Command Palette
Search for a command to run...
通过判别式文本表示将单步图像生成从类别标签扩展至文本
通过判别式文本表示将单步图像生成从类别标签扩展至文本
Chenxi Zhao Chen Zhu Xiaokun Feng Aiming Hao Jiashu Zhu Jiachen Lei Jiahong Wu Xiangxiang Chu Jufeng Yang
摘要
少步数生成(Few-step generation)一直是领域内的长期目标,近期以 MeanFlow 为代表的一步生成方法已取得了显著成果。现有关于 MeanFlow 的研究主要集中在类别到图像(class-to-image)的生成上。然而,一个直观但尚未被探索的方向是将条件从固定的类别标签扩展到灵活的文本输入,从而实现更丰富的内容创作。与有限的类别标签相比,文本条件对模型的理解能力提出了更高挑战,因此需要将强大的文本编码器(text encoders)有效地集成到 MeanFlow 框架中。令人惊讶的是,尽管引入文本条件看似简单直接,但我们发现,如果使用传统的训练策略来集成基于大语言模型(LLM)的强大文本编码器,其性能表现并不理想。为了揭示其根本原因,我们进行了详细分析,并发现由于 MeanFlow 生成过程中的细化步骤(refinement steps)极少(例如仅为一步),文本特征表示必须具备足够高的判别力(discriminability)。这也解释了为什么离散且易于区分的类别特征在 MeanFlow 框架内表现良好。基于这些洞察,我们利用了一个经验证具备所需语义特性的强大 LLM-based 文本编码器,并将 MeanFlow 生成过程适配到该框架中,从而首次实现了高效的文本条件合成(text-conditioned synthesis)。此外,我们在广泛使用的扩散模型(diffusion model)上验证了我们的方法,证明了生成性能的显著提升。我们希望这项工作能为未来关于文本条件 MeanFlow 生成的研究提供具有普适性且实用的参考。代码已发布于:https://github.com/AMAP-ML/EMF。
一句话总结
为了将 MeanFlow 从类别到图像(class-to-image)扩展到文本到图像(text-to-image)生成,本研究引入了一种判别式文本表示方法,通过确保文本特征具备足够的判别力,从而克服单步生成的挑战,实现从灵活语言输入中进行高质量的内容创作。
核心贡献
- 本研究首次系统性地探索并实现了将 MeanFlow 框架从固定类别标签条件扩展到灵活的文本到图像条件。
- 论文指出,少步生成需要具有高语义判别性和解耦性的文本表示,并解释了为什么基于 LLM 的编码器的传统训练策略在单步设置下往往会失败。
- 通过将基于 BLIP3o-NEXT LLM 的文本编码器集成到 MeanFlow 框架中,所提出的方法实现了具有竞争力的单步文本到图像合成,并显著提升了生成质量。
引言
高效的文本到图像生成对于降低多步扩散模型带来的高昂计算成本至关重要。虽然 MeanFlow 已成为实现高质量单步生成的一种原则性框架,但现有研究很大程度上局限于类别标签条件,而非灵活的文本输入。以往尝试将强大的基于 LLM 的文本编码器集成到 MeanFlow 框架中的做法往往效果不佳,因为标准训练策略未能考虑到有限去噪步数的特殊需求。通过识别出成功的少步生成需要具有高语义判别性和解耦性的文本表示,以减轻模型的语义负担,研究人员解决了这一问题。通过利用具有这些特定属性的基于 LLM 的文本编码器,研究人员引入了 EMF,这是第一个能够有效实现文本条件 MeanFlow 生成的框架。
方法
通过调整其核心架构以支持双向时间条件并集成判别式文本表示空间,研究人员利用 MeanFlow 框架实现了高效且准确的文本到图像生成。该方法的核心组件是一个速度网络,用于预测流映射 uθ(zt,t,r),它通过转换方程 zr=zt+(r−t)uθ(zt,t,r)(对于 r>t)将时间 t 处的潜状态 zt 直接映射到时间 r 处的状态 zr。这种公式避免了推理过程中标准流匹配(flow matching)所需的计算昂贵的 ODE 积分。训练该网络的训练目标源自通过沿轨迹对转换方程求导获得的自洽关系,得到目标速度场 u~(zt,t,r)=v(zt,t)+(r−t)dtduθ(zt,t,r),其中全导数通过 Jacobian-vector products 高效计算。模型通过最小化 MeanFlow 损失 LMF(θ)=Et,zt,r[∥uθ(zt,t,r)−sg(u~(zt,t,r))∥2] 进行训练,并在目标上应用停止梯度(stop-gradient)算子以稳定优化。
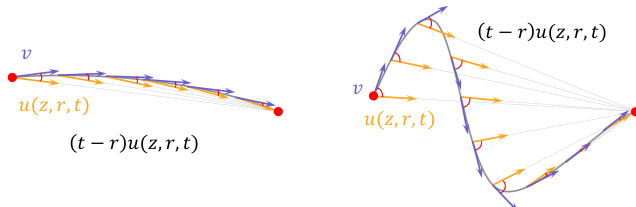
如下图所示,MeanFlow 框架使用流映射 u(z,r,t) 来模拟潜状态之间的转换,该映射近似于区间 [r,t] 上的平均速度。速度场 v 代表瞬时变化率,而项 (t−r)u(z,r,t) 代表该区间内的累积位移。图中说明,对于平滑轨迹,流映射 u(z,r,t) 与平均速度紧密一致,但在涉及文本条件的更复杂情况下,路径会变得曲折,导致瞬时速度与平均速度之间出现显著偏差。这种偏差是语义漂移的主要来源,需要额外的修正迭代来实现收敛。
为了使 MeanFlow 适应文本到图像生成,研究人员修改了标准流匹配架构以支持双向时间条件。与传统模型中使用的单一时间嵌入 ϕtime(t) 不同,改进后的框架引入了两个不同的时间嵌入层:ϕinterval(⋅) 用于编码区间长度 t−r,以及 ϕend(⋅) 用于编码片段结束时间 t。组合后的条件时间嵌入构建为 ϕcond(t,r)=ϕinterval(t−r)+ϕend(t)。该嵌入与判别式文本编码器产生的文本特征 ψtext(xtext) 共同对速度网络进行条件化,速度网络定义为 νθ(zt,t,r,ψtext)=fθ(zt,ϕcond(t,r),ψtext)。

训练过程对时间步 (t,r) 采用自适应采样策略,从均匀分布或参数为 μ(p) 和 σ(p) 的 logit-normal 分布中采样,这些参数随训练进度 p∈[0,1] 进行插值。非等距时间步(t=r)的比例被自适应增加,以确保对短程和长程片段的均衡暴露,从而促进对平均速度场的稳定学习。完整的训练目标是最小化标准 MeanFlow 损失,其中目标 utgt 定义为 νtgt=vθ(zt,t,ψtext)+(r−t)dtduθ(zt,t,r,ψtext),其中导数项通过 Jacobian-vector products 计算,并对 utgt 应用停止梯度算子。这种改进使模型能够处理文本条件增加的复杂性,即使在单步模式下也能实现准确且语义忠实的生成。
实验
研究人员通过比较各种文本编码器和采样步数配置,评估了将 MeanFlow 框架应用于文本到图像生成的有效性。通过 GenEval 和 DPG-Bench 等基准测试,实验表明,具有强判别性和解耦性的高质量文本表示对于在少步生成期间保持语义完整性至关重要。结果显示,所提出的方法在仅需四步的情况下即可实现卓越的指令遵循能力和视觉细节,有效地与速度慢得多的基线模型相媲美,并且随着采样步数的增加能够平滑扩展。
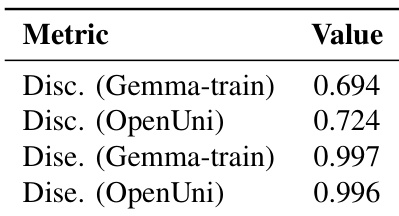
研究人员比较了不同的文本编码器在支持少步图像生成方面的能力,重点关注判别性和解耦性。结果显示,BLIP3o-NEXT 在评估的模型中获得了最高分,表明在对齐文本和图像表示方面具有卓越性能。分析强调,具有强判别能力的模型在少步生成场景中更为有效。BLIP3o-NEXT 在通过极少步数生成高质量图像方面优于其他文本编码器。判别性是决定文本表示在少步图像生成中有效性的关键因素。评估显示,具有更强文本-图像对齐能力的模型在低步数推理设置下取得了更好的结果。

研究人员基于判别性和解耦性属性评估文本编码器,使用了源自图像-文本检索和子序列相似性的指标。结果表明,某些文本编码器表现出很强的判别性和解耦性,其中一些在判别性或解耦性等特定方面表现出更高的性能,这可能会影响其在少步图像生成中的有效性。文本编码器在判别性和解耦性方面存在差异,一些编码器在文本和图像表示之间表现出更强的对齐。某些编码器的解耦性能很高,表明嵌入中语言结构的保留更好。不同编码器的判别性指标有所不同,表明图像-文本对齐和检索质量的水平不同。
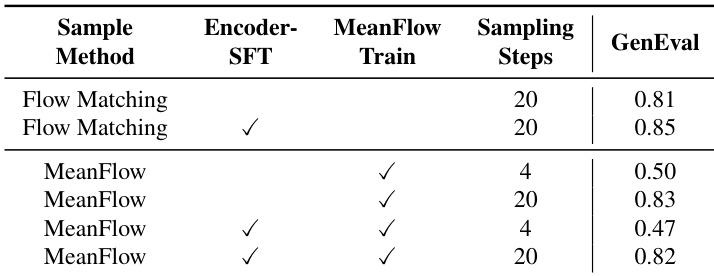
研究人员比较了图像生成模型的不同训练和采样配置,重点关注 MeanFlow 训练和采样步数对生成质量的影响。结果显示,MeanFlow 训练在较少的采样步数下即可提高性能,但 SFT 与 MeanFlow 训练的结合在各种步数设置下都能带来更高质量的输出。模型在推理速度和视觉保真度之间实现了平衡,在较高的采样步数下效果更好。与标准 Flow Matching 相比,MeanFlow 训练在较少的采样步数下提高了生成质量。SFT 与 MeanFlow 训练的结合在不同的采样步数设置下均产生了更好的结果。在 MeanFlow 框架中,较高的采样步数会带来视觉保真度和性能的提升。
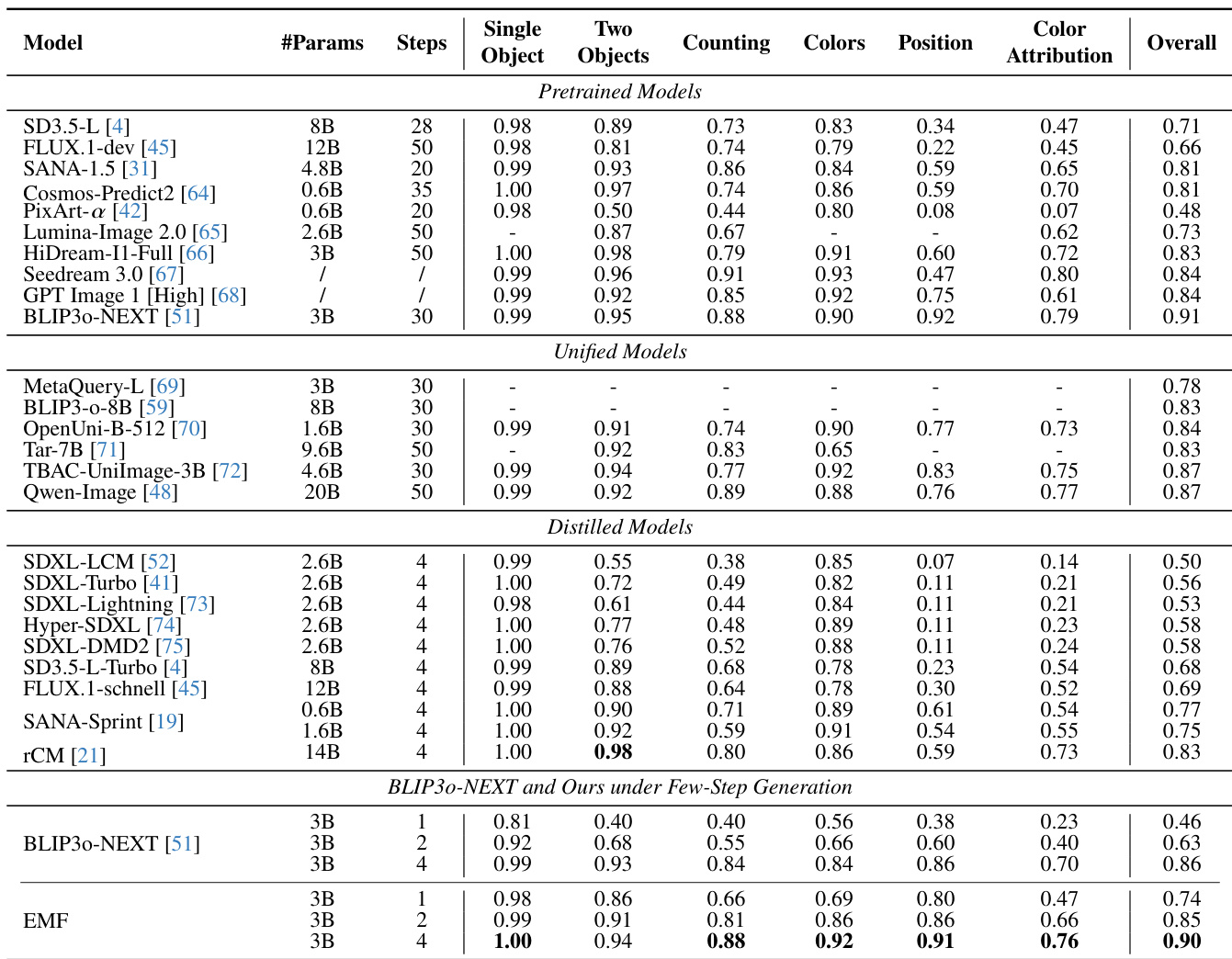
研究人员在多个基准测试中将该方法与各种预训练、统一和蒸馏模型进行了比较,重点关注少步生成性能。结果显示,该方法在保持高质量图像生成的同时,在少步设置下达到了与最先进模型相当或更优的性能。该方法即使在采样步数非常少的情况下也表现出强大的语义忠实度和视觉细节,优于蒸馏模型,并能与需要更多步数的大型模型相媲美。所提出的方法在极少的采样步数下即可实现高性能,匹配或超过了需要显著更多步数的模型的结果。该方法在具有挑战性的基准测试中优于蒸馏模型,特别是在保留细粒度细节和遵循复杂文本指令方面。该方法在不同的采样步数配置下表现出鲁棒性和稳定性,即使在低步数下也能保持高质量生成。
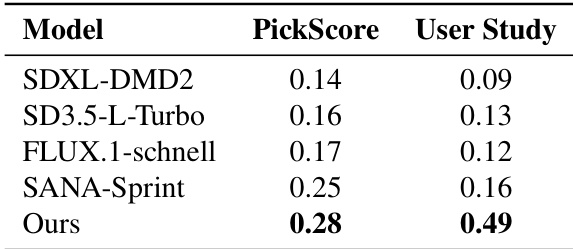
研究人员通过用户研究和 PickScore 指标评估了该模型与几种最先进的文本到图像生成模型在指令遵循和语义忠实度方面的表现。结果显示,该方法在两项指标上均优于其他模型,表明在少步生成下与文本提示的对齐度更高,且视觉细节保留更强。随着采样步数的减少,性能差距进一步扩大,突显了该方法在低步数机制下的鲁棒性。该模型获得了最高的 PickScore 和用户研究评分,在指令遵循和语义忠实度方面优于其他模型。该方法的性能优势在低步数生成中变得更加明显,表明在受限采样下的鲁棒性。与蒸馏模型相比,该模型能够产生更准确、更详细的图像,特别是在复杂的文本提示下。
研究人员评估了各种文本编码器、训练配置和生成方法,通过判别性、解耦性和语义忠实度指标来优化少步图像生成。结果表明,卓越的文本-图像对齐以及 SFT 与 MeanFlow 训练的结合,对于在低步数推理期间保持高视觉质量至关重要。最终,所提出的方法通过在高度受限的采样设置下提供鲁棒的指令遵循和细粒度细节保留,优于现有的蒸馏模型和最先进模型。