为动作条件视频生成模型,通过将历史帧和当前动作作为输入,来预测未来的帧。然而,大多数现有方法仅局限于单 agent 场景,无法捕捉现实世界中多 agent 系统所固有的复杂交互。我们提出了 MultiWorld,这是一个用于多 agent、多视角世界建模的统一框架,能够在保持多视角一致性的同时,实现对多个 agents 的精确控制。我们引入了“多 agent 条件模块”(Multi-Agent Condition Module)以实现精准的多 agent 可控性,并引入了“全局状态编码器”(Global State Encoder)以确保不同视角间观测结果的一致性。MultiWorld 支持对 agent 数量和视角数量进行灵活扩展,并能并行合成不同视角,从而实现高效率。在多玩家游戏环境和多机器人操作任务上的实验表明,MultiWorld 在视频保真度、动作跟随能力以及多视角一致性方面均优于基准模型。项目主页:https://multi-world.github.io/
一句话总结
MultiWorld 是一个用于可扩展多 Agent 和多视角视频世界建模的统一框架,利用 Multi-Agent Condition Module 和 Global State Encoder 实现精确的可控性和连贯的观测,在多玩家游戏环境和多机器人操作任务中的视频保真度、动作跟随能力以及多视角一致性方面均优于基准模型。
核心贡献
- 本文引入了 MultiWorld,这是一个用于可扩展多 Agent 和多视角视频世界建模的统一框架,支持可变数量的 Agent 和摄像机视角。
- 该框架包含一个 Multi-Agent Condition Module,通过使用 Agent 身份嵌入(identity embeddings)和自适应动作权重来实现对多个 Agent 的精确控制。
- 该方法利用 Global State Encoder 将跨视角信息压缩为紧凑的潜在表示,从而确保多视角一致性并实现高效的并行合成。
引言
视频世界模型对于模拟响应用户或 Agent 动作的环境动态至关重要,是具身智能(embodied AI)和游戏领域的强大模拟器。然而,现有模型通常假设单 Agent 环境,难以捕捉多 Agent 系统中复杂的相互依赖关系。此外,以往的方法往往无法在多个 Agent 持有的不同视角之间保持几何和视觉一致性,且许多方法受限于固定的 Agent 或摄像机数量。本文利用名为 MultiWorld 的统一框架来实现可扩展的多 Agent 和多视角视频建模。通过引入 Multi-Agent Condition Module (MACM) 以确保对单个 Agent 的精确控制,并引入 Global State Encoder (GSE) 通过将观测结果聚合为具有 3D 感知能力的全局状态来维持多视角一致性。
数据集
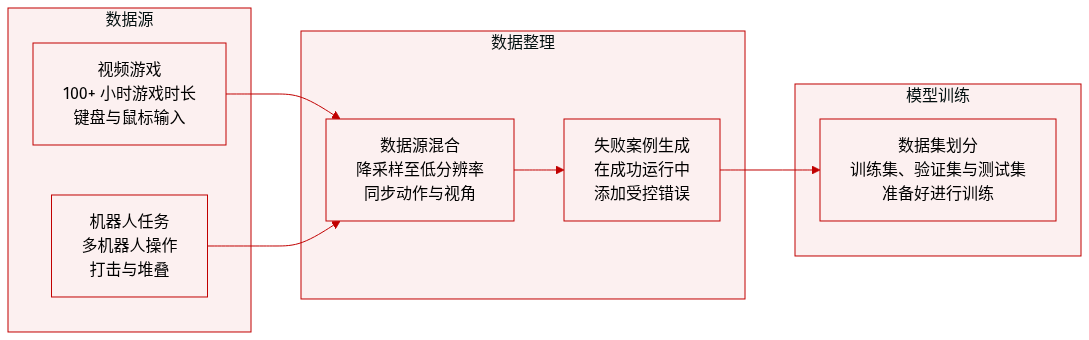
构建了一个包含视频游戏玩法和多机器人操作任务的多样化数据集:
- 视频游戏数据集:该子集包含超过 100 小时以 60 FPS 录制的人类游戏过程。数据包括同步的键盘和鼠标动作。为了训练目的,原始 1440×2560 分辨率被下采样至 320×640。计划发布 "It Takes Two" 多人游戏数据集的一个子集以支持复现。
- 机器人数据集:源自 RoboFactory,该数据集专注于四个多机器人操作任务:击打、两个机器人堆叠、三个机器人堆叠以及四个机器人传递。每个任务包含 1,000 个成功回合和 2,000 个失败回合。数据从多个视角以 256×320 的分辨率进行记录。
- 失败案例构建:为了防止仅针对成功案例的偏差并确保训练的意义,通过向成功轨迹引入受控扰动来生成失败回合。不同于以往阻碍世界模型训练的纯随机动作,该方法在保留基本操作序列的同时增加随机性,以模拟真实的执行错误。
- 数据可用性:由于外部限制,完整的视频游戏数据集受到限制,但将向公众发布特定章节的游戏数据和完整的多机器人协作数据集。
方法
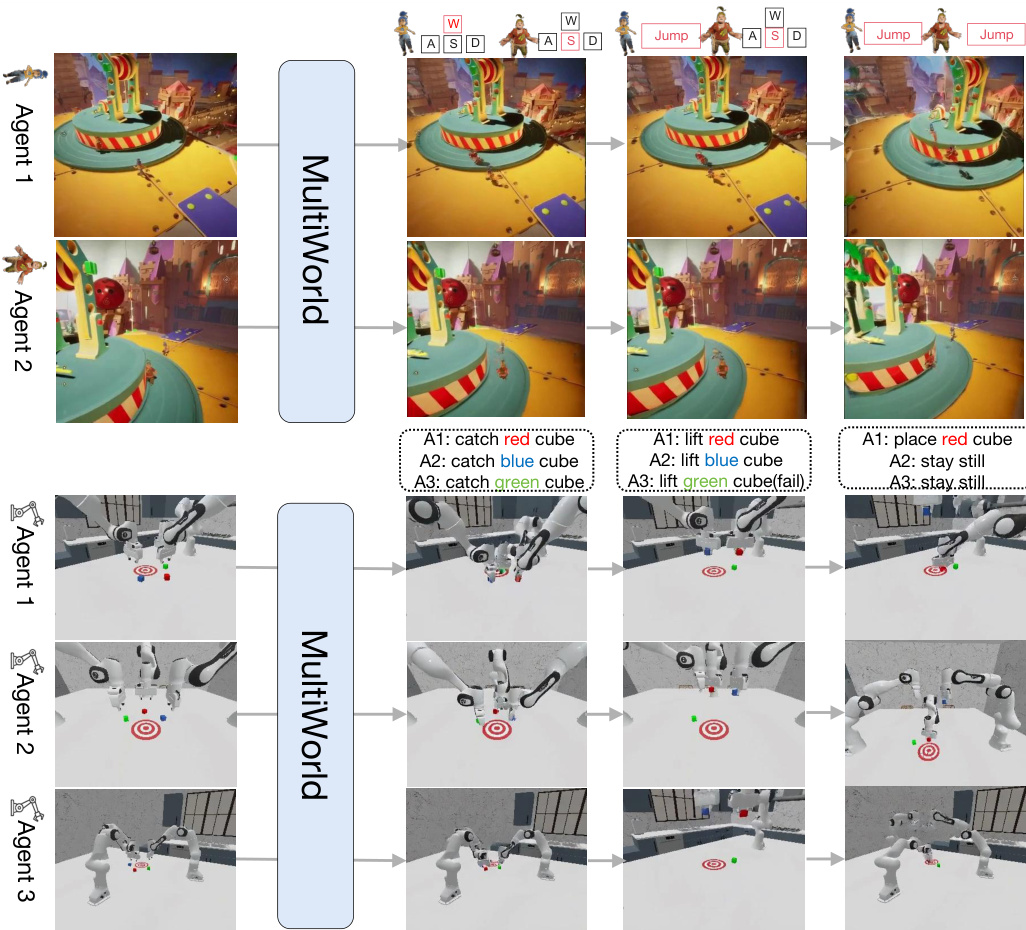
MultiWorld 框架旨在生成以多 Agent 动作为条件的、具有多视角一致性的视频,利用模块化架构确保 Agent 和视角之间的可扩展性与一致性。其核心模型采用基于 Flow Matching (FM) 的扩散主干网络,并结合 Transformer 主干,能够根据噪声观测、时间步、动作和环境上下文进行视频帧的条件生成。对于每个摄像机视角 c,模型以联合动作序列 a 和初始观测 oc 为条件,通过参数化的速度网络 vθ(xct,t,a,o) 预测目标速度 u。为了在自回归生成过程中维持时间因果性,在动作交叉注意力机制中应用了逐帧因果掩码,确保第 i 帧的预测仅依赖于来自帧 {0,…,i} 的动作。
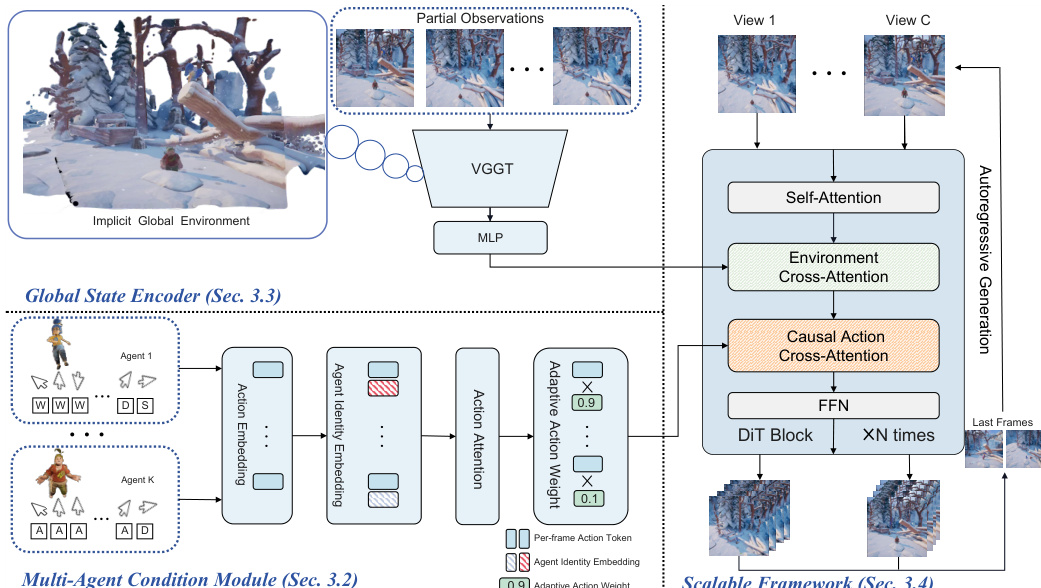
如下图所示,该架构集成了两个关键模块来应对多 Agent 和多视角挑战:Multi-Agent Condition Module (MACM) 和 Global State Encoder (GSE)。MACM 处理来自 K 个 Agent 的动作,解决身份歧义和动作强度变化的问题。为了解决身份歧义,模型使用旋转位置嵌入 (RoPE) 应用 Agent Identity Embedding (AIE),根据 Agent 索引旋转动作嵌入,以打破动作空间中的对称性。这使得模型即使在 Agent 动作镜像或相似时也能进行区分。在 AIE 之后,自注意力机制通过计算 Agent m 和 n 之间的注意力 am⊤Rn−man 来建模 Agent 间的交互,使模型能够捕捉关系动态。为了处理变化的动作强度,Adaptive Action Weighting (AAW) 使用多层感知器为每个 Agent 的动作 token 分配动态权重,优先考虑活跃的 Agent 并抑制静态的 Agent。这些加权后的动作 token 被聚合成统一的动作表示,并通过因果交叉注意力注入 DiT 主干网络。
Global State Encoder (GSE) 通过维持环境的共享 3D 感知表示来确保多视角一致性。它使用预训练的 VGTT 模型处理来自多个摄像机视角的局部观测,提取潜在特征 Hvggt∈RC×n×d,其中 C 是视角数量,n 是每张图像的 token 数量,d 是潜在维度。随后,这些特征通过 MLP 压缩为紧凑的全局表示 H,并通过交叉注意力注入 DiT 主干网络。这种共享的全局状态使模型能够在无需显式 3D 重建的情况下,生成跨视角的连贯局部观测。该框架通过将多视角模拟分解为以全局环境状态为条件的独立单视角生成任务,进一步支持了可扩展性,使得随着视角数量增加,可以在视角间进行并行生成,且推理延迟接近常数。
整个框架通过迭代生成视频块并使用最新的帧更新全局环境状态,支持长程自回归模拟。这使得在超过训练上下文长度两倍的时间跨度内实现稳定生成成为可能。模块化设计确保了模型可以扩展到任意数量的 Agent 和视角,其中 Agent 的可扩展性通过相对身份嵌入实现,视角的扩展性通过将多视角观测压缩为统一的 3D 感知状态实现。扩散主干网络的训练目标是最小化 Flow Matching 损失 LFM=Et,ϵ[∥vθ(xt,t,a)−u∥22],推理通过使用 Euler 解算器采样的概率流 ODE 完成。
实验
MultiWorld 在多玩家视频游戏和多机器人操作任务中进行了评估,以验证其可扩展性、动作跟随准确性和多视角一致性。对比实验表明,该框架通过有效地建模 Agent 间的交互并在同步视角间保持结构完整性,表现优于现有基准模型。消融研究进一步证实,所提出的架构模块对于增强运动保真度、防止 Agent 消失以及实现真实的长期模拟至关重要。
进行了消融研究以评估 MultiWorld 框架中关键组件的贡献,重点关注视觉质量和动作跟随性能。结果显示,添加 Multi-Agent Condition Module 可提高动作跟随能力,而引入 Global State Encoder 可增强多视角一致性,两个组件结合使用可带来卓越的整体性能。添加 Multi-Agent Condition Module 提升了动作跟随能力。引入 Global State Encoder 增强了多视角一致性。结合两个模块在视觉质量和动作跟随方面达到了最佳整体性能。

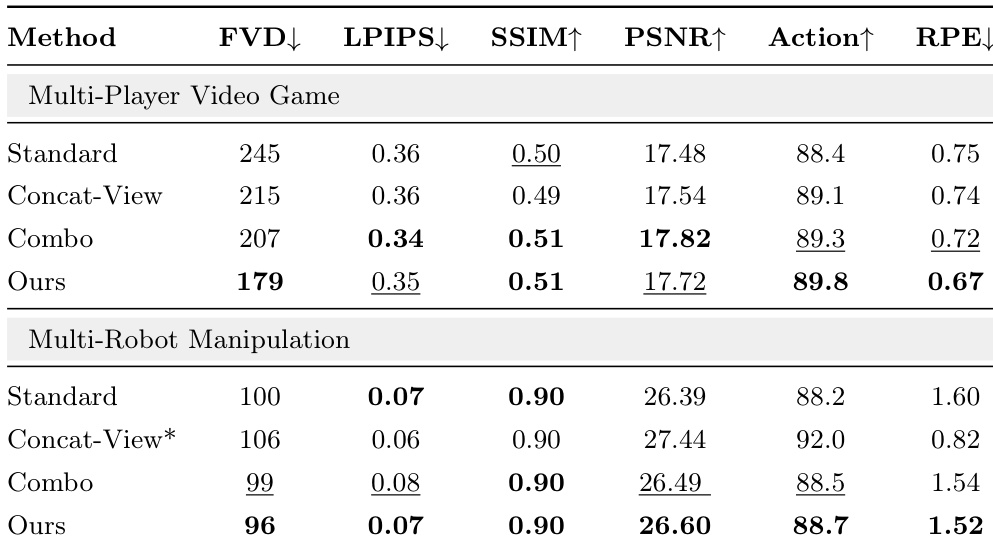
在多玩家视频游戏和多机器人操作场景中将 MultiWorld 与基准方法进行了对比评估,结果表明该方法在视觉质量、动作跟随和多视角一致性等指标上始终优于所有基准模型。结果突显了该框架组件在提高多 Agent、多视角设置下的感知保真度和几何相干性方面的有效性。MultiWorld 在视频游戏和机器人操作场景的多个评估指标上均始终优于所有基准模型。该框架实现了卓越的视觉质量和动作跟随能力,在 FVD、PSNR 和 SSIM 等指标上表现最佳。MultiWorld 展示了改进的多视角一致性,表现为与基准模型相比具有更低的重投影误差。
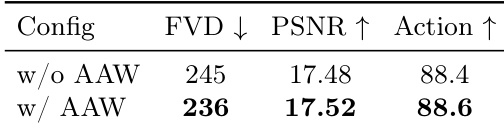
进行了消融研究以评估 Adaptive Action Weighting 对视觉质量和动作跟随能力的影响。结果显示,引入该机制可使两项指标均得到提升,与不含该机制的基准相比,该方法在视觉质量和动作跟随方面实现了更高的性能。Adaptive Action Weighting 提升了视觉质量和动作跟随能力。使用 Adaptive Action Weighting 的方法在视觉质量和动作跟随方面比不含该机制的基准表现更高。引入 Adaptive Action Weighting 会带来视觉质量和动作跟随指标的提升。
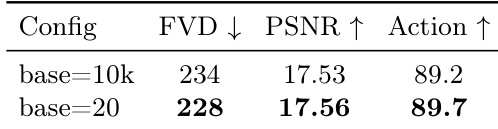
消融研究检查了 Agent Identity Embedding 中不同基频(base frequencies)对视觉质量和动作跟随性能的影响。结果显示,较低的基频会导致所有评估指标的提升,表明与 Agent 数量有更好的对齐,并增强了对多 Agent 动作的控制。Agent Identity Embedding 中较低的基频提升了动作跟随能力和视觉质量。与 base=10k 相比,base=20 的配置在所有指标上均取得了更好的性能。降低基频增强了模型区分 Agent 以及准确跟随动作的能力。
进行了消融研究以评估 MultiWorld 框架中 Global State Encoder 不同主干选择的影响。结果显示,VGGT 主干在多个指标上均达到了最佳性能,优于其他主干以及没有全局状态编码器的基准。与替代方案相比,基于 VGGT 的编码器同时提升了视觉质量和多视角一致性。VGGT 主干在视觉质量和多视角一致性方面优于其他主干。基于 VGGT 的 Global State Encoder 在所有评估指标上均取得了最佳结果。缺少全局状态编码器会导致所有指标表现最差。

通过在多玩家视频游戏和机器人操作中的消融研究和对比评估,验证了 MultiWorld 框架及其单个组件的有效性。结果表明,Multi-Agent Condition Module、采用 VGGT 主干的 Global State Encoder 以及 Adaptive Action Weighting 共同增强了动作跟随、视觉质量和多视角一致性。此外,通过较低基频优化 Agent Identity Embedding 提升了模型区分 Agent 并准确跟随多 Agent 动作的能力。