Command Palette
Search for a command to run...
Qwen3.5-Omni 技术报告
Qwen3.5-Omni 技术报告
Qwen Team
摘要
在这项工作中,我们推出了 Qwen3.5-Omni,这是 Qwen-Omni 模型家族的最新进展。作为其前代版本的重大演进,Qwen3.5-Omni 的参数规模扩展至数千亿级,并支持 256k 的 context length。通过利用包含异构文本-视觉对以及超过 1 亿小时音视频内容的超大规模数据集,该模型展示了强大的全模态(omni-modality)能力。Qwen3.5-Omni-plus 在 215 项音频及音视频理解、推理与交互的子任务和 benchmark 中取得了 SOTA 结果,在关键音频任务上超越了 Gemini-3.1 Pro,并在综合音视频理解能力上与之持平。在架构方面,Qwen3.5-Omni 为 Thinker 和 Talker 均采用了混合注意力混合专家(Hybrid Attention Mixture-of-Experts, MoE)框架,从而实现了高效的长序列 inference。该模型支持复杂的交互,能够支持超过 10 小时的音频理解以及 400 秒的 720P 视频(帧率为 1 FPS)。为了解决流式语音合成中固有的不稳定性和不自然感(这通常是由文本与语音 tokenizer 之间的编码效率差异引起的),我们引入了 ARIA。ARIA 能够动态对齐文本与语音单元,在极小化延迟影响的前提下,显著增强了对话式语音的稳定性和韵律感。此外,Qwen3.5-Omni 拓展了语言边界,支持 10 种语言的多语言理解与语音生成,并具备类人的情感细微差别。最后,Qwen3.5-Omni 展示了卓越的音视频 grounding 能力,能够生成具有精确时间同步和自动化场景分割能力的剧本级结构化描述(script-level structured captions)。值得注意的是,我们观察到全模态模型中涌现出了一种新能力:能够直接根据音视频指令进行编程,我们将其称为“音视频氛围编程”(Audio-Visual Vibe Coding)。
一句话总结
Qwen 团队推出了 Qwen3.5-Omni,这是一个大规模全模态模型,利用 Hybrid Attention Mixture-of-Experts 框架来支持 256k 的 context 长度和高效的长序列推理,同时结合了 Adaptive Rate Interleave Alignment (ARIA) 技术,在 215 个音频和视听基准测试中实现了最先进的结果,并提供稳定、自然的对话式语音合成。
核心贡献
- 本论文介绍了 Qwen3.5-Omni,这是一个统一的端到端模型,其 Thinker 和 Talker 组件均采用 Hybrid Attention Mixture-of-Experts (MoE) 框架,以实现高效的长序列推理。该架构支持 256k 的 context 长度,允许模型处理超过 10 小时的音频和 400 秒的 720P 视频。
- 本研究提出了 ARIA (Adaptive Rate Interleave Alignment),这是一种在流式解码期间动态对齐文本和语音单元的技术,旨在提高对话式语音的稳定性和韵律。该方法解决了 tokenizer 之间的编码效率差异问题,从而以极低的延迟实现更自然的语音合成。
- 研究展示了先进的全模态能力,包括可控的视听字幕生成、通过轮次转换意图识别实现的实时交互,以及类似于视听代码生成的原生 agentic 行为。实验表明,Qwen3.5-Omni-Plus 在 215 个音频和视听基准测试中达到了最先进的结果,在多个关键音频任务中超越了 Gemini-3.1 Pro。
引言
由于人类交互本质上是全模态的,对于能够无缝集成视觉、听觉和语言信息以作为自主 Agent 的 AI 系统需求日益增长。虽然现有模型在单一模态方面取得了长足进步,但它们通常依赖于被动的“感知-响应”范式,并且在实时交互、可扩展的 agentic 行为以及流式语音合成固有的不稳定性方面面临挑战。作者通过引入 Qwen3.5-Omni 来应对这些挑战,这是一个统一了理解、推理、生成和行动的全模态模型。他们利用 Hybrid Attention Mixture-of-Experts (MoE) 架构和一种称为 Adaptive Rate Interleave Alignment (ARIA) 的新技术,以确保稳定、自然的语音合成和高效的长序列推理。除了在视听任务中达到最先进的性能外,该模型还展示了涌现的 agentic 能力,例如自主工具使用和 Audio-Visual Vibe Coding(即直接从多模态指令生成可执行代码)。
数据集
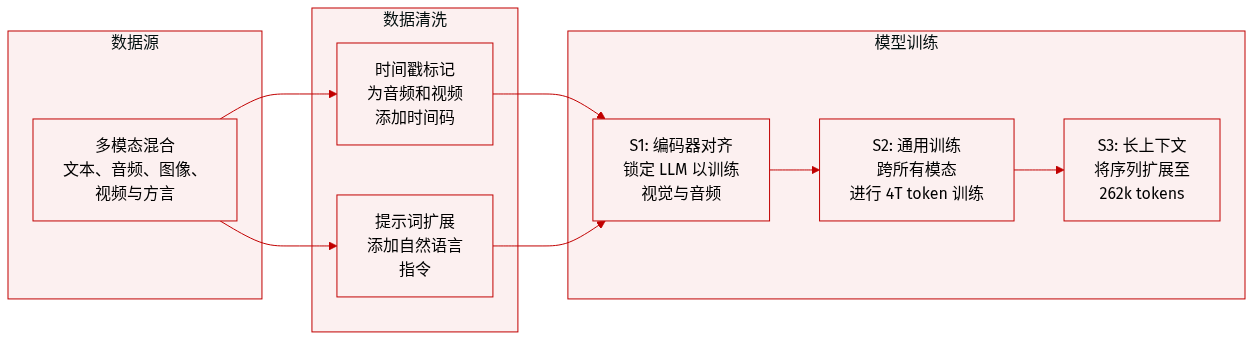
作者利用多样化的多模态数据集来训练 Qwen3.5-Omni,涵盖了多种语言、方言以及各种数据模态,包括文本、图文、视频文本、音文、视听以及视音文。
-
数据集组成与阶段: 预训练分为三个不同的阶段:
- Encoder Alignment 阶段 (S1): 作者专注于训练视觉和音频 encoder,同时保持 LLM 参数锁定。此阶段利用海量的音文和图文对来使 encoder 与 LLM 对齐。
- General 阶段 (S2): 模型在总计约 4 万亿 tokens 的大规模数据集上进行训练。模态分布为:0.92 万亿文本 tokens,1.99 万亿音频 tokens,0.95 万亿图像 tokens,0.14 万亿视频 tokens,以及 0.29 万亿视音频 tokens。此阶段使用的序列长度为 32,768。
- Long Context 阶段 (S3): 为了提高长序列理解能力,作者将最大序列长度增加到 262,144,并提高了长音频和长视频数据的比例。
-
数据处理与时间感知:
- 为了在不承担不同帧率统一采样高昂成本的情况下提高时间感知能力,作者实施了时间戳策略。
- 对于视频或视音频输入,每个时间 patch 前都会添加一个以秒为单位的格式化文本字符串形式的时间戳。
- 对于音频序列,时间戳被随机间隔地插入,以确保不同模态之间更好的对齐。
- 作者还结合了广泛的自然语言 prompt,以提高泛化能力和指令遵循能力。
方法
Qwen3.5-Omni 系统采用了 Thinker-Talker 架构,专为超低延迟的端到端多模态交互而设计。如框架图所示,模型结构分为两个主要组件:Thinker 和 Talker。Thinker 负责多模态理解和文本生成,而 Talker 则根据 Thinker 产生的高层表示来生成流式语音 tokens。这种分离实现了具有极低延迟的高效实时语音合成。
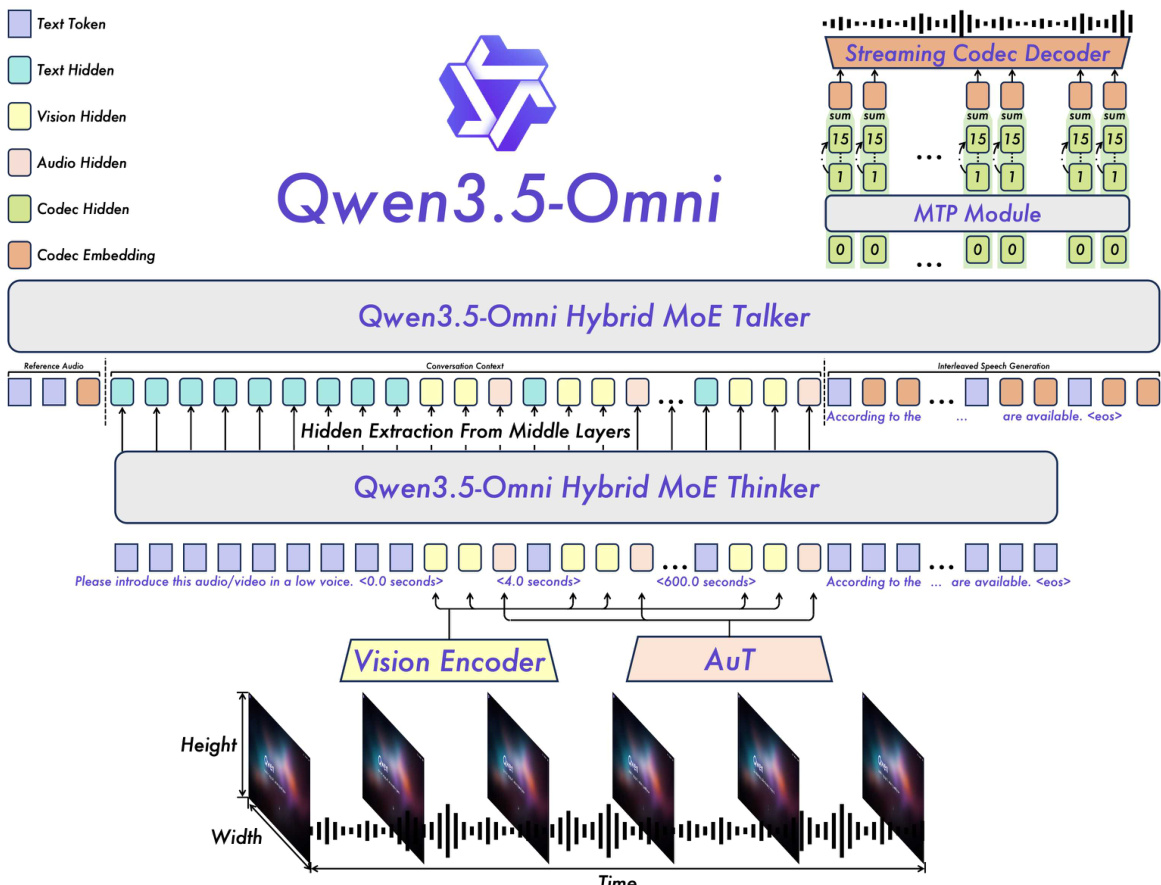
模型的整体骨干采用了 Hybrid Mixture-of-Experts (MoE) 设计,通过在不同模态和任务之间动态分配计算资源来增强可扩展性和效率。Thinker 通过统一的表示框架处理包括文本、音频和视频在内的多模态输入。文本输入使用 Qwen3.5 tokenizer 进行 tokenization,该 tokenizer 采用字节级字节对编码(byte-level byte-pair encoding),词表大小为 250k。音频信号通过 AuT encoder 进行处理,它将原始波形转换为 16 kHz 采样率下的 128 通道 mel-spectrograms。视频输入由视觉 encoder 处理,该 encoder 同时处理图像和视频,并以动态速率采样帧,以保持与音频流的对齐。
为了保持时间相干性,特别是在长音频视频上下文中,模型在输入序列中加入了显式的时间戳。对于音频,每 160 ms 分配一个时间 ID,而视频帧则分配单调递增的时间 ID,并调整为一致的 160 ms 分辨率。这种方法结合用于时间感知的 TM-RoPE,使模型能够有效地建模长程时间依赖。位置编码在模态间是连续的,每个后续模态从前一个模态的最大位置 ID 加 1 开始,确保了不同输入的无缝集成。
Talker 组件负责生成流式语音。它直接作用于 Qwen3.5-Omni-Audio-Tokenizer 产生的 RVQ tokens,并使用多 token 预测 (MTP) 模块来建模残差 codebooks,从而实现对声学细节的精细控制。MTP 模块为每一帧输出必要的 codebooks,随后由 Code2Wav renderer 进行处理,以增量式地合成相应的波形。这种设计允许逐帧流式生成,实现了超低延迟的语音合成。
为了支持实时交互,Qwen3.5-Omni 在 Thinker 中采用了分块流式输入处理,并采用了流式 Talker 设计。Talker 以 Thinker 提供的丰富上下文信息为条件,包括历史文本 tokens、多模态表示和当前轮次的文本,从而实现对韵律、响度和情感等声学属性的动态调节。引入 ARIA (Adaptive Rate Interleave Alignment) 技术是在交错之前动态对齐文本和语音单元,从而缓解由文本和语音之间 tokenization 速率不匹配引起的问题。
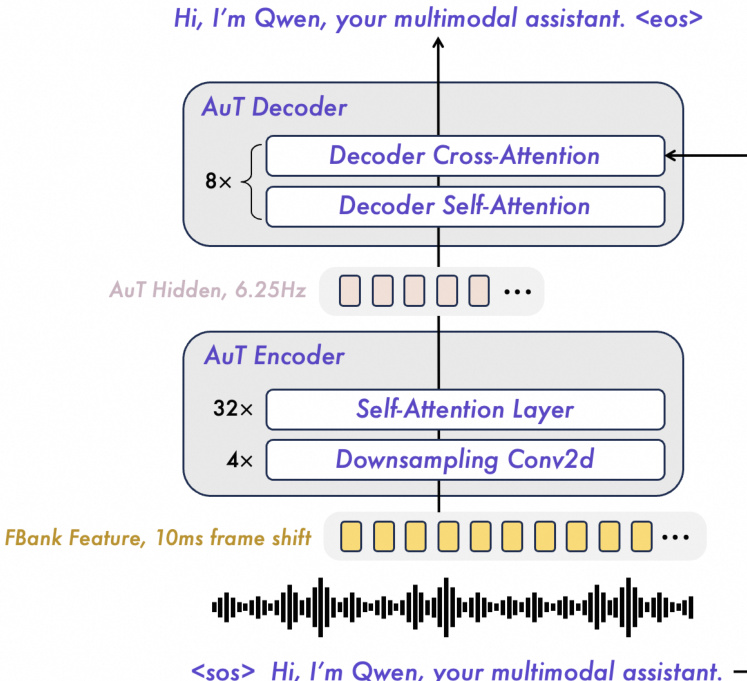
如图所示,AuT encoder 是一个基于 transformer 的音频 encoder,在 4000 万小时的音文对上从头开始训练。它使用四个 Conv2D 块对滤波器组特征进行下采样,并通过自注意力层进行处理,以获得 6.25 Hz 速率的音频 tokens。该 encoder 使用动态注意力窗口大小机制进行训练,以平衡实时预填充缓存和离线音频理解任务的性能。这种设计使模型能够处理扩展输入,支持高达 256k tokens、10 小时音频或 400 秒 1 FPS 的 720P 视频。
Thinker 的训练过程涉及三阶段策略。第一阶段,专家蒸馏 (Specialist Distillation),使用领域专业的教师模型为全模态能力奠定坚实基础。第二阶段,策略内蒸馏 (On-Policy Distillation),使模型的音频条件输出与其文本条件行为对齐,以缩小对音频查询和文本查询响应之间的质量差距。第三阶段,交互对齐强化学习 (Interaction-Aligned Reinforcement Learning),通过多轮交互轨迹和基于用户体验的奖励信号,解决语言语码转换和人格不一致等问题,从而优化模型以进行现实世界的交互使用。
Talker 通过四阶段流水线进行训练。通用阶段 (General Stage) 在超过 2000 万小时具有多模态上下文的多语言语音数据上对模型进行预训练。长上下文阶段 (Long-Context Stage) 进行数据质量分层和持续预训练,以提高自然度和处理长输入的能力。强化学习阶段 (Reinforcement Learning Stage) 使用直接偏好优化 (DPO) 和基于规则的奖励,使模型行为与人类偏好对齐。说话人微调阶段 (Speaker Fine-tuning Stage) 实现声音克隆,并增强语音输出的自然度、表现力和可控性。
实验
评估涵盖了 Qwen3.5-Omni 模型在多模态理解、语音生成和流式效率方面的表现。结果表明,模型在文本性能上达到了与纯文本基准模型相当的水平,同时在音频理解、视频理解和视听任务方面显著优于竞争对手。此外,该模型在零样本、多语言和跨语言语音生成方面表现出最先进的能力,保持了极高的内容保真度和说话人相似度。架构优化还确保了稳定的延迟和高吞吐量,使系统非常适合低延迟、高并发的流式交互。
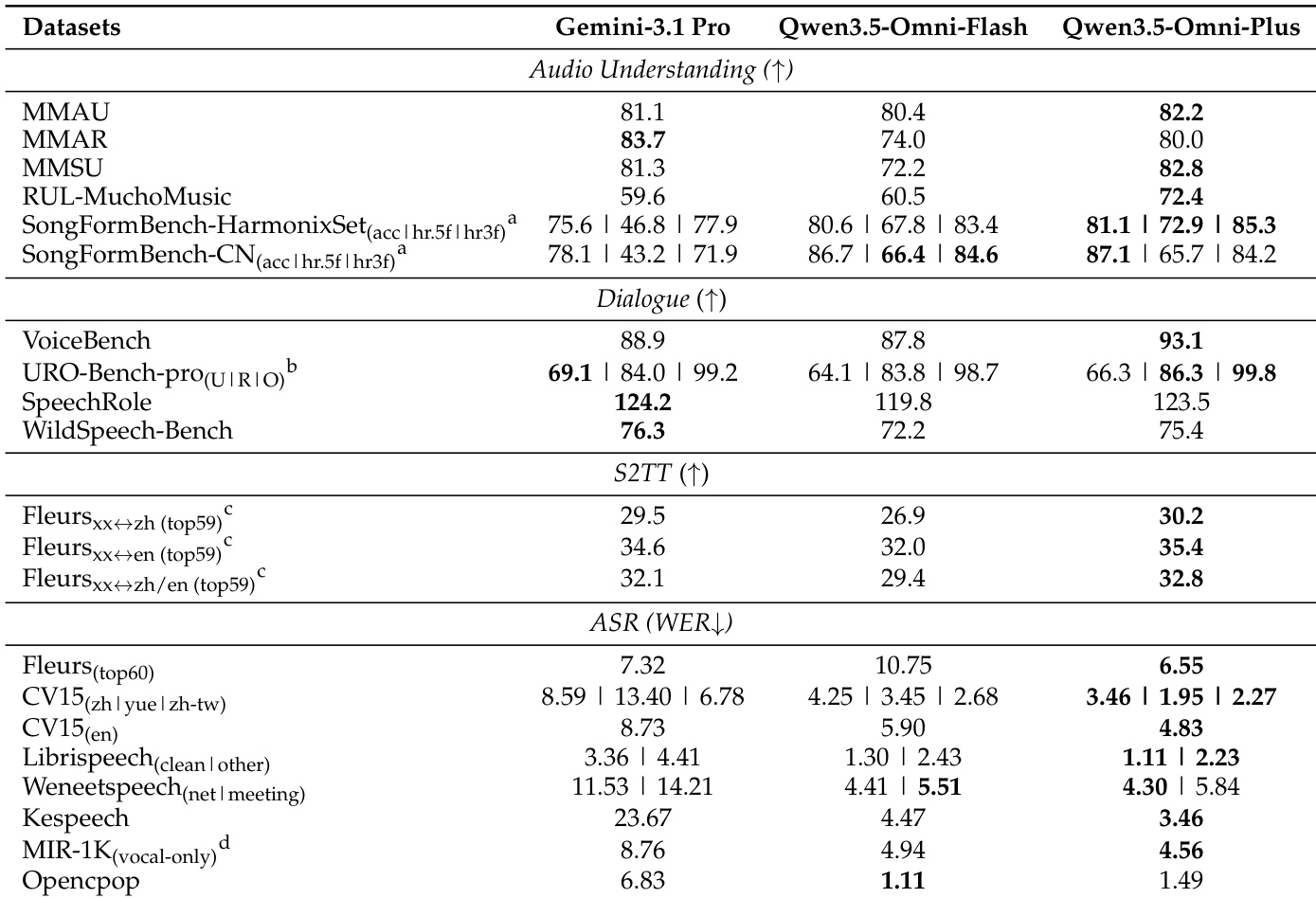
作者在音转文任务上将 Qwen3.5-Omni-Flash 和 Qwen3.5-Omni-Plus 与 Gemini-3.1 Pro 进行了比较,评估了音频理解、对话、翻译和语音识别。结果显示,Qwen3.5-Omni 在大多数基准测试中实现了优于或相当的性能,特别是在音频理解和语音识别方面,同时在语音转文本翻译方面优于 Gemini-3.1 Pro。Qwen3.5-Omni 在多个音频理解和语音识别基准测试中优于 Gemini-3.1 Pro。与 Gemini-3.1 Pro 相比,Qwen3.5-Omni 在端到端语音对话任务中取得了具有竞争力的结果。Qwen3.5-Omni 在各种语言对的语音转文本翻译中展示了强大的性能。
作者在 SEED 基准测试上评估了零样本语音生成,将 Qwen3.5-Omni-Plus 与几种最先进的模型进行了比较。结果显示,Qwen3.5-Omni-Plus 实现了强大的内容一致性,其性能与领先系统相当,并在优化后在自然度方面有显著提升。与最先进的模型相比,Qwen3.5-Omni-Plus 在 SEED 基准测试上实现了具有竞争力的内容一致性。模型在 RLHF 优化后展示了改进的生成稳定性和自然度。Qwen3.5-Omni-Plus 在零样本语音生成中表现出强大的性能,在多个评估指标上均具有较低的错误率。
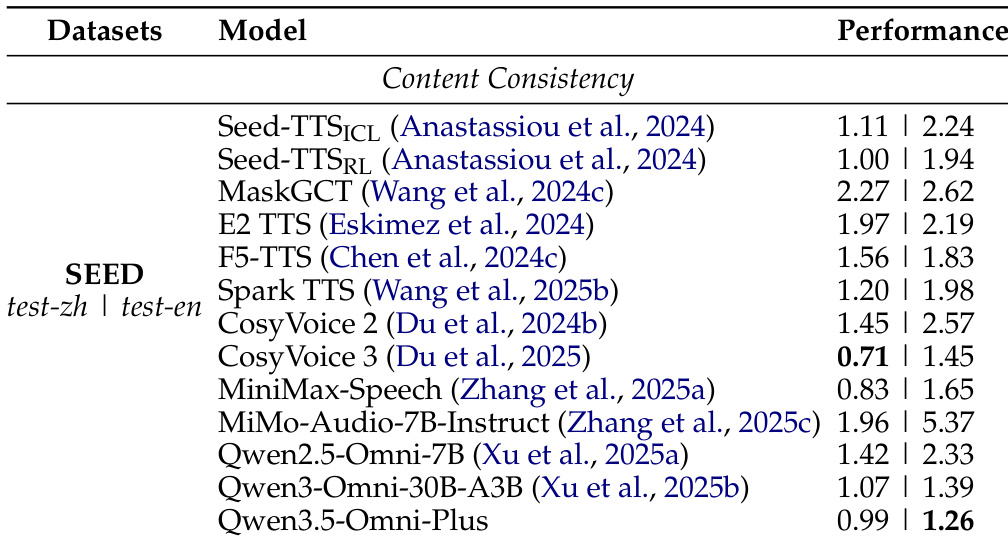
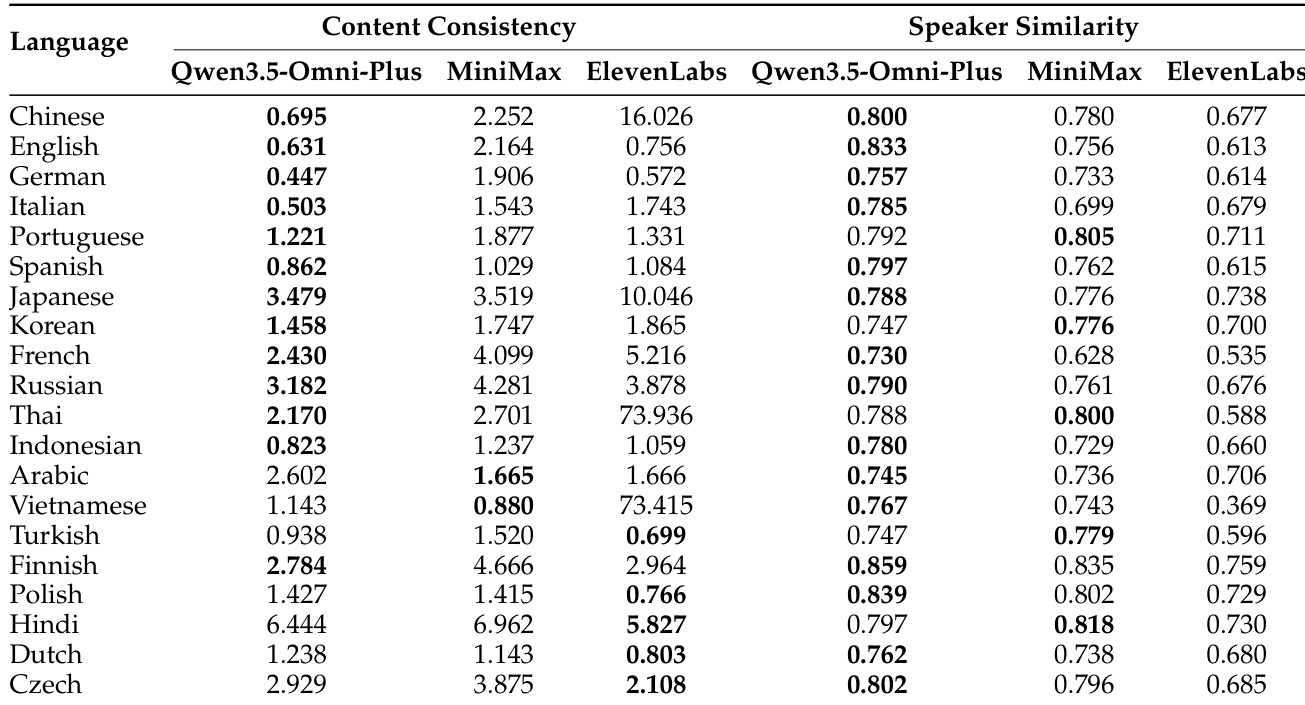
该表比较了 Qwen3.5-Omni-Plus 与其他系统在多种语言下的多语言语音生成性能,衡量了内容一致性和说话人相似度。结果显示,Qwen3.5-Omni-Plus 在大多数语言中实现了具有竞争力的内容一致性和卓越的说话人相似度,特别是在日语和韩语方面表现出色。Qwen3.5-Omni-Plus 在 29 种语言中的 22 种中实现了最低的词错误率,表明了强大的内容一致性。Qwen3.5-Omni-Plus 在说话人相似度方面优于其他系统,尤其是在日语和韩语中。该模型在多种语言中保持了高性能,展示了强大的多语言泛化能力。
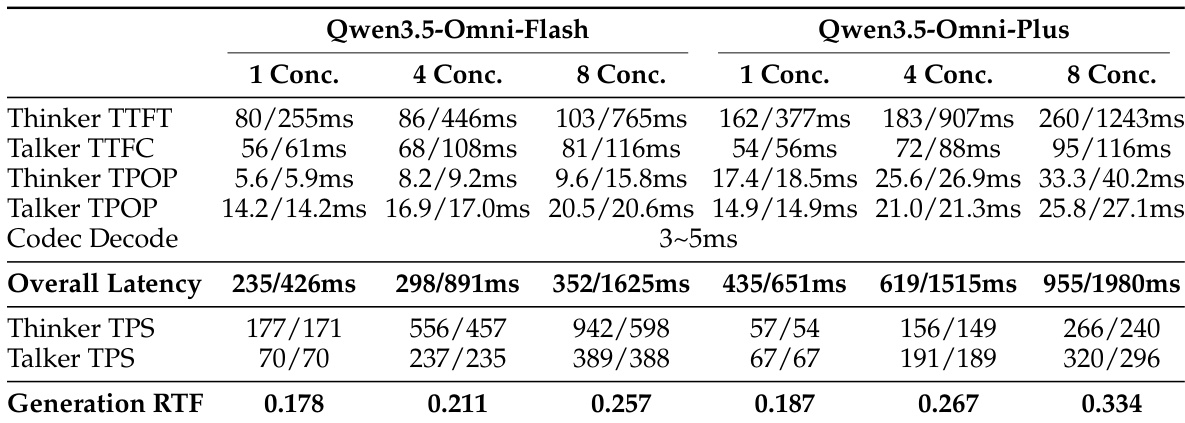
该表展示了 Qwen3.5-Omni-Flash 和 Qwen3.5-Omni-Plus 在不同并发水平下的延迟和吞吐量指标,显示出随着并发增加,性能保持稳定。结果表明,两种模型都保持了低延迟和一致的生成吞吐量,较大的变体展示了更高的绝对值,但具有相似的扩展行为。对于两种模型变体,延迟随着并发的增加保持稳定。两种模型在不同的并发水平下都显示出一致的生成吞吐量。Qwen3.5-Omni-Plus 的绝对延迟和吞吐量值高于 Qwen3.5-Omni-Flash。
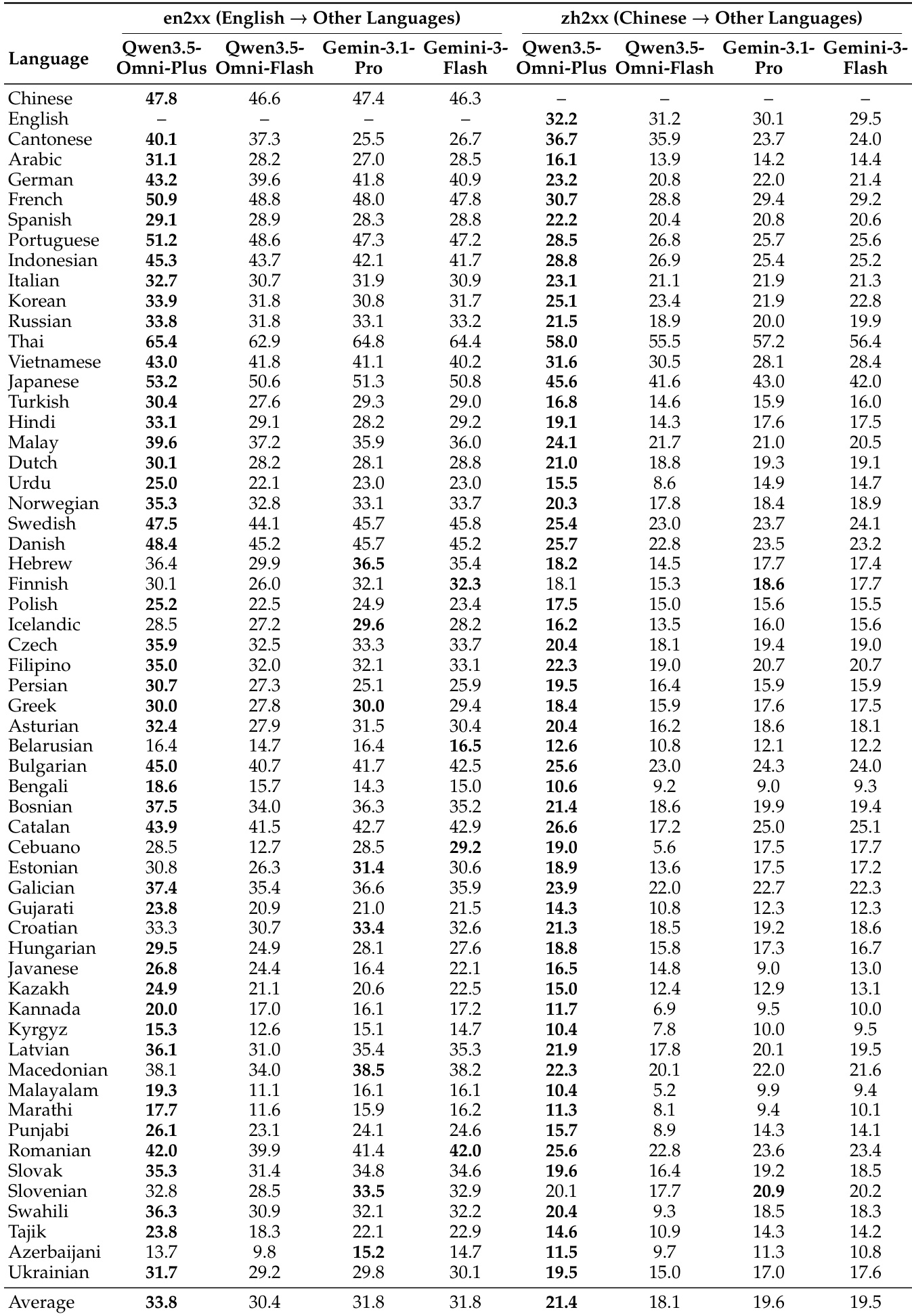
该表比较了 Qwen3.5-Omni 各变体与 Gemini-3.1-Pro 在多种语言下的多语言语音生成性能。结果显示,Qwen3.5-Omni-Plus 和 Qwen3.5-Omni-Flash 在大多数语言中实现了具有竞争力或优越的性能,特别是在内容一致性和说话人相似度指标方面。在从英语和中文到其他语言的翻译任务中,Qwen3.5-Omni 变体在大多数语言上都优于 Gemini-3.1-Pro。Qwen3.5-Omni-Plus 在几种语言中获得了最高分,表明了强大的多语言语音生成能力。Qwen3.5-Omni-Flash 展示了具有竞争力的性能,特别是在其结果匹配或超过 Gemini-3.1-Pro 的语言中。
作者通过与 Gemini-3.1 Pro 等最先进模型的对比基准测试来评估 Qwen3.5-Omni 系列,重点关注音转文理解、零样本语音生成和多语言能力。结果表明,Qwen 模型在语音识别、翻译和说话人相似度方面实现了优越或具有竞争力的性能,特别是在多语言泛化和内容一致性方面表现出色。此外,模型在不同的并发水平下保持了稳定的延迟和吞吐量,证实了其在实际部署中的效率。