Command Palette
Search for a command to run...
从内部视角审视 LLM 安全性:利用内部表示检测有害内容
从内部视角审视 LLM 安全性:利用内部表示检测有害内容
Difan Jiao Yilun Liu Ye Yuan Zhenwei Tang Linfeng Du Haolun Wu Ashton Anderson
摘要
防护模型(Guard models)被广泛用于检测用户提示词(prompts)及 LLM 响应中的有害内容。然而,目前最先进的防护模型仅依赖于最后一层的表示(representations),而忽略了分布在内部各层中丰富的安全性相关特征。我们提出了 SIREN,这是一种利用这些内部特征的轻量级防护模型。通过线性探测(linear probing)识别安全性神经元,并结合一种自适应层加权策略,SIREN 能够在不修改底层模型的情况下,从 LLM 内部构建出有害性检测器。我们的全面评估表明,SIREN 在多个基准测试中的表现显著优于目前最先进的开源防护模型,而其可训练参数量仅为后者的 1/250。此外,SIREN 对未知基准测试表现出卓越的泛化能力,能够自然地实现实时流式检测,且与生成式防护模型相比,显著提升了推理效率。总而言之,我们的研究结果强调了 LLM 内部状态是实现实用、高性能有害性检测的一个极具前景的基础。
一句话总结
通过线性探测(linear probing)识别安全神经元,并利用自适应层加权策略进行组合,轻量级防护模型 SIREN 利用 LLM 内部表示,在多个基准测试中超越了最先进的开源模型,同时使用的可训练参数减少了 250 倍,并实现了卓越的泛化能力和实时流式检测。
核心贡献
- 本文介绍了 SIREN,这是一种轻量级且即插即用的防护模型,通过利用 LLM 的内部神经元表示而非仅仅依赖终端层输出,来检测有害性。
- 该方法通过 L1 正则化线性探测识别与安全相关的神经元,并使用自适应的性能加权组合策略跨多个层聚合这些特征。
- 实验结果表明,SIREN 在多个基准测试中优于最先进的开源防护模型,同时使用的可训练参数减少了 250 倍,并对未见数据集和实时流式检测提供了卓越的泛化能力。
引言
随着大语言模型(LLMs)规模的扩大,实施强大的防护栏以检测有害的用户提示词和模型响应,已成为安全部署的关键。目前最先进的防护模型通常仅依赖终端层表示,将安全检测视为一种生成式任务。这种方法忽略了分布在模型内部各层中丰富的、与安全相关的特征,并且由于自回归 token 生成而导致高昂的计算成本。本文利用这些内部表示引入了 SIREN,这是一个轻量级、即插即用的框架,通过线性探测识别安全神经元,并使用自适应层加权策略对其进行聚合。SIREN 在多个基准测试中优于现有的生成式防护模型,同时使用的可训练参数减少了 250 倍,并提供了卓越的推理效率。
方法
本文采用了一种用于内容安全分类的两阶段框架,该框架完全在基于 transformer 的语言模型(LLM)的内部表示上运行,无需修改其权重。这种被称为 SIREN 的方法旨在识别并聚合跨层的安全相关神经元,从而构建用于有害性检测的鲁棒特征表示。整体架构包含两个主要阶段:安全神经元识别和自适应神经元聚合。
参考框架图  。在第一阶段,对于长度为 T 的给定输入序列 s,从 LLM 中提取每一层的内部表示。这些表示记为第 l 层的 xl=LLMl(s)∈RT×D,它们源自残差流(residual streams)或前馈网络激活。为了捕捉句子的整体语义内容,对 token 级别的表示应用均值池化操作,得到池化表示 xl∗∈RD。随后,在这些池化表示上使用带有地面真值(ground-truth)有害性标签 y 的分类任务进行逐层线性探测训练。目标是最小化带有对探测权重 Wl 进行 L1 正则化的交叉熵损失,这基于线性表示假设,即语义概念通常在 LLMs 中以线性方式编码。第 l 层中每个神经元 j 的训练权重 wl,j 的大小用于确定其与有害性检测的相关性。这些权重经过归一化处理,并将累积归一化大小超过阈值 η 的排名靠前的神经元选为该层的安全神经元,形成集合 Sl。
。在第一阶段,对于长度为 T 的给定输入序列 s,从 LLM 中提取每一层的内部表示。这些表示记为第 l 层的 xl=LLMl(s)∈RT×D,它们源自残差流(residual streams)或前馈网络激活。为了捕捉句子的整体语义内容,对 token 级别的表示应用均值池化操作,得到池化表示 xl∗∈RD。随后,在这些池化表示上使用带有地面真值(ground-truth)有害性标签 y 的分类任务进行逐层线性探测训练。目标是最小化带有对探测权重 Wl 进行 L1 正则化的交叉熵损失,这基于线性表示假设,即语义概念通常在 LLMs 中以线性方式编码。第 l 层中每个神经元 j 的训练权重 wl,j 的大小用于确定其与有害性检测的相关性。这些权重经过归一化处理,并将累积归一化大小超过阈值 η 的排名靠前的神经元选为该层的安全神经元,形成集合 Sl。
在第二阶段,框架聚合所有层中识别出的安全神经元,以形成更全面的特征表示。研究指出,LLMs 表现出层次化学习结构,表示从低级模式演化到高级语义,这促使了从多个层聚合安全相关特征的需求。为了考虑到每一层对任务的不同贡献,引入了一种自适应加权策略。第 l 层的权重 αl 根据线性探测的验证 F1 分数 fl 计算,并在所有层的最大和最小 F1 分数之间进行归一化。这为信息量更大的层分配了更高的权重。提取每一层的安全神经元激活值,根据各自的 αl 进行加权,并进行拼接以形成最终的特征向量 z。随后将该聚合特征 z 输入多层感知器(MLP)分类器进行有害性预测。MLP 学习结合来自跨层特征的互补信号,而 αl 值作为层重要性的先验,而非最终的特征权重。
该框架设计为即插即用,可以在任何基于 transformer 的 LLM 之上运行,无需进行架构更改。它也可以迁移到 token 级别的归因任务。通过移除均值池化操作,相同的安全神经元和分类器可以应用于每个 token 的隐藏表示,直接产生每个 token 的有害性评分。这种能力在 token 级别流式检测结果的可视化中得到了展示  ,其中模型增量地处理序列,为每个前缀提取特征,并应用分类器在每个 token 位置生成连续的有害性评分。这种流式评估是通过在受限前缀的内部状态上重新评估特征提取器来实现的,从而能够零样本(zero-shot)评估安全信息在生成早期阶段是如何体现的。
,其中模型增量地处理序列,为每个前缀提取特征,并应用分类器在每个 token 位置生成连续的有害性评分。这种流式评估是通过在受限前缀的内部状态上重新评估特征提取器来实现的,从而能够零样本(zero-shot)评估安全信息在生成早期阶段是如何体现的。
实验
SIREN 通过在多个安全基准测试中针对通用 LLM 骨干网络的内部表示进行训练,并与最先进的专用防护模型进行对比评估。结果表明,SIREN 实现了卓越的检测性能,保持了更高的策略一致性,并能有效地泛化到未见的推理轨迹和流式检测任务。此外,由于其稀疏的参数使用和消除了自回归生成,该方法在训练和推理效率方面都具有显著优势。
通过在多个基准测试中将 SIREN(一种在通用 LLMs 内部表示上训练的轻量级分类器)与安全专用防护模型进行对比,结果显示,与防护模型相比,SIREN 在不同数据集上实现了更高的平均性能和更一致的检测,同时也展示了对未见基准测试和流式检测的强大泛化能力。由于依赖于对基础模型的单次前向传播,SIREN 在推理期间的计算效率显著更高。SIREN 在所有骨干网络对中均优于防护模型,并在不同的基准测试中保持了一致的精确率-召回率权衡。SIREN 无需额外的训练或架构更改,即可有效地泛化到未见基准测试和流式检测。通过在预计算的内部表示上运行,SIREN 实现了大幅的推理效率提升,所需的计算操作远少于自回归防护模型。
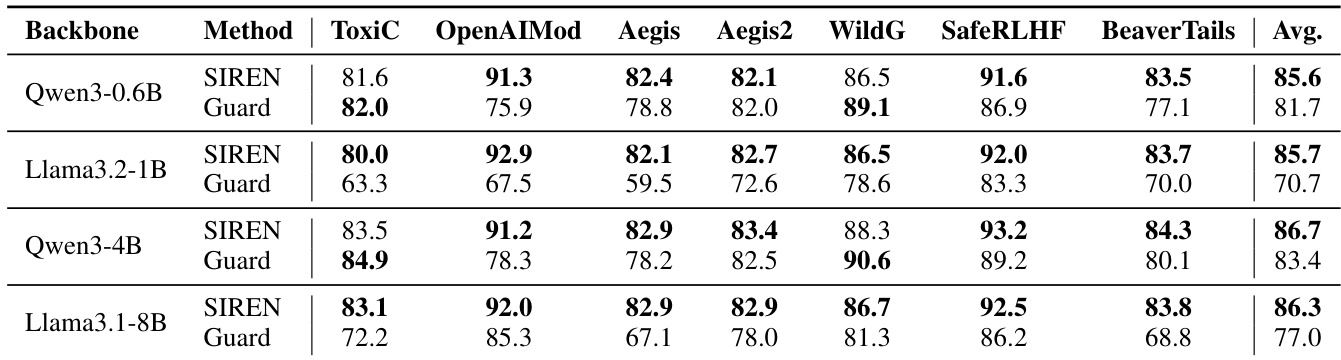
通过在多个基准测试中将利用通用 LLMs 内部表示进行有害性检测的方法 SIREN 与安全专用防护模型进行对比,结果显示,与分类行为表现出显著差异的防护模型相比,SIREN 实现了更高的检测性能,并在不同数据集间保持了更一致的精确率-召回率权衡。SIREN 还展示了对未见基准测试和流式检测任务的鲁棒泛化能力,且无需额外训练,同时在推理过程中所需的参数和计算资源大幅减少。与精确率和召回率表现出较大波动的防护模型相比,SIREN 在各个基准测试中实现了更高且更一致的检测性能。SIREN 无需额外的训练或架构修改,即可有效地泛化到未见基准测试和流式检测任务。在推理过程中,SIREN 所需的参数和计算资源显著少于依赖自回归生成的防护模型。
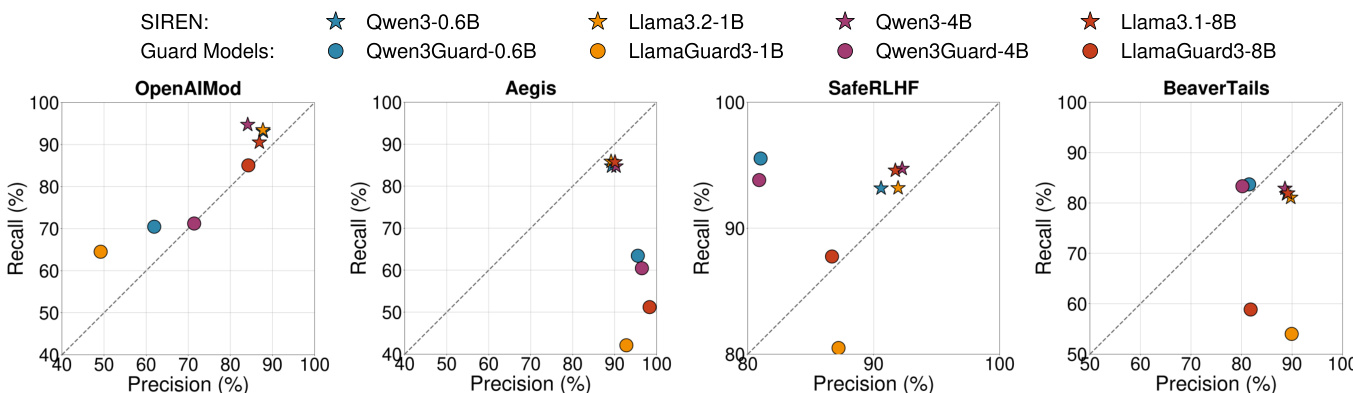
通过在不同的检测延迟位置将 SIREN 与安全专用防护模型进行对比,结果表明 SIREN 一致地实现了比防护模型更高的检测率。SIREN 在所有延迟阶段都保持了强大的性能,而防护模型表现出较低的检测率,特别是在早期阶段。结果表明,SIREN 的有害性检测方法在不同的检测延迟下更加有效且稳定。在所有检测延迟位置,SIREN 的检测率均高于防护模型。SIREN 在不同的延迟阶段保持了性能的一致性,而防护模型显示出较低的检测率,尤其是在早期阶段。SIREN 在及时检测方面优于防护模型,表明其具有更好的实时有害内容识别能力。
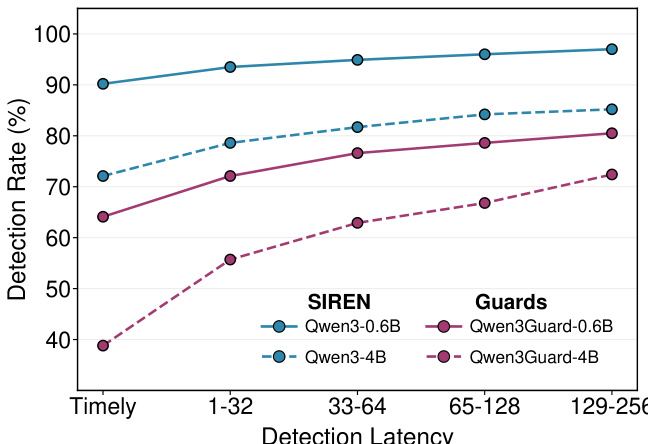
通过消融实验分析了 SIREN 的关键设计选择,重点关注超参数敏感性和内部安全编码。结果显示,SIREN 的性能在一定范围的正则化强度和神经元选择阈值下保持稳定,并通过网格搜索找到了最优设置。该模型利用了来自多个层的内部表示,其中中间层对安全检测的贡献最大,且跨层聚合相比单层探测提升了性能。训练过程在提取的神经元上使用轻量级 MLP 分类器,超参数的选择旨在平衡性能与效率。SIREN 的性能在一定范围的正则化强度和神经元选择阈值下保持稳定,并通过网格搜索找到了最优设置。LLM 的中间层对安全检测的贡献最大,且跨层聚合相比单层探测提升了性能。训练过程在提取的神经元上使用轻量级 MLP 分类器,超参数的选择旨在平衡性能与效率。
通过在多个基准测试中将基于语言模型内部表示运行的轻量级分类器 SIREN 与安全专用防护模型进行对比,结果显示,SIREN 实现了比防护模型更高的检测性能,在不同数据集间保持了一致的策略行为,并能有效地泛化到未见和流式检测任务。由于依赖于稀疏神经元选择和极少的参数更新,SIREN 还展示了显著的训练和推理效率。SIREN 在所有评估的基准测试和模型规模上均优于安全专用防护模型。SIREN 在不同数据集间保持了一致的精确率和召回率,表明其具有稳定的安全策略学习能力。SIREN 无需额外训练即可很好地泛化到未见基准测试和流式检测,同时所需的参数和计算资源显著少于防护模型。
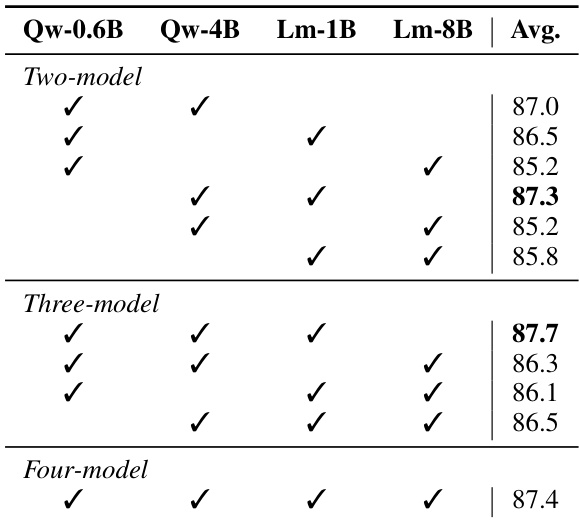
通过在各种基准测试、延迟阶段和消融配置中将利用通用 LLMs 内部表示的轻量级分类器 SIREN 与专用防护模型进行对比,评估了 SIREN 的表现。SIREN 展示了比防护模型更优越的检测性能和更稳定的精确率-召回率权衡,同时也表现出对未见基准测试和流式任务的鲁棒泛化能力。此外,该方法实现了显著的计算效率,并受益于跨层聚合,特别是通过利用编码在骨干模型中间层的安全信息。