Command Palette
Search for a command to run...
OneVL:结合视觉-语言解释的一步式潜在推理与规划
OneVL:结合视觉-语言解释的一步式潜在推理与规划
摘要
思维链(Chain-of-Thought, CoT)推理已成为基于视觉-语言-动作(VLA)模型的自动驾驶轨迹预测的强大驱动力,然而其自回归(autoregressive)特性所带来的延迟成本,使得实时部署变得极其困难。潜性 CoT(Latent CoT)方法试图通过将推理压缩进连续的隐藏状态来弥补这一差距,但在性能上始终无法达到显式 CoT 方法的水平。我们认为,这是由于纯语言型的潜性表示仅压缩了世界的符号化抽象,而非真正主导驾驶行为的因果动力学(causal dynamics)。为此,我们提出了 OneVL(One-step latent reasoning and planning with Vision-Language explanations),这是一个统一的 VLA 与世界模型(World Model)框架。该框架通过受双辅助解码器监督的紧凑潜性 tokens 来引导推理过程。除了能够重构文本 CoT 的语言解码器外,我们还引入了一个视觉世界模型解码器,用于预测未来帧的 tokens,从而迫使潜性空间内化道路几何结构、agent 运动以及环境变化的因果动力学。我们采用三阶段训练流水线,逐步将这些潜性表示与轨迹、语言及视觉目标进行对齐,从而确保稳定的联合优化。在推理阶段,辅助解码器会被舍弃,所有的 latent tokens 将在单次并行处理中完成预填充(prefilled),其速度与仅输出答案(answer-only)的预测模式一致。在四个基准测试中,OneVL 成为首个超越显式 CoT 的潜性 CoT 方法,在仅输出答案的延迟水平下实现了最先进的(SOTA)准确率。这提供了直接证据,证明在语言与世界模型双重监督的指导下,更紧凑的压缩比冗长的 token-by-token 推理能够产生更具泛化性的表示。项目主页:https://xiaomi-embodied-intelligence.github.io/OneVL
一句话总结
小米具身智能团队提出了 OneVL,这是一个统一的 VLA 和世界模型框架。该框架采用双辅助解码器,通过语言重建和未来帧预测来监督紧凑的 latent tokens,从而实现一步式 latent 推理与规划。在四个基准测试中,其性能在仅回答(answer-only)的延迟水平下超越了显式思维链(chain-of-thought)的表现。
核心贡献
- 本文引入了 OneVL,这是一个统一的视觉-语言-动作(VLA)与世界模型框架,利用紧凑的 latent tokens 进行推理和规划。该方法通过由双辅助解码器监督的压缩 latent 空间进行推理,从而同时捕捉语言推理和因果环境动态。
- 提出了一种三阶段训练流水线,旨在逐步将 latent 表示与轨迹、语言和视觉目标对齐。通过使用语言解码器重建基于文本的 Chain-of-Thought,以及使用视觉世界模型解码器预测未来帧 tokens,该方法确保了稳定的联合优化。
- 该框架通过在推理时采用单次并行传递(此时会丢弃辅助解码器),在四个基准测试中实现了最先进的准确度。这种设计使模型能够匹配仅回答预测的速度,同时超越显式 Chain-of-Thought 方法的性能。
引言
视觉-语言-动作(VLA)模型正越来越多地应用于自动驾驶领域,以统一场景理解、推理和轨迹规划。虽然 Chain-of-Thought (CoT) 推理通过呈现中间驾驶意图提高了预测准确性,但其自回归特性带来了高推理延迟,不适用于实时、安全至上的部署场景。现有的 latent CoT 方法试图将推理压缩到连续的隐藏状态中以节省时间,但由于它们依赖于仅捕捉符号抽象而非驾驶环境实际因果动态的纯语言表示,因此表现往往不如显式 CoT。
作者利用名为 OneVL 的统一 VLA 与世界模型框架来弥补这一差距。引入了双辅助解码器来监督紧凑的 latent tokens:一个语言解码器用于重建基于文本的推理,一个视觉世界模型解码器用于预测未来帧 tokens。这种双重监督迫使 latent 空间将语义意图以及道路几何与 agent 运动的时空因果动态进行内化。通过使用三阶段训练流水线和单次预填充(single-pass prefill)推理方法,OneVL 在仅回答预测的速度下实现了最先进的准确度。
数据集

作者使用四个互补的数据集来评估 OneVL,这些数据集旨在支持 Chain-of-Thought (CoT) 推理和复杂的驾驶场景:
-
数据集组成与来源
- NAVSIM: 一个大规模自动驾驶基准测试,源自 nuPlan 驾驶日志,用于非反应式基于模拟的规划。
- ROADWork: 一个专门针对道路施工区域自动导航的数据集,具有临时标志、障碍物和非标准车道配置等危险因素。
- Impromptu: 一个大规模视觉-语言-动作基准测试,从八个开放驾驶数据集中蒸馏而成,针对非结构化的极端情况(corner-case)场景。
- APR1: 一个具有因果链 (CoC) 标注的数据集,为复杂的驾驶行为提供基于决策的推理轨迹。
-
标注与处理细节
- CoT 构建: 使用多种流水线生成用于监督的推理轨迹。对于 NAVSIM,利用了来自 AdaThinkDrive 的现有标注。对于 ROADWork,使用内部流水线对施工区危险和车道解释进行标注。对于 Impromptu,采用以 VLM 为中心的流水线对非结构化场景进行分类,并生成面向规划的原理。对于 APR1,使用已发布的模型检查点来复制 CoC 标签。
- 轨迹子采样: 为了使路径点预测适用于自回归建模,对 APR1 的路径点应用了启发式子采样策略,将序列从 64 个点减少到 8 个点,同时确保保留了最终的点。
- 测试集构建: 由于 APR1 缺乏官方测试集,从现有视频剪辑中子采样了 700 个样本以创建自定义评估集。
- 数据格式: 训练样本结构包括视觉 latent tokens、语言 latent tokens、轨迹答案、CoT 推理步骤和未来图像 tokens。
方法
作者利用基于 Qwen3-VL-4B-Instruct 构建的统一视觉语言模型架构,实现了自动驾驶中的一步式 latent 推理、规划和可解释性。核心框架集成了视觉编码器 (ViT)、视觉投影器 (MLP Aligner) 和大语言模型 (LLM),形成了一个处理交错图像和文本输入的骨干网络。为了实现紧凑且可解释的推理,模型引入了两种专门的 latent token 类型:视觉 latent tokens (Zv) 和语言 latent tokens (Zl)。这些 tokens 被插入到模型的输出序列中,其中视觉 latents 位于语言 latents 之前,作为推理的压缩载体。在训练期间,这些 latent token 位置对应的隐藏状态被提取并输入到两个辅助解码器中。视觉辅助解码器预测未来帧的视觉 tokens,充当验证场景动态因果结构的世界模型;而语言辅助解码器则重建人类可读的 Chain-of-Thought (CoT) 推理。这种双重监督机制确保了 latent 表示编码了真正具有泛化能力和因果性的信息,从而将语义意图与物理动态相结合。架构的视觉概览请参考框架图 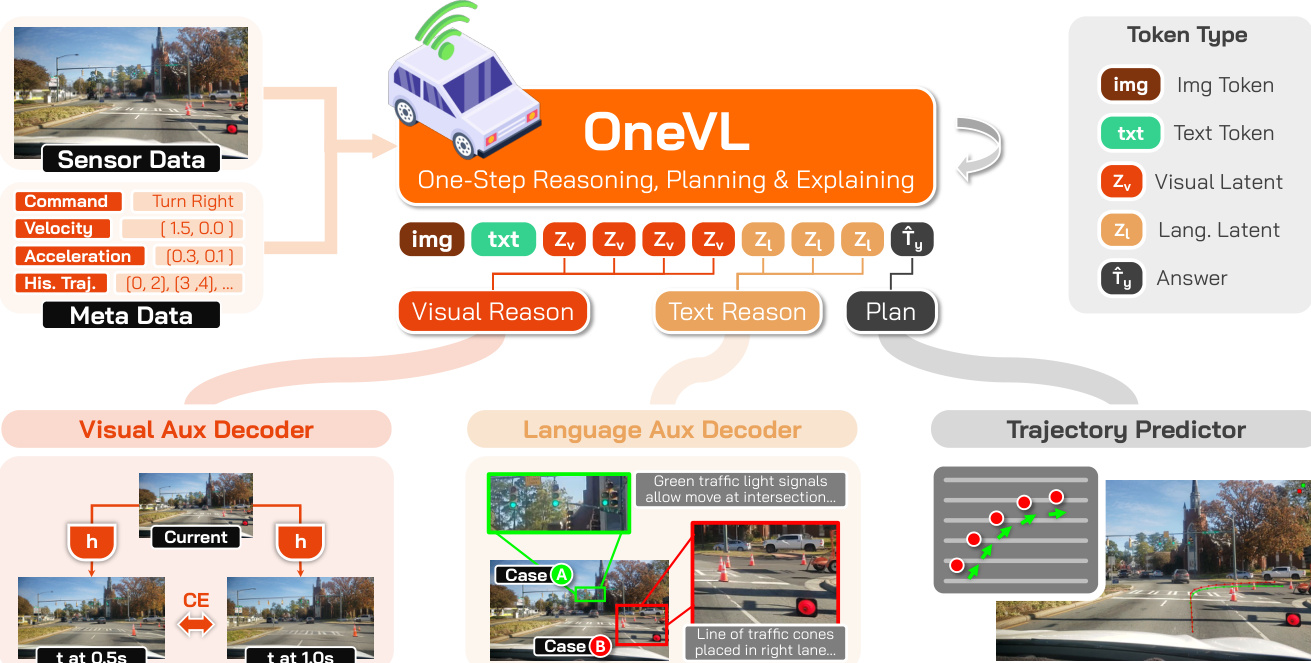 。
。
语言辅助解码器旨在从语言 latent 隐藏状态中恢复显式的推理文本。它将来自语言 latent tokens 的隐藏状态 (Hl) 和当前帧的 ViT patch 嵌入 (V) 作为输入,在将两者投影到解码器的嵌入空间后进行拼接,然后预测真实的 CoT 文本。与此同时,视觉辅助解码器根据当前视觉上下文和视觉 latent 隐藏状态 (Hv) 执行未来帧预测。为了将图像表示为离散序列,模型采用了 IBQ 视觉 tokenizer,它使用包含 131,072 个离散视觉代码的大型码本,扩展了基础模型的词表。视觉解码器经过训练,用于预测 0.5s 和 1.0s 时刻未来帧的拼接离散视觉 token 序列。总训练目标是主模型在轨迹和 latent token 预测上的交叉熵损失 (Lc)、语言解释损失 (Ll) 以及视觉解释损失 (Lv) 的加权和,其中视觉任务的权重较低,以防止其主导训练信号。
为了确保这一复杂架构的有效训练,作者采用了三阶段流水线。过程始于视觉辅助解码器的初步自监督预训练,以便仅从当前帧学习未来帧预测的强无条件先验。随后是阶段 0,即主模型预热,在嵌入了 latent tokens 的情况下对骨干网络进行轨迹预测训练,使模型学会生成有意义的 latent 表示。阶段 1 侧重于在保持主模型冻结的情况下训练辅助解码器,确保它们与稳定的 latent 特征对齐。最后,阶段 2 对所有组件进行端到端的联合微调,形成一个良性循环:辅助解码器的监督信号优化 latent 表示,进而提升模型的整体性能。在推理时,辅助解码器被丢弃,latent tokens 被预填充到提示上下文(prompt context)中,从而实现单次传递生成轨迹答案,其推理速度与仅回答预测相当,同时保留了推理过程的可解释性。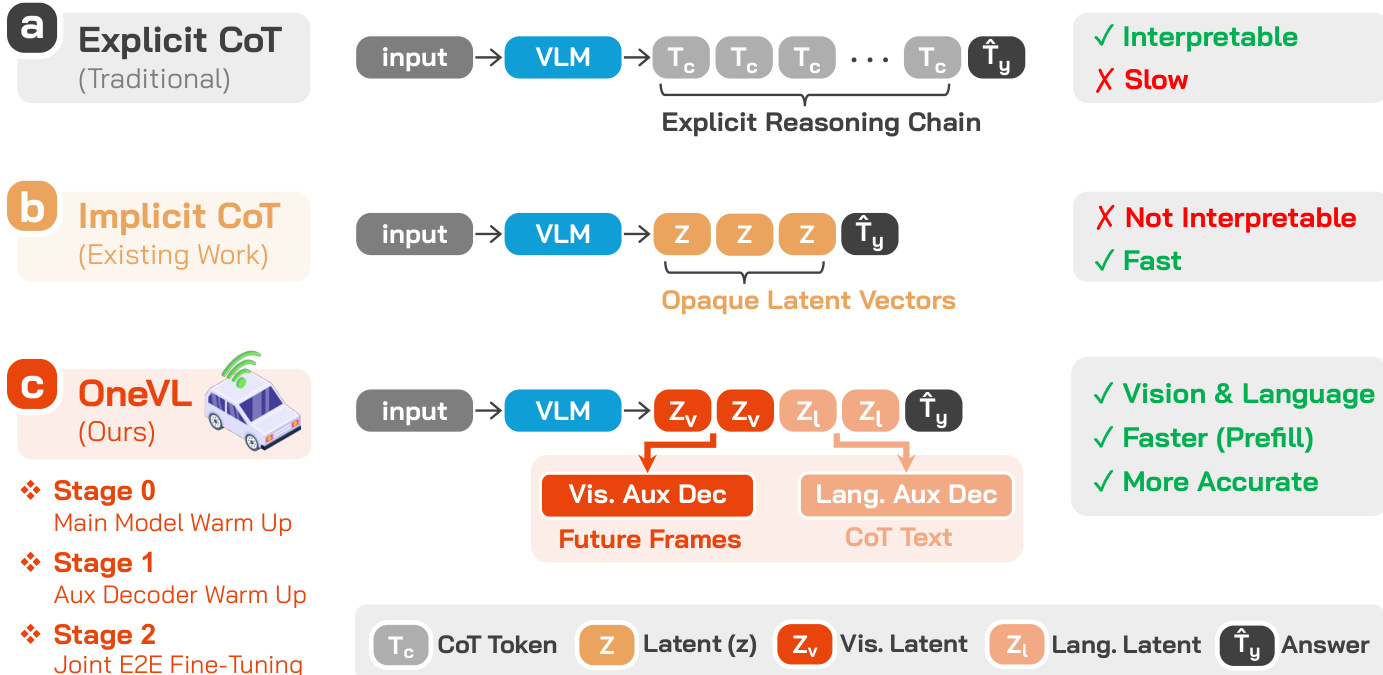
实验
评估通过四个基准测试(包括 NAVSIM、ROADWork、Impromptu 和 APR1)对 OneVL 框架进行验证,以评估其轨迹预测准确性、解释质量和推理效率。通过将 OneVL 与自回归和 latent chain-of-thought 基准进行比较,实验表明,将语言推理与视觉世界模型监督相结合可以显著提高规划性能。结果表明,OneVL 在实现最先进准确度的同时,提供了人类可解释的解释,并保持了实际自动驾驶部署所需的低延迟。
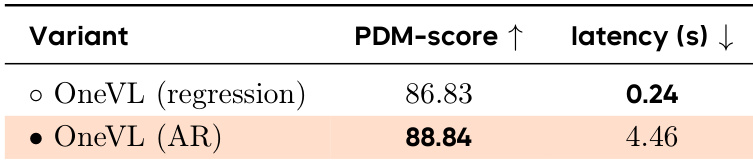
作者将 OneVL 的回归变体与其自回归对应版本进行了比较,结果显示回归版本虽然 PDM 分数略低,但显著降低了推理延迟。结果表明,回归方法在实现更快推理的同时保持了具有竞争力的性能,支持实时部署。OneVL 回归在保持竞争力的性能时实现了比 OneVL AR 更低的延迟。与自回归版本相比,OneVL 的回归变体在 PDM 分数上略有下降。回归方法实现了显著更快的推理,使其适用于实时部署。
作者在 NAVSIM 基准测试上评估了不同方法生成的文本解释质量,重点关注预测的推理与真实标注的对齐程度。带有语言辅助解码器的 OneVL 在解释质量方面取得了具有竞争力的结果,在多个指标上表现强劲,同时保持了效率。对比表明,显式推理方法在解释质量上优于 latent CoT 方法,但 OneVL 的 latent 框架在可解释性与性能之间仍提供了良好的平衡。在 NAVSIM 上,带有语言辅助解码器的 OneVL 与显式推理方法相比,实现了具有竞争力的解释质量。在文本解释质量的所有评估指标中,显式推理方法均优于 latent CoT 方法。OneVL 的 latent 框架在解释质量与推理效率之间取得了平衡。

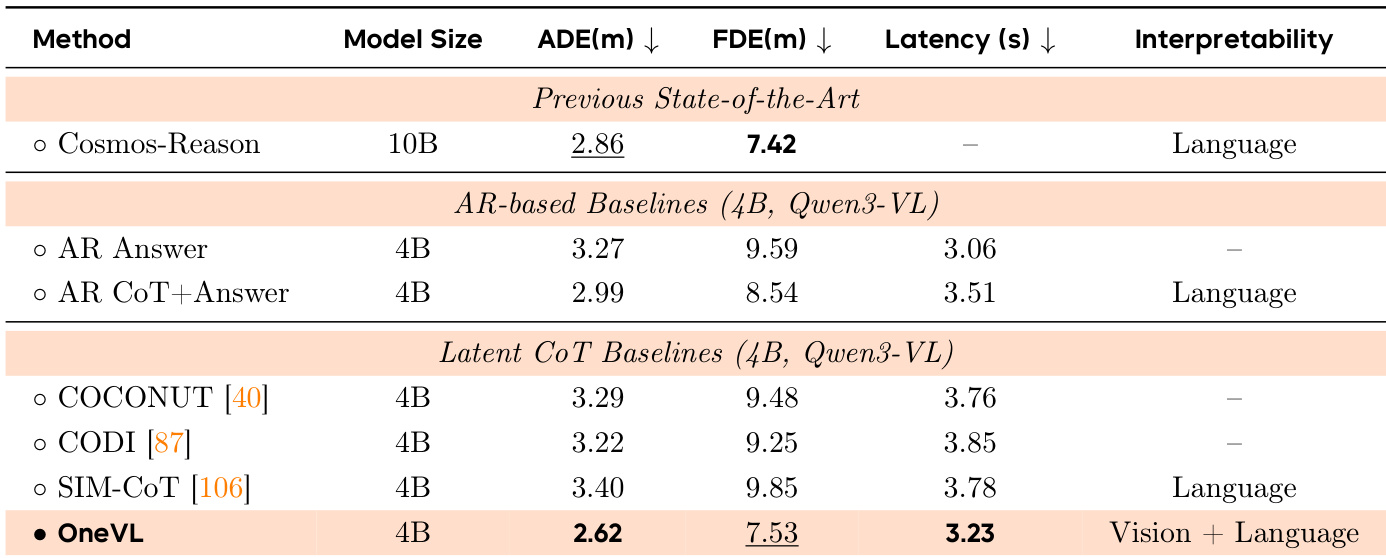
作者比较了多种自动驾驶轨迹预测方法,重点关注性能、延迟和可解释性。结果显示,与之前的最先进方法相比,OneVL 以更低的延迟实现了具有竞争力的准确度,并且优于其他 latent CoT 方法,特别是在轨迹预测指标方面。OneVL 还通过视觉和基于语言的推理提供可解释的输出。OneVL 以比以往最先进方法更低的延迟实现了具有竞争力的轨迹预测准确度。OneVL 优于其他 latent CoT 方法,尤其是在轨迹预测指标方面,同时提供了可解释的输出。视觉辅助解码器对性能的贡献大于语言解码器,这表明空间-时间对齐在推理中的重要性。
作者在轨迹预测任务上将 OneVL 的性能与 Impromptu VLA 进行了比较,重点关注随时间变化的预测准确度。结果显示,OneVL 在所有时间步上的轨迹预测误差显著降低,表明与基准相比,在预测未来车辆路径方面的准确度有所提高。性能差距随时间扩大,表明随着预测时界的延长,OneVL 的预测保持了更高的一致性和准确性。与 Impromptu VLA 相比,OneVL 在所有时间步上实现了大幅降低的轨迹预测误差。OneVL 与基准之间的性能差距随着预测时界的延长而增加。OneVL 在预测未来车辆轨迹方面表现出卓越的准确性,尤其是在较晚的时间点。

作者在多个自动驾驶基准测试上评估了 OneVL,证明其性能优于自回归和 latent chain-of-thought 基准。该模型在实现与仅回答预测相当的推理速度的同时,达到了最先进的结果,突显了其多模态辅助监督和分阶段训练方法的有效性。关键发现表明,视觉世界模型监督和三阶段训练流水线对于在轨迹预测中实现有效的 latent 推理至关重要。OneVL 在 NAVSIM、ROADWork、Impromptu 和 APR1 上均优于所有基准,在多个指标上实现了最先进的结果。该模型的推理速度与仅回答预测相匹配,证明了预填充 latent tokens 产生的延迟开销微乎其微。视觉辅助监督和三阶段训练流水线至关重要,因为缺失这些环节会导致性能显著下降,并无法学习因果场景动态。
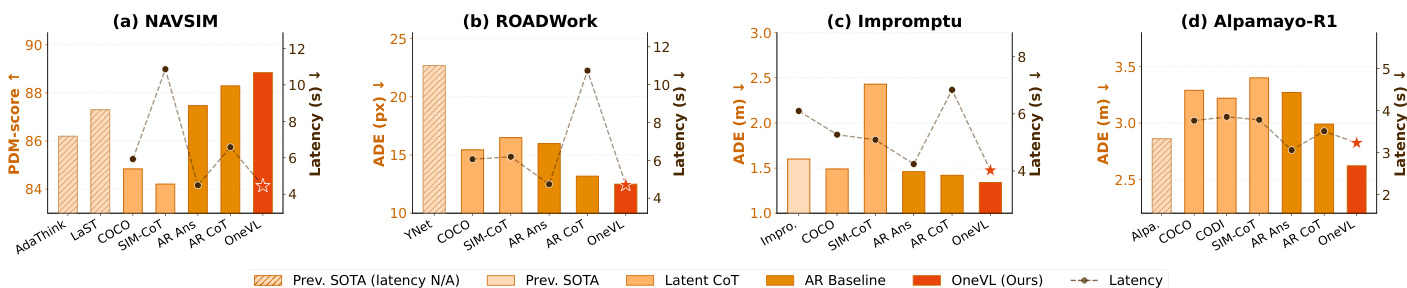
作者通过各种对比实验评估了 OneVL,重点关注多个自动驾驶基准测试中的推理效率、解释质量和轨迹预测准确度。结果表明,OneVL 在保持与仅回答模型相当的推理速度的同时,实现了最先进的性能和卓越的长期预测一致性。最终,研究结果强调,该模型的多模态辅助监督和分阶段训练方法对于有效的 latent 推理和实时部署至关重要。