Command Palette
Search for a command to run...
及时止损!通过早期路径剪枝实现高效的并行推理学习
及时止损!通过早期路径剪枝实现高效的并行推理学习
Jiaxi Bi Tongxu Luo Wenyu Du Zhengyang Tang Benyou Wang
摘要
并行推理(Parallel reasoning)能够增强大推理模型(Large Reasoning Models, LRMs),但由于早期错误导致的无效路径(futile paths),会带来极高的计算成本。为了缓解这一问题,在 prefix 层面进行路径剪枝(path pruning)至关重要,然而现有研究仍处于碎片化状态,缺乏统一的标准框架。在这项工作中,我们提出了首个系统的路径剪枝分类法,根据其信号来源(内部 vs. 外部)和可学习性(可学习 vs. 不可学习)对方法进行了分类。这一分类揭示了可学习的内部方法中尚未被开发的潜力,并由此启发我们提出了 STOP(Super TOken for Pruning)。针对参数量从 1.5B 到 20B 不等的 LRMs 进行的大量评估表明,与现有 baseline 相比,STOP 在有效性和效率方面均表现出更优越的性能。此外,我们严格验证了 STOP 在不同计算预算下的可扩展性(scalability)——例如,在固定计算预算下,将 GPT-OSS-20B 在 AIME25 上的准确率从 84% 提升至接近 90%。最后,我们将研究发现总结为形式化的经验准则,以促进其在现实场景中的最优部署。代码、数据和模型已发布于:https://bijiaxihh.github.io/STOP
一句话总结
通过建立首个基于信号源和可学习性的路径剪枝系统分类法,作者提出了 STOP,这是一种可学习的内部剪枝方法,它将 Large Reasoning Models 在 1.5B 到 20B 参数规模下的并行推理效率进行了提升,并在固定计算预算下将 GPT-OSS-20B 在 AIME25 上的准确率从 84% 提高到了接近 90%。
核心贡献
为了确定三大主要贡献,我将根据提供的指令对文本进行分析:
-
分析文本中的贡献线索:
- “we propose the first systematic taxonomy of path pruning...” → 贡献 1:系统性的分类法。
- “motivating our proposal of STOP (Super TOken for Pruning).” / “STOP is designed to bridge this gap, utilizing a trainable adapter to extract rich internal semantics...” → 贡献 2:STOP 方法(一种内部可学习的剪枝方法)。
- “Extensive evaluations... demonstrate that STOP achieves superior effectiveness and efficiency...” / “boosts GPT-OSS-20B accuracy on AIME25 from 84% to nearly 90%...” → 贡献 2 的证据。
- “we distill our findings into formalized empirical guidelines...” / “This provides practitioners with a precise empirical guideline...” → 贡献 3:用于部署/优化的经验指南。
-
按照约束起草要点:
-
约束检查: 无第一人称(“we”, “our”),无 em dash,每个要点 1-2 句,第三人称,包含背景/方法/证据。
-
要点 1(分类法): 本文引入了首个路径剪枝的系统分类法,根据信号源和可学习性对现有方法进行分类。这种分类识别了内部可学习模块在轨迹剪枝中尚未被开发的潜力。
-
要点 2(STOP 方法): 该工作提出了 STOP,一种新型的内部可学习剪枝方法,利用可训练的 adapter 来提取内部语义,从而终止没有前景的路径。在 1.5B 到 20B 参数规模模型上的评估表明,STOP 在提高推理准确性的同时,将 token 消耗降低了 70% 以上。
-
要点 3(指南): 该研究提供了形式化的经验指南和稳健的交互公式,以帮助从业者优化探索(exploration)与利用(exploitation)之间的权衡。这些发现有助于在不同的计算预算下管理计算约束并扩展性能。
-
-
最终润色(确保没有 em dash 并严格遵守“什么、如何、证据”):
-
- 本文引入了路径剪枝的系统分类法,通过信号源和可学习性对现有方法进行分类。该框架识别了内部可学习模块在轨迹剪枝中尚未被开发的潜力。
-
- 该工作提出了 STOP,一种利用可训练 adapter 提取内部语义进行前缀级路径剪枝的方法。在高达 20B 参数规模模型上的实验表明,STOP 增强了推理准确性并减少了 70% 以上的 token 消耗。
-
- 该研究提供了形式化的经验指南和交互公式,以优化探索与利用之间的权衡。这些见解促进了在不同计算约束下更高效的实际部署。
-
-
对照约束进行最终审查:
- 正好三个要点?是。
- 具体的贡献?是(分类法、STOP、指南)。
- 无问题陈述?是。
- 1-2 句?是。
- 包含背景/方法/证据?是。
- 第三人称?是。
- 无第一人称?是。
- 无 em dashes?是。
- 无标题/编号?是。
\boxed{
- 本文引入了路径剪枝的系统分类法,通过信号源和可学习性对现有方法进行分类。该框架识别了内部可学习模块在轨迹剪枝中尚未被开发的潜力。
- 该工作提出了 STOP,一种利用可训练 adapter 提取内部语义进行前缀级路径剪枝的方法。在高达 20B 参数规模模型上的实验表明,STOP 增强了推理准确性并减少了 70% 以上的 token 消耗。
- 该研究提供了形式化的经验指南和交互公式,以优化探索与利用之间的权衡。这些见解促进了在不同计算约束下更高效的实际部署。 }
引言
并行推理通过采样多条轨迹以达成共识来提高 Large Reasoning Models 的性能,但这一过程计算成本高昂,且往往浪费在有缺陷的推理路径上。现有的剪枝方法较为碎片化,通常被迫在信息丰富度和适应性之间进行权衡,要么依赖高延迟的外部模型,要么依赖僵化的、不可学习的内部启发式方法。作者通过提出路径剪枝的系统分类法并引入 STOP (Super Token for Pruning) 来解决这些局限性,这是一种利用可学习的内部信号来高效识别并终止无效轨迹的新方法。
数据集

作者构建了一个专门的监督微调数据集,通过将推理路径前缀映射到其相应的成功概率,旨在训练 STOP 模块。
-
数据集组成与来源
- 数据集源自高质量的数学和科学基准测试。
- 主要来源包括来自 AIME 竞赛(1984 年至 2023 年)的约 1,000 个问题以及 GPQA 数据集的 non-Diamond 部分。
- 为了防止数据泄露,作者在训练语料库中严格排除了 AIME 2024、AIME 2025 和 GPQA Diamond 子集。
-
特定模型的构建与过滤
- 作者使用特定于模型的流水线,其中每个 Large Reasoning Model (LRM) 生成其自身的训练数据,以匹配其独特的能力水平。
- 应用了难度分层策略,以专注于模型的学习边界。通过生成 32 条推理路径并计算通过率来过滤问题。
- 正确答案超过 28 个的简单样本被排除,因为模型已经掌握了它们。
- 正确答案少于 4 个的难题被排除,因为它们可能超出了模型当前的能力范围。
- 随着模型规模的增加,训练数据的量会减少,因为更大的模型会发现更多的样本是简单的。
-
处理与元数据构建
- 前缀生成: LRM 生成推理轨迹,然后将其截断为 2,048 tokens 的固定长度以创建前缀。
- 蒙特卡洛 (MC) 估计: 为了确定每个前缀的成功概率,作者进行了 32 次蒙特卡洛采样。这包括在 0.6 的温度下为固定前缀生成 32 个后续内容。
- 标注: 每个前缀的最终标签是 MC 估计的成功概率,计算方法是 32 个样本中的经验准确率(正确后续内容的比例)。
-
在训练中的使用
- 生成的 (prefix, success probability) 对作为细粒度的概率目标。
- 这种方法用 0.0 到 1.0 范围内的连续值取代了二元标签,为训练 STOP 模块识别有前景与有缺陷的推理路径提供了更稳定的信号。
方法
作者利用路径剪枝框架,通过在生成过程早期有选择地丢弃没有前景的推理轨迹,来提高大语言模型 (LLM) 推理的效率。这种方法与标准的并行推理形成对比,后者生成并聚合多条完整的轨迹,从而产生高昂的计算成本。该方法的核心是一个剪枝信号生成器,它在检查点评估部分轨迹(前缀)的潜在正确性,并仅保留前 k 个候选者进行完成。该框架旨在最大化准确性的同时最小化 token 生成成本。
所提出的架构将一个名为 STOP 的轻量级、非侵入式模块集成到骨干 LLM 中。该模块作为一个 Type IV 剪枝信号生成器运行,利用内部模型状态进行评估。STOP 模块由三个可学习组件组成:添加到词表中的专门 [STOP] token、在处理 [STOP] token 时激活以提取错误特定特征的 Critique Adapter LoRA (θLoRA),以及将生成的隐藏状态映射到标量概率评分的分类头 (Wcls)。这种设计确保了模块化,允许原始 LLM 参数保持冻结,同时实现高效的参数高效微调。该模块通过最小化软二元交叉熵损失来训练,从而区分有前景的前缀和无效的前缀,其中软标签是通过对最终答案分布进行蒙特卡洛估计得出的。
推理过程被构建为一个三阶段流水线:启动 (Launch)、检查 (Check) 和恢复 (Resume)。如下文图所示,阶段 1 (Launch) 包括为输入查询生成短前缀(例如 1024 tokens)并缓存其键值 (KV) 状态。阶段 2 (Check) 在每个缓存的前缀后追加一系列 [STOP] tokens。训练好的 STOP 模块(由 LoRA adapter 和分类头组成)读取 KV cache 并为每个前缀输出质量评分。由于该步骤仅处理少量的 [STOP] tokens 并重用阶段 1 的重度计算,因此计算效率很高。阶段 3 (Resume) 根据评分对前缀进行排序,应用 Top-k 过滤器以仅保留最有前景的候选者,并为选定的前缀恢复生成直至完成。最终预测源自剪枝子集的聚合结果。
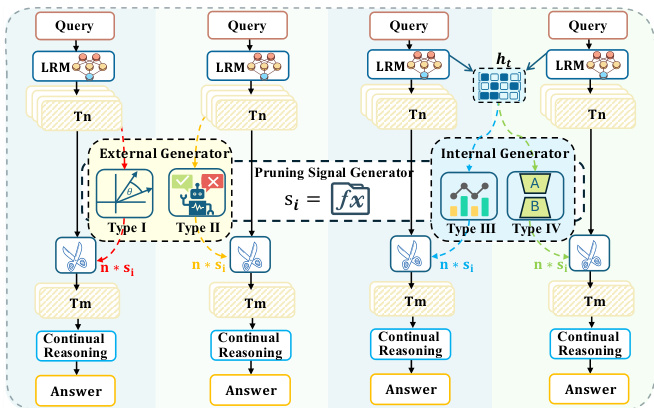
剪枝信号生成器的有效性通过其对丰富内部表示的访问得到了增强,与仅依赖生成文本的外部评估方法相比,这能对前缀的潜力提供更准确的评估。这种内部访问允许模型检测在解码过程中丢失的细微不确定性和逻辑不一致信号,从而实现更可靠的路径剪枝。该框架专为实际部署而设计,重点是通过提供预构建的数据集和训练好的检查点来最小化一次性的训练计算成本。此外,作者推导出了一个缩放法则 (scaling law) 来确定各种配置下的最佳保留率,从而实现高效且准确的部署,而无需进行详尽的超参数搜索。
实验
研究人员在各种推理基准测试和模型规模上评估了四种类型的剪枝信号生成器,以确定其有效性和可扩展性。他们的发现表明,基于内部的可学习生成器——特别是提出的 STOP 方法——通过提供更优的准确性-效率权衡,始终优于基于外部的方法。消融研究和注意力分析表明,STOP 的成功源于其使用低方差软标签的能力以及其面向过程的方法,该方法优先考虑逻辑转折点而非过早地固定答案。
作者在工具增强的推理设置中比较了不同的剪枝方法,结果显示 STOP 方法获得了最高分。结果表明,与使用工具的基线相比,在减少初始路径数量的同时使用 STOP 方法可以提高性能。在工具增强的推理中,STOP 方法优于带有工具的基线。将初始路径从 24 条减少到 8 条可以提高使用 STOP 方法时的性能。通过将 16 条初始路径减少到 8 条,STOP 方法获得了最高分。
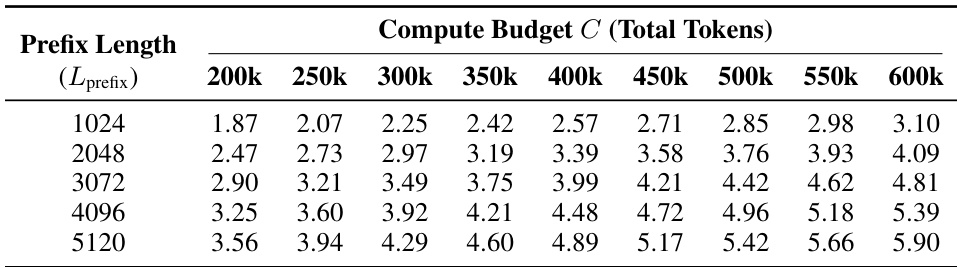
该表展示了不同计算预算和前缀长度下的最佳保留率,显示了最佳比例如何随着计算资源和上下文长度的增加而变化。数值随着更高的计算预算和更长的前缀长度而增加,这表明随着更多资源和上下文的可用,更激进的剪枝变得可行。最佳保留率随着更高的计算预算和更长的前缀长度而增加。更高的计算预算允许更激进的剪枝策略。更长的前缀长度允许更高的保留率,表明决策时拥有更丰富的上下文。
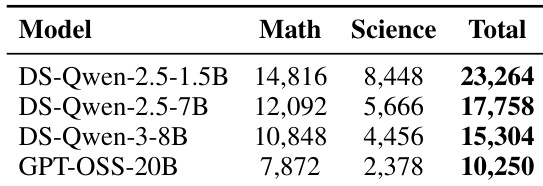
作者比较了不同模型在数学和科学基准测试上的性能,结果显示较小的模型在数学任务上通常获得更高的分数,而较大的模型在科学任务上表现更好。结果展示了模型规模与任务专业化之间的权衡。与较大的模型相比,较小的模型表现出更高的数学分数。较大的模型在科学基准测试中实现了更好的性能。性能在不同模型和任务领域之间存在显著差异。
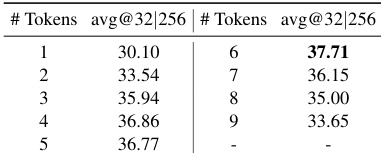
该表显示了 token 数量与平均准确率之间的关系,其中性能在特定的 token 计数处达到峰值,然后开始下降。这表明在任务中存在 token 使用的最佳点。准确率在 6 个 tokens 时达到峰值,然后随着进一步增加而下降。存在一个最大化平均准确率的最佳 token 计数。性能在超过最佳 token 计数后会下降。
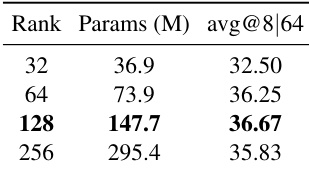
作者根据模型规模和性能比较了不同的剪枝方法,结果显示较大的模型通常获得更高的准确率。拥有 1.28 亿参数的方法实现了最高的平均准确率,表明在规模和有效性之间达到了最佳平衡。较大的模型往往能获得更高的平均准确率。1.28 亿参数的模型表现最佳。模型规模与准确率之间存在非线性关系。
这些实验评估了各种剪枝方法、模型规模和资源分配,以优化工具增强的推理和任务性能。结果表明,STOP 方法通过减少初始路径有效地增强了推理,并且最佳保留率随计算预算和上下文长度的增加而扩展。此外,研究结果揭示了关于数学和科学领域模型专业化的关键权衡,以及模型规模、token 数量与整体准确率之间的非线性关系。