Command Palette
Search for a command to run...
Agent-World:为演进式通用 agent intelligence 扩展真实世界环境合成规模
Agent-World:为演进式通用 agent intelligence 扩展真实世界环境合成规模
摘要
大语言模型正日益被期待作为通用型 agent,与外部的有状态工具环境进行交互。模型上下文协议(Model Context Protocol, MCP)以及更广泛的 agent 能力为将 agent 与可扩展的现实世界服务相连接提供了统一接口,但由于缺乏真实的训练环境以及原则性的终身学习机制,训练鲁棒的 agent 仍面临限制。在本文中,我们提出了 Agent-World,这是一个通过可扩展环境来提升通用 agent 智能的自我演进训练竞技场。Agent-World 包含两个核心组件:(1) Agentic 环境与任务发现(Agentic Environment-Task Discovery):该组件能从数千个现实世界环境主题中,自主探索与主题相关的数据库及可执行工具生态系统,并合成具有可控难度的可验证任务;(2) 持续自我演进的 agent 训练(Continuous Self-Evolving Agent Training):该组件将多环境强化学习与自我演进的 agent 竞技场相结合,通过动态任务合成自动识别能力差距并驱动针对性学习,从而实现 agent 策略与环境的协同演进。在 23 个具有挑战性的 agent 基准测试中,Agent-World-8B 和 14B 的表现持续优于强大的闭源商业模型及环境扩展基准。进一步的分析揭示了与环境多样性和自我演进轮数相关的扩展趋势(scaling trends),为构建通用 agent 智能提供了深刻见解。
一句话总结
ByteDance Seed 研究人员提出了 Agent-World,这是一个自我进化的训练竞技场,通过自主的 agentic 环境-任务发现和持续强化学习来扩展真实世界环境的合成,从而实现 agent 策略与可验证任务的协同进化,使得 Agent-World-8B 和 14B 模型在 23 个 agent 基准测试中始终优于强大的闭源模型和环境扩展基准。
核心贡献
- 本文介绍了 Agent-World,这是一个旨在通过可扩展且真实的工具环境来提升通用 agent intelligence 的自我进化训练竞技场。
- 该框架包含一个 Agentic Environment-Task Discovery 组件,利用真实的 MCP server 元数据自主挖掘主题相关的数据库和可执行工具集,同时合成具有可控难度的可验证任务。
- 研究提出了一种 Continuous Self-Evolving Agent Training 机制,将多环境强化学习与诊断竞技场相结合,以识别能力差距并驱动有针对性的迭代学习,在 23 个基准测试中实现了优于强大闭源模型和扩展基准的性能。
引言
随着大语言模型向通用 agent 演进,需要与复杂的、具有状态的工具环境进行交互以执行现实世界的任务。目前的训练方法面临重大障碍,因为现实世界的服务通常难以获取,而手动构建的沙箱扩展成本极高。此外,现有的强化学习方法通常在固定分布上优化策略,而不是适应新挑战。研究人员利用名为 Agent-World 的新型框架,通过自我进化的训练竞技场来解决这些问题。该系统自主发现现实世界的工具生态系统和数据库以合成可验证任务,同时使用持续的强化学习循环,通过有针对性的环境扩展来识别并弥补 agent 的能力差距。
数据集
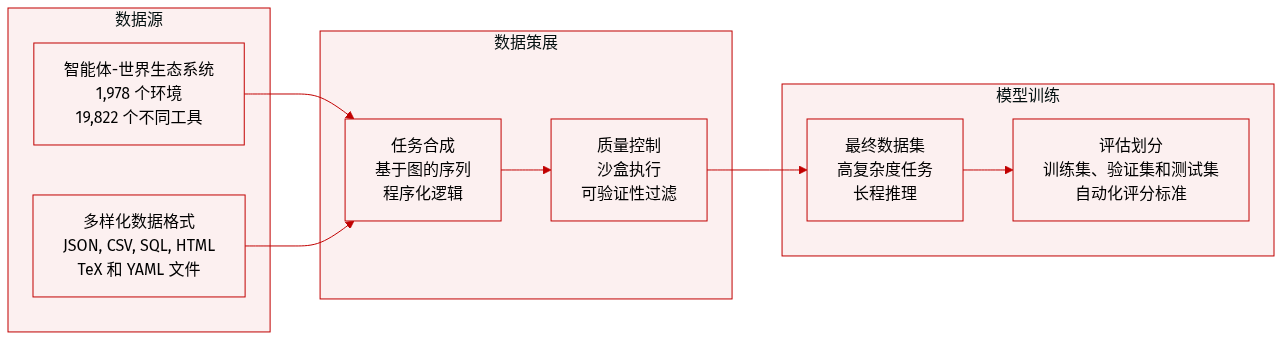
数据集描述
研究人员引入了一个可扩展的 agentic 环境和合成任务生态系统,旨在模拟复杂的现实世界工具使用场景。
数据集构成与来源 数据集构建在 Agent-World 生态系统之上,包括:
- 环境: 超过 1,978 个经过筛选的环境,涵盖了多样化的领域,如本地 arXiv 库、电子邮件收件箱(Enron 数据集)、日历服务、酒店预订系统、社交应用元数据(Instagram, TikTok, WhatsApp)以及外卖平台。
- 工具: 分布在这些环境中的 19,822 个不同工具的集合。
- 数据格式: 多样化的文件类型,包括 JSON, CSV, SQL, HTML, TeX 和 YAML。
任务合成子集 研究人员利用两种主要策略来生成可验证任务:
- 基于图的任务 (Xgraph): 这些任务侧重于顺序工具依赖关系。研究人员构建了加权有向工具图,其中边代表强依赖、弱依赖或独立依赖。通过在这些图上进行随机游走来采样工具序列,随后使用真实数据填充并由 LLM 进行精炼。
- 程序化任务 (Xprog): 这些任务对非线性推理进行建模,例如循环和条件逻辑。LLM 生成复杂的任务查询和相应的可执行 Python 脚本。这种方法捕捉了简单顺序工具调用无法实现的行为。
处理与质量控制 为了确保高质量和可验证性,研究人员实施了若干严谨的处理步骤:
- 沙箱执行: 所有合成的工具序列和程序化脚本都在 Python 沙箱中执行,以收集执行轨迹并推导出标准答案(ground-truth)。
- 可验证性过滤: 只有通过稳定性测试的任务才会被保留,即 ReAct agent 必须在五次独立尝试中至少成功解决两次。
- 元数据构建: 对于每个任务,研究人员生成一个真实的查询、一个结构化的 JSON 标准答案,以及涵盖字段完整性、模式匹配和数值容差的详细评估准则。对于程序化任务,会生成专门的可执行验证脚本以进行多级断言。
- 难度扩展: 通过扩展工具链长度、增加非线性依赖频率以及重写任务描述以隐藏技术工具名称来提高复杂度,迫使 agent 从抽象目标中推断工作流。
数据使用 合成任务具有高交互复杂性的特点,每个任务平均超过 20 轮,许多超过 40 轮。该数据集旨在评估 agent 在多样化、自包含且离线的环境中执行长程推理、跨数据库聚合和复杂程序化控制流的能力。
方法
所提出的 Agent-World 框架由两个紧密耦合的组件组成:Agentic Environment-Task Discovery 和 Continuous Self-Evolving Agent Training,形成了一个用于可扩展环境-任务发现和 agent 策略精炼的闭环系统。整体架构将环境合成、任务生成和 agent 训练集成到一个动态的、自我改进的流水线中。
Agentic Environment-Task Discovery 首先从现实世界来源(包括 MCP server、工具文档和工业产品需求文档)收集多样化的环境主题。这些主题作为合成可扩展环境生态系统的锚点。随后进入 agentic 数据库挖掘阶段,配备了策略模型和外部工具的 deep-research agent 会自主挖掘并处理网络数据,以构建主题相关的数据库。这一工作流通过数据库复杂化过程得到增强,该过程迭代地丰富数据库,确保其满足现实需求。在数据库构建之后,coding agent 会生成基于该数据库的可执行工具接口,并配有单元测试。这些工具经过严格的交叉验证以确保功能性和可靠性,最终形成一个经过质量控制的工具集。合成的环境使用层次化分类法进行系统化组织,为跨环境任务合成和分层评估提供了结构化基础。 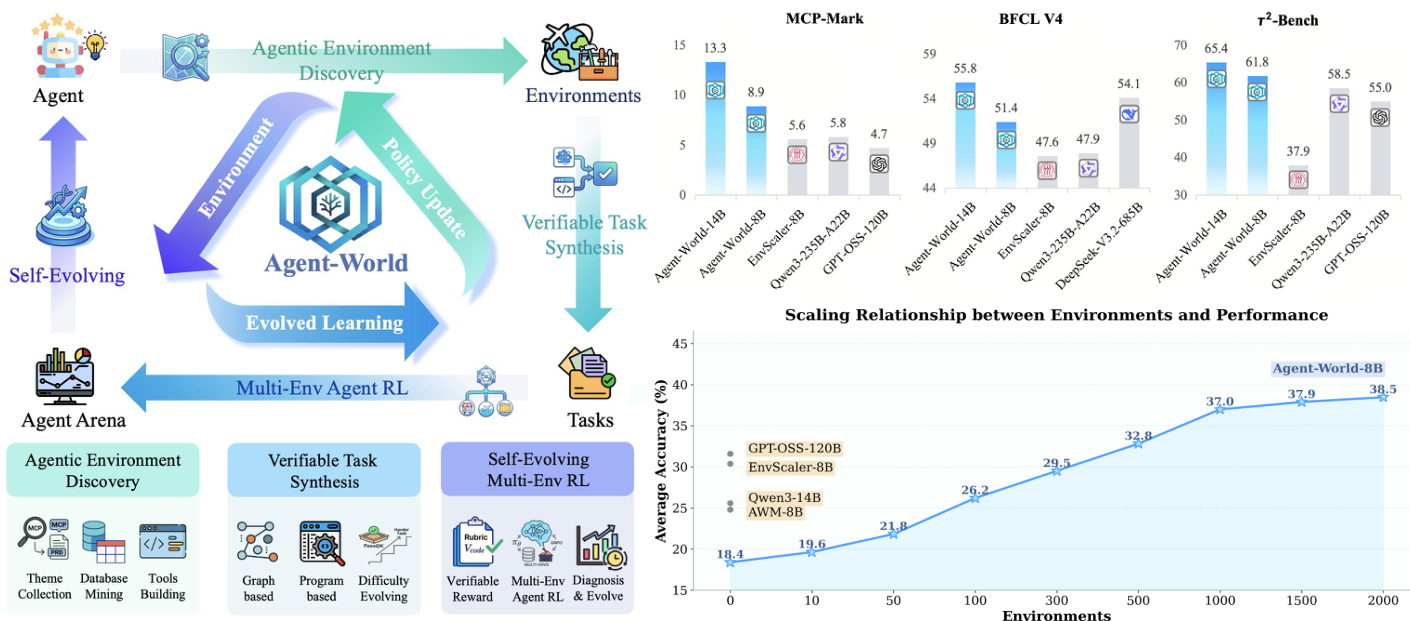
第二个组件 Continuous Self-Evolving Agent Training 利用可扩展的环境生态系统进行多环境强化学习。训练过程涉及策略模型、工具接口和数据库状态之间的闭环交互,使 agent 能够进行状态感知推理和长程工具使用。在每一步中,策略根据对话历史和工具反馈生成动作,在沙箱环境中触发工具执行以读取或更新数据库状态。收集交互轨迹和最终答案,并计算结构化的可验证奖励以指导策略优化。奖励信号源自两类任务:基于图的任务使用基于准则的 LLM judge 来评估准则级的通过指标,而程序化任务则采用可执行验证脚本来验证预测答案或生成的数据库状态。策略更新使用 Group Relative Policy Optimization (GRPO) 进行,通过优化带有对参考策略 KL 惩罚的裁剪目标来最大化可验证回报。 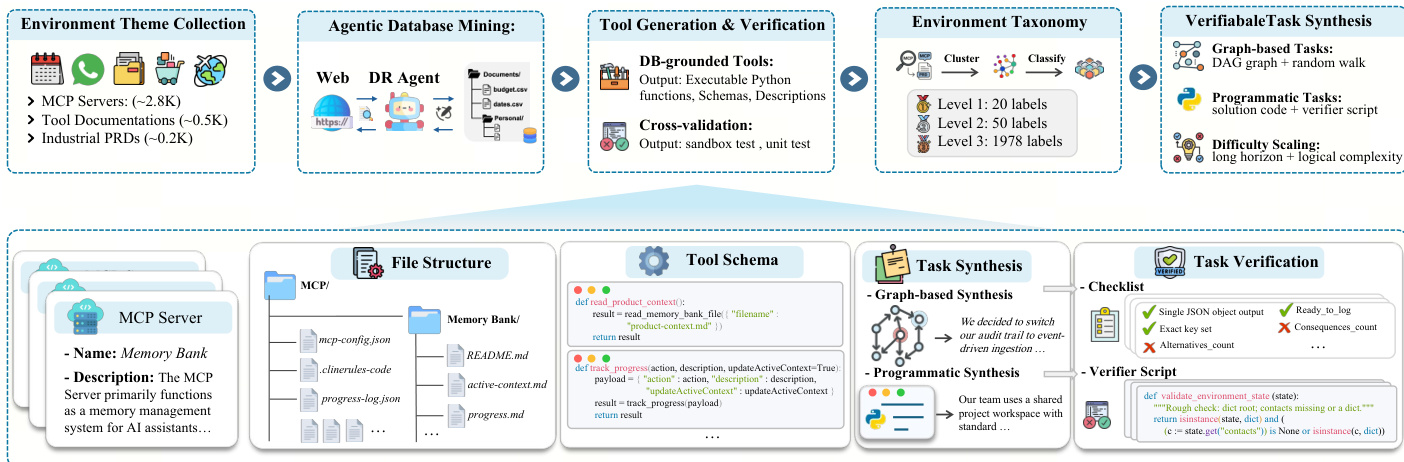
训练过程通过一个作为动态诊断平台的自我进化 agent 竞技场得到增强。该竞技场通过对层次化分类法进行分层采样构建,确保对不同环境类型具有广泛的覆盖。在每次迭代中,为采样环境合成新鲜的可验证任务,并使用可执行奖励评估 agent 策略。Agentic diagnosis agent 通过分析每个任务的执行轨迹、错误统计数据和环境元数据来分析失败模式,从而识别薄弱环境并生成有针对性的任务生成指南。这些见解驱动了一个协同进化过程,即扩展和精炼环境生态系统以解决能力差距,并通过持续的多环境 RL 更新 agent 策略。这种迭代循环实现了 agent 能力和底层环境生态系统的持续改进。 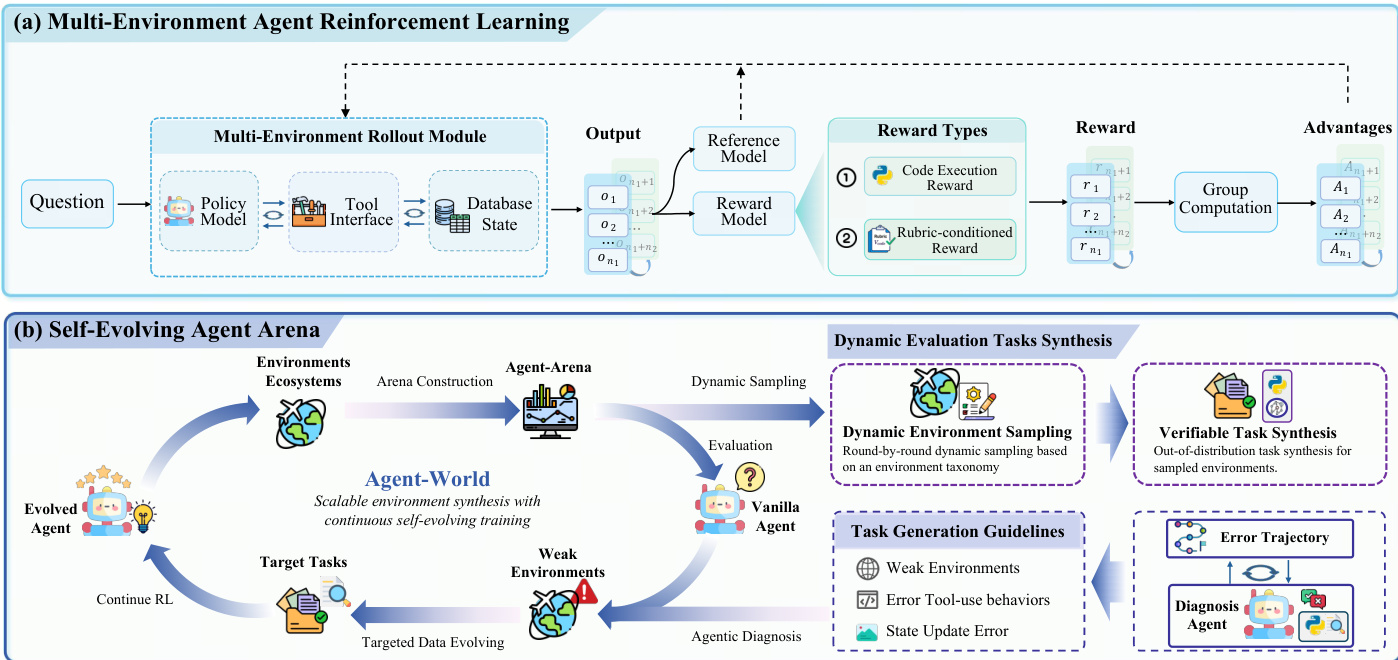
实验
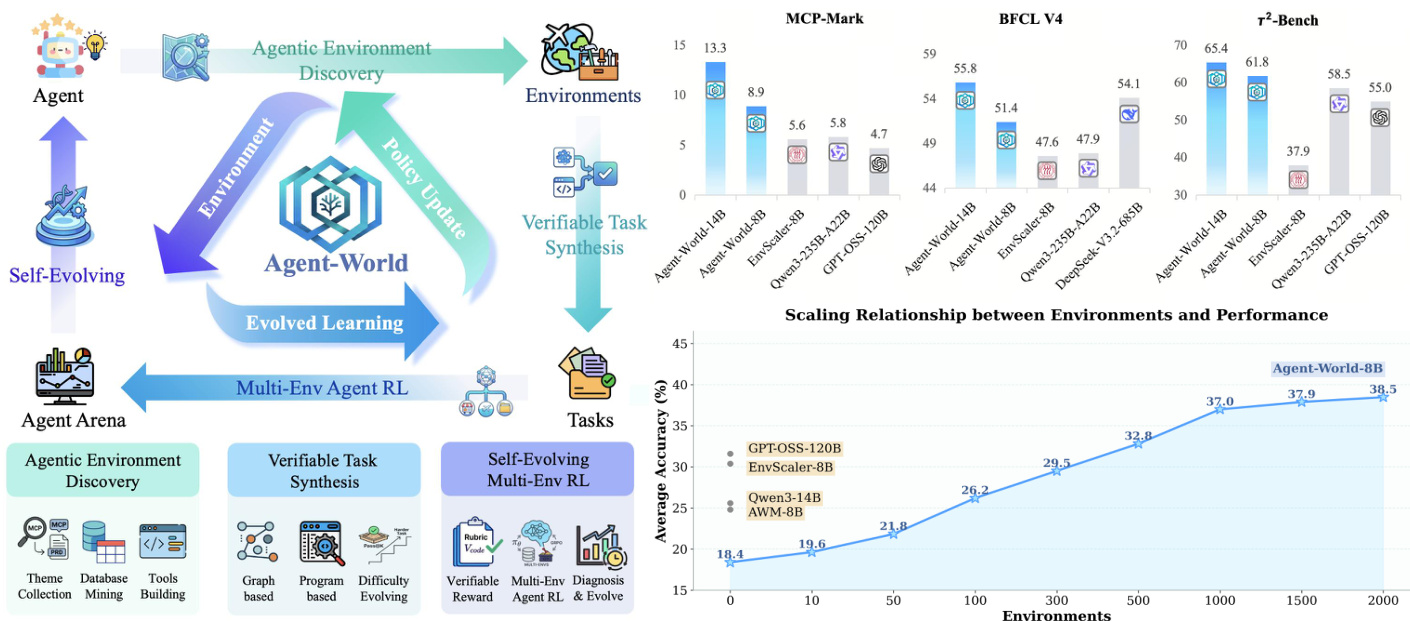
评估在 23 个不同的基准测试中对 Agent-World 进行测试,以验证其在 agentic 工具使用、软件工程、深度研究和通用推理方面的有效性。结果表明,与前沿闭源模型和现有的环境扩展基准相比,该统一框架提供了更优且更一致的跨环境泛化能力。分析进一步确认,agent 性能随合成环境数量的增加而呈正向扩展,并且持续的自我进化训练循环通过针对特定的能力差距驱动了持续的、单调的改进。
研究人员在涵盖工具使用、推理和 AI 助手任务的多个基准测试上评估了 Agent-World,这是一个集成了可扩展环境合成与持续自我进化训练的训练框架。结果显示,Agent-World 在不同环境中始终优于现有基准,随着模型规模的增加,展现出更强的泛化能力和更稳定的改进。该框架通过迭代自我进化实现了显著收益,特别是在需要长程规划和多工具协作的复杂、有状态场景中。Agent-World 在不同基准测试中始终优于先前的环境扩展方法和基础模型,在长程工具使用场景中表现出更强的泛化性。Agent-World 从 8B 到 14B 实现了稳定的改进,在不同任务类型中均有持续增长,表明其对复杂助手和推理领域的有效迁移能力。Agent-World 的性能随合成环境数量的增加而提升,其自我进化训练循环通过识别并解决 agent 行为中的能力差距,实现了单调的增益。
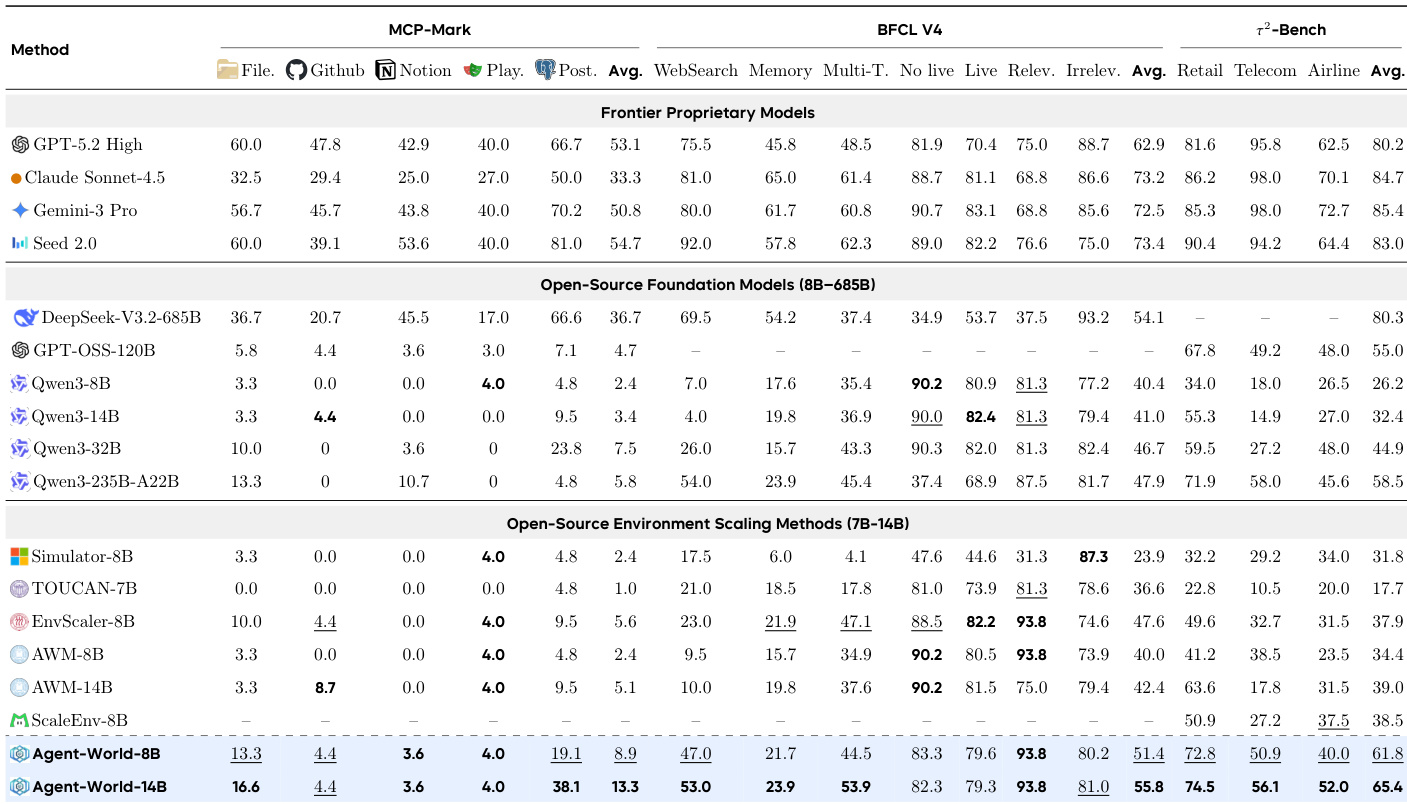
研究人员引入了 Agent-World,这是一个结合了可扩展环境合成与持续自我进化训练以提升 agent 性能的训练框架。结果显示,Agent-World 在不同基准测试中始终优于基准方法,在长程和有状态场景中具有更强的泛化能力。该框架证明,增加训练环境的数量可以提高性能,而迭代自我进化通过识别和解决能力差距来驱动持续的收益。Agent-World 在多个基准测试集中始终优于现有基准,在复杂、有状态的环境中表现出更强的泛化性。性能随训练环境数量的增加而提升,表明环境多样性与 agent 能力之间存在正向扩展关系。迭代自我进化通过诊断弱点并生成有针对性的训练任务来实现持续收益,从而实现策略的不断改进。
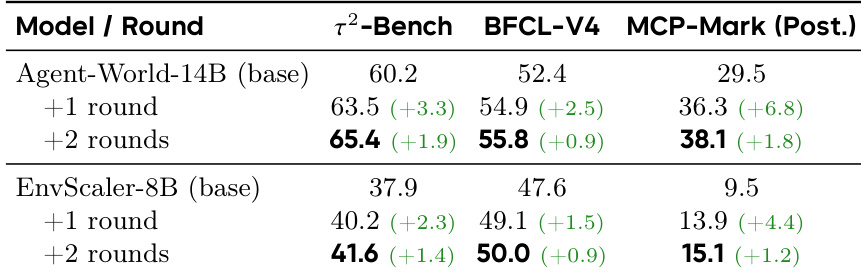
研究人员通过比较多轮训练后的性能提升,评估了其持续自我进化训练框架的有效性。结果显示,Agent-World-14B 和 EnvScaler-8B 在每一轮自我进化后都实现了持续的增益,其中 Agent-World-14B 展示了更强的整体提升,特别是在需要状态跟踪和多步协作的复杂基准测试上。增益随轮数增加而减小,表明在大规模下存在收益递减现象。Agent-World-14B 在每一轮自我进化后在所有评估的基准测试中都实现了持续的性能提升,其中在 MCP-Mark 上的改进最大。Agent-World-14B 和 EnvScaler-8B 在每一轮后都显示出正向改进,表明无论初始化如何,自我进化循环都能使模型受益。增益随轮数递减,表明早期轮次解决了主要的性能差距,而后期轮次提供了增量式的精炼。
研究人员在涵盖工具使用、推理和助手任务的多个基准测试上评估了 Agent-World 框架,以验证可扩展环境合成和持续自我进化训练的有效性。结果表明,该框架始终优于现有基准,特别是在需要多工具协作和状态跟踪的复杂、长程场景中。此外,实验表明,增加环境多样性并进行迭代自我进化循环,通过有效地解决 agent 能力差距,驱动了持续的性能提升。