Command Palette
Search for a command to run...
阐明 Diffusion Probabilistic Models 的 SNR-t Bias
阐明 Diffusion Probabilistic Models 的 SNR-t Bias
Meng Yu Lei Sun Jianhao Zeng Xiangxiang Chu Kun Zhan
摘要
Diffusion Probabilistic Models 在广泛的生成任务中展现出了卓越的性能。然而,我们观察到这些模型经常受到“信噪比-时间步”(Signal-to-Noise Ratio-timestep, SNR-t)偏差的影响。这种偏差是指在 inference 阶段,去噪样本的 SNR 与其对应的时间步(timestep)之间存在失配。具体而言,在 training 过程中,样本的 SNR 与其 timestep 是严格耦合的;但在 inference 过程中,这种对应关系会被打破,从而导致误差累积并损害生成质量。我们提供了详尽的实证证据和理论分析来证实这一现象,并提出了一种简单且有效的微分校正(differential correction)方法来缓解 SNR-t 偏差。基于扩散模型在 reverse denoising 过程中通常先重建低频分量、随后才关注高频细节的特性,我们将样本分解为不同的频率分量,并对每个分量分别应用微分校正。大量实验表明,我们的方法在多种分辨率的数据集上,都能显著提升各类扩散模型(包括 IDDPM、ADM、DDIM、A-DPM、EA-DPM、EDM、PFGM++ 和 FLUX)的生成质量,且计算开销几乎可以忽略不计。代码地址:https://github.com/AMAP-ML/DCW
一句话总结
为了缓解由于推理过程中样本 SNR 与 timesteps 之间不匹配导致的信噪比-时间步 (SNR-t) 偏差,作者提出了一种微分修正方法。该方法将样本分解为频率分量,以增强各种扩散模型的生成质量,包括 IDDPM、ADM、DDIM、A-DPM、EA-DPM、EDM、PFGM++ 和 FLUX,且计算开销微乎其微。
核心贡献
- 本文识别了扩散概率模型中的信噪比-时间步 (SNR-t) 偏差,并提供了理论分析和实证证据,解释了推理过程中样本 SNR 与 timesteps 之间的这种不匹配如何导致误差累积。
- 引入了一种小波域内的动态微分修正方法,通过将样本分解为频率分量,并根据模型在重建高频细节之前倾向于重建低频轮廓的特性应用针对性修正,从而缓解这种偏差。
- 大量实验表明,这种无需训练且即插即用的方法在多种数据集上显著提高了包括 IDDPM、EDM 和 FLUX 在内的各种模型的生成质量,且计算开销极低。
引言
扩散概率模型 (DPMs) 已成为图像、音频和视频合成等高质量生成任务的核心。然而,这些模型经常受到信噪比-时间步 (SNR-t) 偏差的影响,即推理过程中样本的信噪比偏离了训练期间与其 timestep 严格耦合的比例。这种由累积预测误差和离散化误差引起的不匹配,会导致噪声预测不准确并降低生成质量。作者通过理论和实证分析识别了这一根本偏差,并提出了一种无需训练、即插即用的微分修正方法。通过在小波域内应用这种修正,作者使模型能够分别处理不同的频率分量,从而有效地将预测的样本分布与理想的扰动分布对齐。
方法
作者利用了扩散概率模型 (DPM) 框架,该框架通过前向扩散过程和反向去噪过程运行,两者均被建模为马尔可夫链。前向过程根据方差计划 βt 逐渐向数据样本 x0 添加高斯噪声,从而产生一系列噪声样本 x1,…,xT。该过程定义为 q(x1:T∣x0)=∏t=1Tq(xt∣xt−1),其中 q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)。作为生成核心的反向过程旨在逐步反转这一加噪步骤以恢复原始数据。通过训练神经网络 pθ(xt−1∣xt) 来逼近反向转移分布 q(xt−1∣xt,x0),具体是预测 timestep t 处存在的噪声 ϵt。该网络 ϵθ(⋅) 的训练目标是最小化其预测噪声与实际噪声 ϵt 之间的 L2 距离,从而得到简单的目标函数 Lsimple=Et,x0,ϵt∼N(0,I)[∥ϵθ(xt,t)−ϵt∥22]。训练完成后,模型可以通过从标准高斯噪声 xT 开始,并使用学习到的网络 pθ(xt−1∣xt) 进行迭代去噪来生成样本。
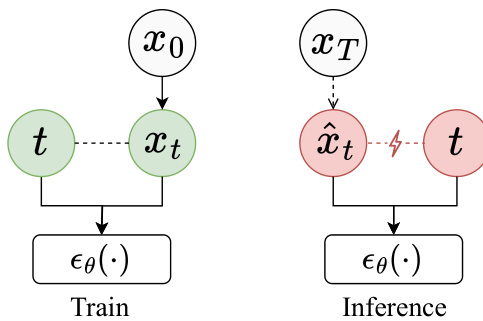
论文识别了该过程中的一个理论偏差,称为 SNR-t 偏差,即推理过程中预测样本 x^t 的信噪比 (SNR) 与其对应 timestep t 的预期 SNR 不匹配。为了解决这个问题,作者提出了一种微分修正方法。其核心思想是,预测样本 x^t−1 与重建样本 xθ0(x^t,t)(噪声预测网络的输出)之间的差异包含一个方向性信号,可用于引导预测向更准确、更低偏差的状态靠拢。该微分信号定义为 x^t−1−xθ0(x^t,t),其修正项被集成到去噪步骤中,即 x^t−1=x^t−1+λt(x^t−1−xθ0(x^t,t)),其中 λt 是一个标量引导因子。该修正在初始去噪步骤之后应用,旨在不增加计算成本的情况下增强样本质量。
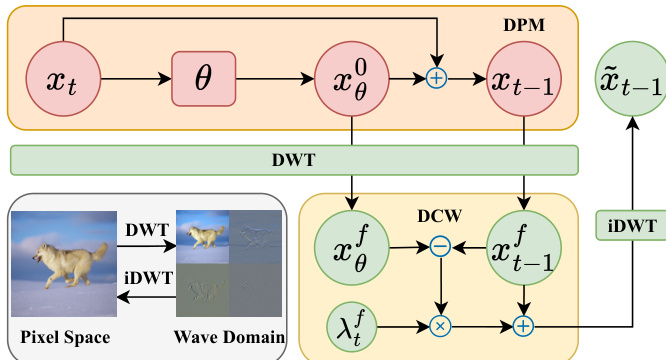
为了进一步改进修正效果,作者引入了小波域微分修正 (DCW) 框架,如上图所示。该方法使用离散小波变换 (DWT) 将预测样本 x^t−1 和重建样本 xθ0(x^t,t) 分解为四个频率子带 (LL, LH, HL, HH)。随后,微分修正被分别应用于每个子带,修正项为 λtf(x^t−1f−xθ0(x^t,t)f),其中 f 代表频率分量。这实现了针对性修正,因为捕捉全局结构的低频 (LL) 分量在过程早期被优先处理,而包含精细细节的高频分量在后期被强调。修正系数 λtf 根据去噪进度进行动态调整,通常使用反向过程方差 σt 作为引导。这种小波域修正有助于减少微分信号中存在的噪声干扰,从而实现对生成样本更有效且更集中的细化。
实验
实验通过分析不匹配的信噪比和 timesteps 如何影响网络预测来研究 SNR-t 偏差,特别发现反向去噪样本往往表现出比预期更低的 SNR。为了解决这个问题,在各种扩散框架和数据集上评估了所提出的 DCW 方法,以验证其纠正这些错误的能力。结果表明,DCW 在计算开销微乎其微的情况下,始终能提高生成质量和美学吸引力,即使集成到现有的偏差修正模型中也是如此。
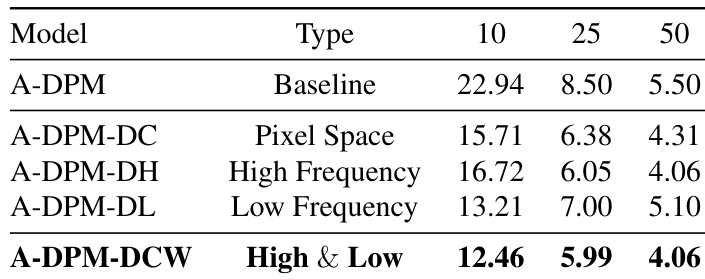
实验评估了在不同域应用微分修正对生成质量的影响。结果显示,结合高频和低频小波分量的修正效果最好,优于像素空间修正和单一频率修正。结合高低频的修正实现了最低的 FID 分数。单独的高频修正表现优于低频修正。像素空间修正的表现介于单一频率和结合方法之间。
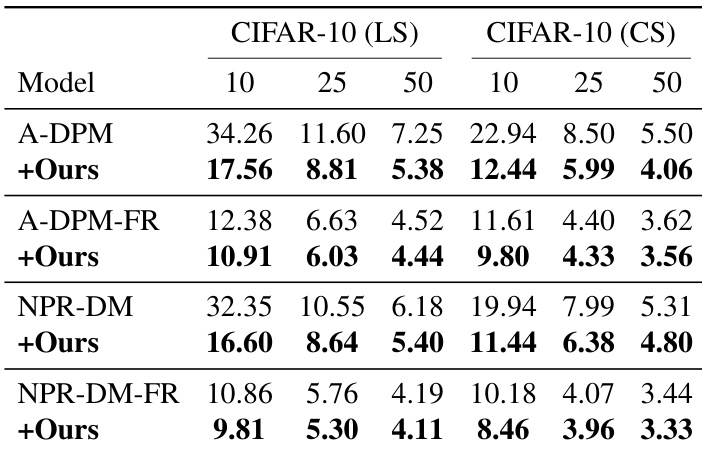
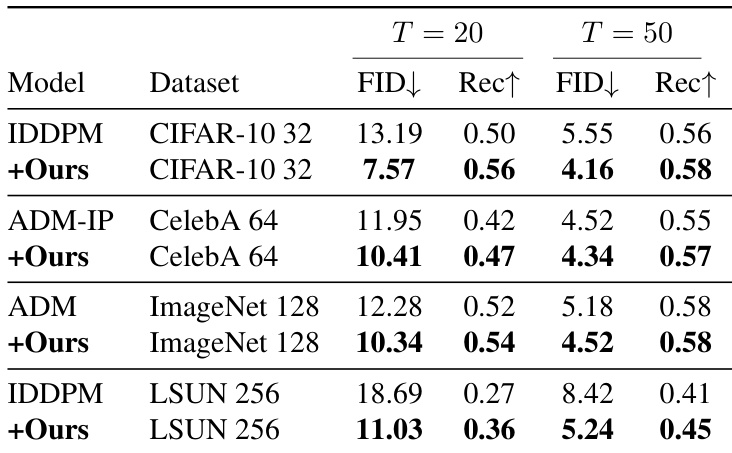
该表展示了几个扩散模型在不同采样步数下于 CIFAR-10 数据集上的 FID 分数。所提方法的集成在所有模型和数据集上一致降低了 FID 分数,表明生成质量得到了提高。结果证明了该方法在增强模型性能方面的有效性,无论基准模型或采样步数如何。所提方法降低了所有模型和数据集的 FID 分数,提升了生成质量。这种改进在不同的采样步数下是一致的,表明了其鲁棒性。该方法在低步数和高步数采样场景下均增强了性能。
该表比较了扩散模型中前向样本和反向样本的信噪比 (SNR)。结果显示,由于去噪样本的实际 SNR 与每个 timestep 的预期 SNR 之间存在不匹配,导致去噪过程中的预测误差,反向样本的 SNR 低于前向样本。在相同 timestep 下,反向样本表现出比前向样本更低的 SNR。反向样本的 SNR 受网络在处理较低 SNR 输入时倾向于高估预测的影响。前向和反向样本之间的 SNR 差异导致了去噪轨迹中的误差。
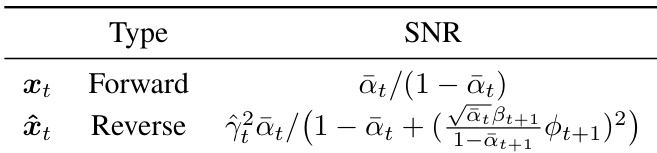
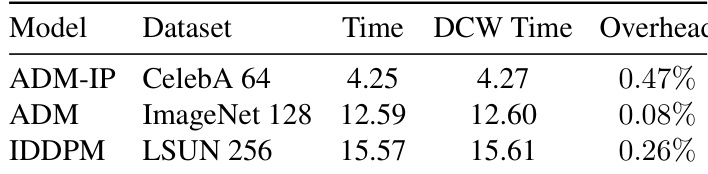
实验评估了 DCW 方法在不同模型和数据集上的计算开销。结果显示,DCW 引入的额外时间成本极低,在所有测试配置中的开销百分比始终保持在较低水平。DCW 为基准模型增加了微乎其微的计算开销。在不同数据集和模型中,开销始终保持在较低水平。额外的时间成本极小,不会显著影响生成速度。
作者在多个扩散模型和数据集上评估了他们的方法,证明了生成质量的一致提升。结果显示,所提方法在各种模型和采样步数下均降低了 FID 分数并提高了 Recall,表明保真度和多样性的提升。该方法在不同模型和数据集上一致降低了 FID 分数并提高了 Recall。该方法增强了经典扩散模型和经过偏差修正的扩散模型的生成质量。在不同的采样步数和模型架构中均观察到了改进。
这些实验评估了微分修正跨不同领域、采样步数和扩散架构的有效性,以增强生成质量。结果表明,同时对高频和低频小波分量应用修正可以获得卓越的性能,并且该方法在不同数据集上一致地提高了保真度和多样性。此外,分析证实了所提方法在解决去噪过程中 SNR 差异的同时,引入了微乎其微的计算开销。