Command Palette
Search for a command to run...
AdaExplore:面向高效内核生成的失败驱动自适应与多样性保持搜索
AdaExplore:面向高效内核生成的失败驱动自适应与多样性保持搜索
摘要
近年来,大型语言模型(LLM)智能体在利用执行反馈进行测试时适应(test-time adaptation)方面展现了巨大潜力。然而,实现稳健的自我改进仍面临巨大挑战:大多数方法仍将每个问题实例视为独立个体,未能积累可复用的知识。这一局限性在领域特定语言(如 Triton)中尤为明显,因为这类语言在 LLM 预训练数据中的代表性不足。Triton 等语言严格的约束条件及非线性的优化景观,使得简单的生成和局部细化策略变得不可靠。为此,我们提出了 AdaExplore,这是一种智能体框架,通过两个互补阶段——“故障驱动的适应”(failure-driven adaptation)和“多样性保持搜索”(diversity-preserving search),利用累积的执行反馈来优化对性能至关重要的内核代码(kernel code)生成。该框架在不依赖额外微调或外部知识的情况下,同时提升了代码的正确性与优化性能。在适应阶段,智能体合成任务并将重复出现的错误转化为有效性规则的可复用记忆库,从而帮助后续的生成过程保持在可行解空间内。在搜索阶段,智能体将候选内核组织为树状结构,并在微小的局部细化与较大的结构重生之间交替进行,使其能够探索局部最优解之外的更广阔的优化景观。
一句话总结
AdaExplore 是一个 agent 框架,通过累积执行反馈实现自我改进,用于在特定领域语言(如 Triton)中生成性能关键的内核代码。该框架利用故障驱动适应将重复出现的故障转化为可复用的有效性规则,并通过多样性保持搜索探索局部最优之外的优化景观,在不进行额外微调或依赖外部知识的情况下,共同提高正确性和优化性能。
核心贡献
- AdaExplore 是一个 agent 框架,通过累积执行反馈实现性能关键内核代码生成的自我改进,无需额外微调。该框架通过两个互补阶段,在像 Triton 这样的特定领域语言中共同提高正确性和优化性能。
- 故障驱动适应阶段合成任务,并将重复出现的故障转化为可复用的有效性规则记忆,以确保后续生成保持在可行集内。该过程提炼跨任务的迁移性故障模式,为未来生成积累可复用知识。
- 多样性保持搜索阶段将候选内核组织为树,交替进行小局部优化和较大结构再生。实验表明,该策略探索了局部最优之外的优化景观,在 GPT-5-mini 作为基础模型的情况下,100 步预算下在 Level-3 上实现了 72 倍的提升。
引言
大型语言模型 agents 越来越多地应用于性能关键的 GPU 内核生成,但特定领域语言(如 Triton)在训练数据中代表性不足。现有方法通常独立处理每个问题实例,阻碍了可复用知识的积累,由于严格正确性约束,使得朴素生成不可靠。为解决这一问题,作者提出了 AdaExplore,一个通过故障驱动适应和多样性保持搜索实现自我改进的 agent 框架。适应阶段将重复出现的执行错误转化为可复用的有效性规则记忆,以确保可行性。同时,搜索阶段将候选内核组织为树,以平衡局部优化与结构再生。这种组合使系统能够有效导航非线性优化景观,而无需额外微调或外部知识。
数据集
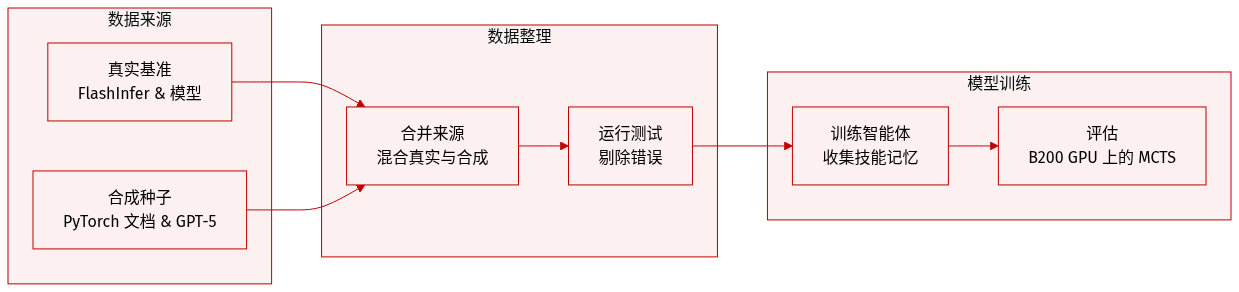
- 数据集组成与来源
- 作者采用混合方法,结合现实基准测试与合成生成。评估任务源自 FlashInfer-Bench,从涉及已部署模型(如 Llama-3.1-8B 和 Qwen3-30B-A3B)的生产推理管道中提取内核任务。训练数据通过基于变异的提示创建,使用 PyTorch 文档中的算子。
- 每个子集的关键细节
- FlashInfer-Bench: 包含三个特定的内核定义,包括 Fused Add RMSNorm、来自 Qwen3 MoE 门的 GEMM,以及来自 Llama-3.1 的 GQA Paged Decode。性能基线包括专家编写的 FlashInfer CUDA 内核,用于 SGLang 等生产框架。
- 合成训练集: 通过采样三个种子任务示例和算子生成。GPT-5 通过变异和重组现有模式生成新的 PyTorch 模块,以维持与种子示例相似的复杂度。
- 模型使用与处理
- 合成任务使 agent 能够从内核实现尝试中收集跨任务技能记忆。
- FlashInfer-Bench 仅用于评估,以评估真实世界 LLM 服务工作负载上的性能。
- 基线比较针对 PyTorch eager 引用和可用的 cuBLAS 进行。
- 过滤与配置
- 生成的代码在合成测试张量上执行,任何导致错误的样本均被丢弃。
- 变异策略引入低级变化,迫使 agent 进入边缘情况以进行更好的记忆存储。
- 评估运行遵循特定的 MCTS 配置,在 NVIDIA B200 GPU 上运行 50 步。
方法
作者将内核运行时优化表述为程序重写问题,目标是将高级实现转换为低级内核,在保留功能的同时最大化性能。为了导航涉及正确性和性能约束的复杂搜索空间,提出的 AdaExplore 框架通过两个不同的阶段运行:Adapt 和 Explore。
请参阅框架图以了解 AdaExplore Agent 的整体架构。系统分为左侧的 Adapt 模块,专注于从故障中学习技能,以及右侧的 Explore 模块,执行多样性保持搜索。
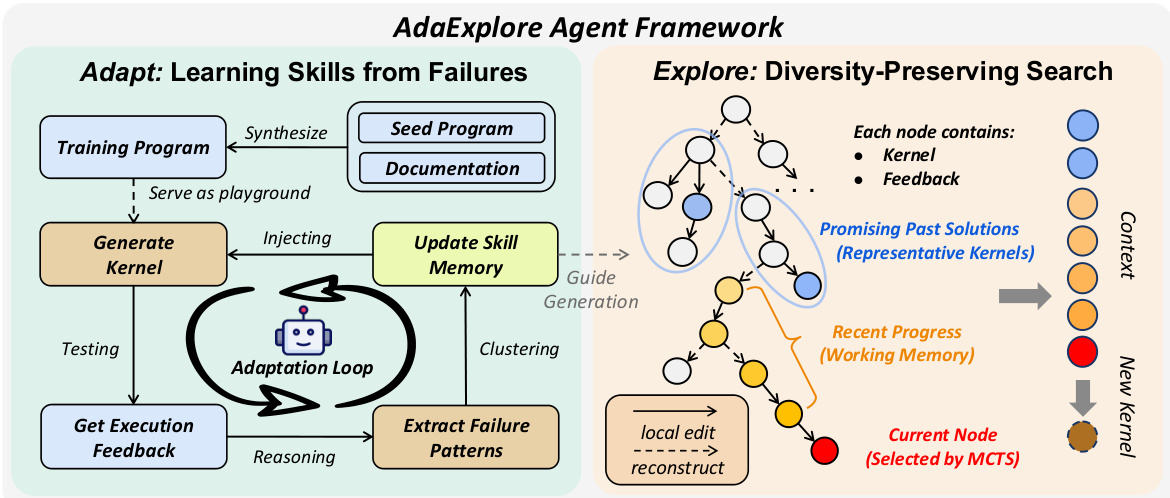
Adapt 组件通过学习可复用约束解决可行性瓶颈。经验表明,内核生成故障通常源于少量重复出现的语法错误或结构约束。作者不依赖额外的模型训练,而是通过在合成任务上的自我探索来适应 agent 的知识。管道通过重组参考实现中的算子生成多样化的训练任务。agent 尝试为这些任务生成内核,并收集执行故障。这些故障被总结为简洁的约束规则,然后根据频率进行聚类和过滤,以构建紧凑的跨任务技能记忆,仅保留频率高于阈值 O 的规则。此记忆暴露给后续任务,使方法能够转移经验并避免先前观察到的故障模式。
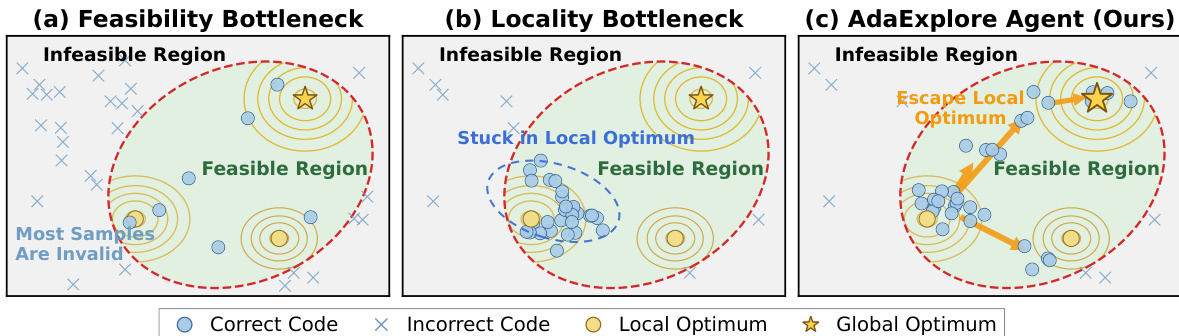
如下图所示,AdaExplore Agent 旨在克服可行性和局部性瓶颈。虽然标准方法可能在高比例无效样本或陷入可行区域内的局部最优方面遇到困难,AdaExplore Agent 利用学到的技能保持有效性,并使用搜索策略逃离局部最优以趋向全局最优。
Explore 组件通过维护候选树而非单一优化链来促进高性能内核的搜索。此结构允许同时保留多个有前景的方向。在每一步,agent 使用平衡探索和利用的 UCT 风格规则选择要扩展的节点。扩展涉及两个更新算子之一。
Small Step 算子执行基于补丁的局部优化。它在纠正错误或调整局部选择的同时保留整体内核结构。agent 被提示识别具体修改并以 old_str/new_str 格式输出代码补丁。请参阅 Small-Step Tuning Prompt 以了解此阶段提供给模型的具体说明。

Large Step 算子在结构级别再生内核,以鼓励替代策略和更广泛的探索。对于此操作,工作记忆被清除,以帮助 agent 摆脱当前的优化链。模型的任务是生成一个可能优于池中最佳现有内核的内核。请参阅 Large-Step Reconstruction Prompt 以了解给予 agent 的目标和约束。

上下文管理对于平衡局部优化与全局探索至关重要。扩展节点时,模型基于包含最近编辑和反馈的工作记忆,以及从早期搜索阶段提取的代表性内核池进行条件设置。对于小步骤,模型依赖局部工作记忆以保持在当前分支中。对于大步骤,代表性内核提供高性能信号,而不受直接历史的偏见影响。这种双记忆设计确保搜索保持多样性,同时有效利用过去的进展。
实验
实验在核优化基准上评估 AdaExplore 与代表性基线,以评估不同复杂度任务的正确性和运行时效率。发现表明,结合树形搜索与跨任务技能记忆使模型能够通过平衡结构探索与迭代优化来实现卓越性能。消融研究确认了特定组件(如双动作更新和记忆保留)的必要性,而案例研究证明了系统生成内核的能力,这些内核可以在特定工作负载上超越专家编写的实现。
作者在 FlashInfer-Bench 任务上评估内核生成,将性能与 PyTorch 和专家 CUDA 基线进行比较。结果表明,虽然 agent 可以在特定内存受限工作负载(如 RMSNorm)上超越专家性能,但在 GEMM 等操作上难以匹配高度优化的供应商库。agent 生成了一个优于专家 CUDA 基线的 RMSNorm 内核。GEMM 内核相对于 PyTorch 和专家基线表现不佳。GQA 内核在 PyTorch 上实现了高加速比,但落后于专家实现。

作者指定了其方法中 ADAPT 和 EXPLORE 阶段的超参数配置。ADAPT 阶段涉及合成一组任务以收集经验,而 EXPLORE 阶段利用具有定义上下文窗口和内核池的树搜索策略。扩展系数根据任务难度调整,较高值用于较简单任务以促进探索,较低值用于较难任务以专注于当前分支。ADAPT 阶段从合成训练任务集中收集原始经验。EXPLORE 阶段使用代表性内核池和最近上下文窗口来指导搜索。扩展系数为较简单任务设置较高,为较难任务设置较低,以平衡探索和聚焦。

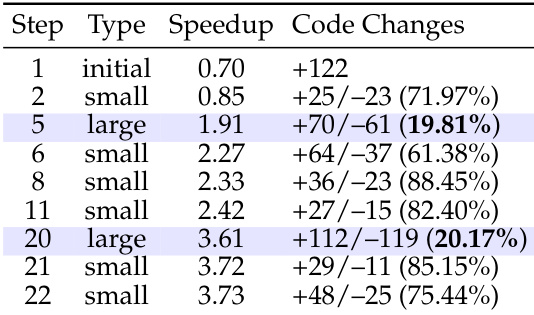
该表描绘了一个优化轨迹,其中 agent 在局部优化和主要结构更新之间交替。大步骤引入显著代码变化,与先前版本相似度低,推动实质性性能跳跃。相比之下,小步骤保留高代码相似度,促进稳定、渐进的加速比改进。大步骤对应于产生重大加速比收益的结构大修。小步骤涉及提供渐进性能优化的微小代码编辑。在这些步骤类型之间交替允许突破优化和稳定的渐进进展。
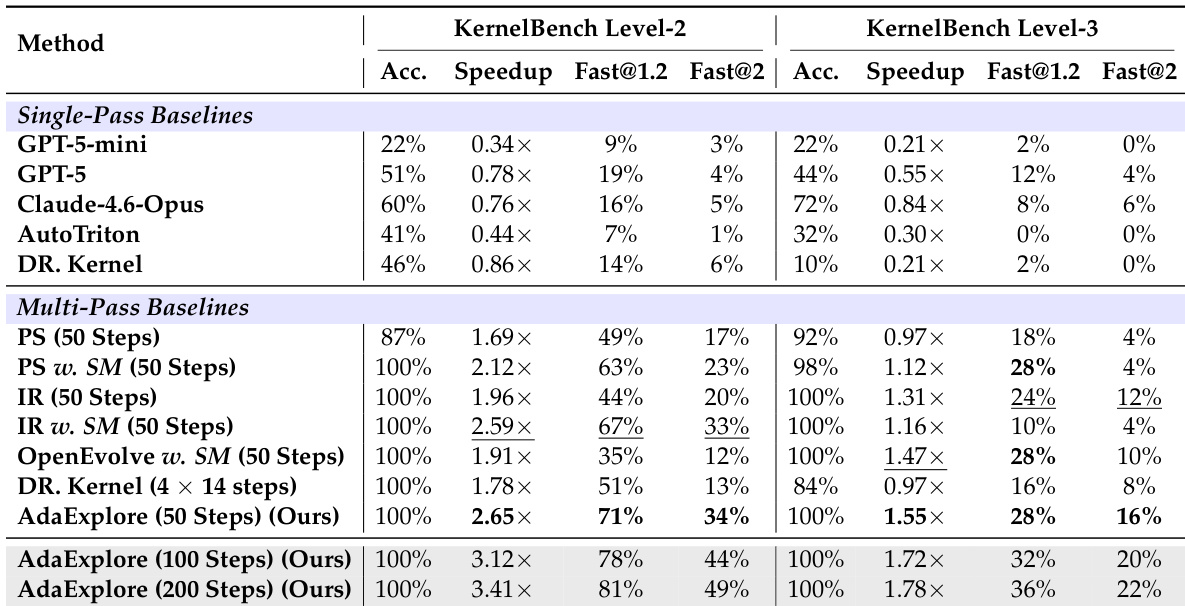
作者在 KernelBench Level-2 和 Level-3 任务上将提出的 AdaExplore 方法与各种单遍和多遍基线进行比较。虽然多遍策略通常比单遍模型实现更高的准确率,AdaExplore 始终提供最高的加速比和最大比例的具有显著性能提升的内核。此外,结果表明增加搜索预算允许 AdaExplore 进一步提高其优化性能。AdaExplore 在两个难度级别上都实现了最佳的加速比和优化成功率总体性能。多遍基线恢复高准确率,但在最大化内核执行速度方面落后于 AdaExplore。测试时缩放随着计算预算增加导致一致的性能提升。
作者使用固定的跨任务技能记忆评估其方法在不同 GPU 代际上的泛化能力。评估表明,该方法在 L40S、A100 和 GB200 架构上实现了高正确性和显著加速比,无需重新训练。正确性在所有测试架构上保持在近乎完美的水平。在旧版和新版 GPU 代际上均实现了显著加速比。Blackwell 架构上的性能与 Ampere 代相当。

该研究通过将提出的方法与 PyTorch、专家 CUDA 基线和各种搜索策略进行比较,评估了 FlashInfer-Bench 和 KernelBench 上的内核生成。虽然 agent 在 RMSNorm 等内存受限工作负载上超越专家性能,尽管在多遍基线上实现了最高加速比,但在 GEMM 操作上通常落后于优化的供应商库。此外,优化轨迹在结构大修和渐进优化之间交替以最大化收益,并且该方法在不同 GPU 代际上保持了高正确性和加速比,无需重新训练。