Command Palette
Search for a command to run...
AgentSPEX:一种 agent 规范与执行语言
AgentSPEX:一种 agent 规范与执行语言
Pengcheng Wang Jerry Huang Jiarui Yao Rui Pan Peizhi Niu Yaowenqi Liu Ruida Wang Renhao Lu Yuwei Guo Tong Zhang
摘要
语言模型 agent 系统通常依赖于反应式提示(reactive prompting),即通过单一指令引导模型完成一系列开放式的推理和工具使用步骤。这种方式使得控制流和中间状态处于隐式状态,导致 agent 的行为可能难以控制。虽然 LangGraph、DSPy 和 CrewAI 等编排框架通过显式的流程定义引入了更强的结构性,但它们将工作流逻辑与 Python 紧密耦合,使得 agent 难以维护和修改。在本文中,我们推出了 AgentSPEX,这是一种用于通过显式控制流和模块化结构来规范 LLM-agent 工作流的 Agent 规范与执行语言(Agent SPecification and EXecution Language),并配备了一个可定制的 agent harness。AgentSPEX 支持类型化步骤(typed steps)、分支与循环、并行执行、可重用的子模块以及显式的状态管理;这些工作流在 agent harness 中运行,该 harness 提供工具访问、沙箱虚拟环境,并支持检查点(checkpointing)、验证和日志记录。此外,我们还提供了一个带有同步图表与工作流视图的可视化编辑器,用于工作流的编写与检查。我们内置了用于深度研究和科学研究的开箱即用型 agents,并在 7 个基准测试上对 AgentSPEX 进行了评估。最后,通过用户研究我们表明,相比于现有的流行 agent 框架,AgentSPEX 提供了一种更具可解释性且更易于使用的工作流编写范式。
一句话总结
为了解决响应式提示(reactive prompting)和紧耦合 Python 编排框架的局限性,本文介绍了 AgentSPEX,这是一种 Agent 规范与执行语言。它通过显式控制流、模块化结构以及一个具有类型化步骤、状态管理和沙盒环境的可定制 harness,实现了可控且可维护的 LLM-agent 工作流。本文通过使用用于深度和科学研究的现成 agents,在七个基准测试中对该框架进行了评估。
核心贡献
- 本文介绍了 AgentSPEX,这是一种 Agent 规范与执行语言,使用声明式 YAML 文件来定义具有显式控制流、分支、循环和模块化子模块的 LLM-agent 工作流。
- 提供了一个可定制的 agent harness 来执行这些工作流,提供沙盒虚拟环境、工具访问以及诸如状态检查点(state checkpointing)、轨迹日志(trajectory logging)和重放功能等高级能力。
- 该工作包括一个用于拖拽式工作流构建的双向可视化编辑器,并通过用于科学、写作和软件工程领域的现成研究 agents 以及在七个基准测试中的评估,展示了该框架的实用性。
引言
现代语言模型 agent 系统通常依赖于响应式提示,即通过单个指令引导开放式的推理序列。虽然这种方法很简单,但它缺乏对中间状态的精确控制,并且在处理长程任务时可能会遇到困难。现有的编排框架试图提供结构,但通常将工作流逻辑与 Python 代码紧密耦合,这导致了陡峭的学习曲线,并使得 agent 难以维护或与非编程人员共享。本文采用了一种名为 AgentSPEX 的新方法,这是一种使用声明式 YAML 语法来定义工作流的 Agent 规范与执行语言。这一贡献提供了对分支、循环和状态管理的显式控制,同时提供了一个可定制的执行 harness 和一个可视化编辑器,使 agent 的编写更加便捷且具有可解释性。
数据集
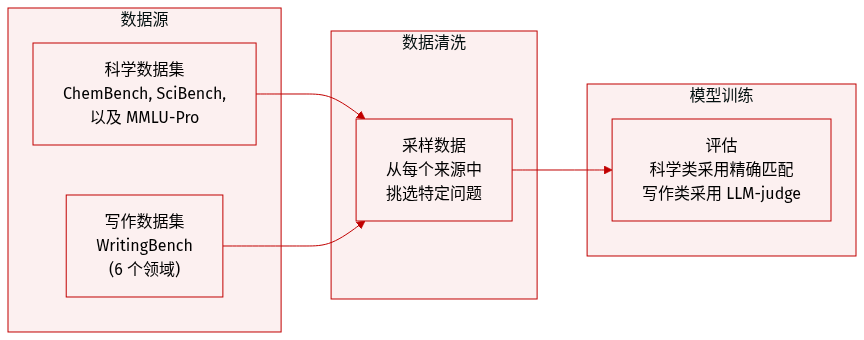
通过利用多个专门的数据集来评估科学推理和生成式写作能力:
- 科学数据集:
- ChemBench:通过从原始框架的 9 个领域中每个领域随机抽取 10 个问题,创建了一个包含 90 个问答对的子集。
- SciBench:使用了从四本特定教科书中获取的 213 个大学水平化学问题的集合:Atkins' Physical Chemistry(101 个问题)、Chemistry by McMurry & Fay(33 个问题)、Properties of Matter(47 个问题)以及 Quantum Chemistry(32 个问题)。
- MMLU-Pro Stemez:使用了 Physical Chemistry 子集,包含来自 Stemez 网站的 216 个问题。
- 生成式写作数据集:
- WritingBench:为了评估写作,通过从 6 个主要领域中每个领域随机抽取 20 个问题,构建了一个包含 120 个问题的子集。
- 评估与处理:
- 对于科学基准测试,采用与参考答案的精确匹配(exact match)评估。
- 对于写作基准测试,遵循 LLM-as-Judge 协议,由一个批评者模型根据 5 个特定实例的标准,使用 10 分制进行评分。
方法
AgentSPEX 的核心架构围绕声明式工作流规范语言和执行这些工作流的 agent harness 构建,后者在一个受控、可观察且持久的环境中运行。系统始于一个基于 YAML 的工作流定义,其中指定了 agent 的名称、目标、配置和一系列操作。该工作流使用 task 和 step 等原语定义结构化的执行计划,这些原语决定了 agent 如何与工具交互并维护对话历史。task 发起一个没有先前上下文的新交互,而 step 通过在多次交互中保留对话历史来实现多轮推理。这些操作由控制流结构支持,包括 if、while、for_each 和 call,从而实现了复杂的逻辑和模块化组合。call 结构允许工作流将其他工作流作为可重用的子模块进行调用,促进了模块化和代码重用。该框架通过上下文变量支持状态管理,这些变量使用 Mustache 风格的模板(如 {{variable}})在步骤之间传递,并可以使用 save_as 指令进行保存。这实现了中间结果在整个工作流中的无缝流动。

工作流定义旨在具备人类可读性和可编辑性,允许领域专家在无需编程专业知识的情况下编写和修改工作流。工作流是自包含的 YAML 文件,便于版本控制和协作。为了辅助工作流开发,AgentSPEX 提供了一个可视化编辑器,将工作流渲染为交互式流程图,其中每个节点对应一个操作。用户可以在图形界面中修改工作流,也可以直接在同步的 YAML 编辑器中修改,更改会立即反映在两个视图中。这种可视化界面支持快速原型设计和调试,提升了开发体验。图 3 展示了可视化编辑器,其中说明了一个带有可重用子模块的深度研究 agent 工作流。
这些工作流的执行由一个编排整个过程的 agent harness 管理。该 harness 包括一个验证工作流结构、解析配置参数并展开模板变量的解释器。随后,它将每个操作分发给相应的处理器,管理嵌套结构(如循环和条件语句)的递归。每个操作都被分配了一个层级化的 step 标识符,用于跟踪和检查点记录。执行器实现了语言模型与外部工具之间的交互循环,管理多轮对话,直到模型返回一个不再包含进一步 tool calls 的响应或达到配置的限制。执行发生在基于 Docker 的沙盒环境中,提供隔离性并允许访问一套全面的工具,包括网络搜索、文件操作和浏览器自动化。该沙盒配备了浏览器、文件系统访问权限以及用于工具执行的 Model Context Protocol (MCP) 客户端。
agent harness 还具有强大的可观测性仪表板,提供实时监控和调试功能。该仪表板记录 agent 的动作和中间推理步骤,允许开发人员检查执行每个阶段的行为。对于长时间运行的工作流,系统通过检查点(checkpointing)和执行追踪(execution tracing)确保持久性。在每个步骤之后都会保存检查点,捕获当前的上下文、变量和沙盒状态,从而使工作流在发生中断时能够从任何点恢复。执行追踪记录了模型响应、tool calls 和对话状态的完整历史。系统支持选择性追踪重放,允许开发人员在不重新执行整个工作流的情况下,隔离特定步骤更改所产生的影响。此外,AgentSPEX 的声明式特性使得工作流的正式验证成为可能。通过在 YAML 规范中显式定义控制流、变量依赖关系和步骤边界,该框架支持对结构和语义正确性的静态及运行时验证。这通过 extract_single_citation_module 的验证得到了证明,其中每个步骤的前置条件和后置条件都使用形式化方法进行了定义和验证。验证过程检查变量在每个节点是否满足预期属性,确保工作流正确且可靠地执行。这种能力为监管 agent 行为和确保复杂自主系统的可靠性提供了途径。
实验
AgentSPEX 在科学、数学、写作和软件工程等领域的七个不同基准测试中进行了评估,以将其性能与 chain-of-thought 和 ReAct 基准进行比较。结果表明,AgentSPEX 一贯优于现有框架,特别是在需要复杂推理或处理大量文档的任务中,此时强制执行逐步执行和显式上下文管理会带来显著优势。此外,一项用户研究显示,虽然开发人员认为 AgentSPEX 在创建新工作流方面更具可读性和易用性,但他们认为现有的工具(如 LangGraph)更适合高度复杂的构建。
通过在不同模型上比较其与其他 agent 框架的性能,对 AgentSPEX 进行了评估。结果显示,AgentSPEX 在不同模型版本之间保持了稳定的性能,从一个模型升级到另一个模型时性能下降极小,而其他框架则表现出更显著的性能下降。与其它框架相比,AgentSPEX 在不同模型版本间的性能下降极小。在模型版本切换时,AgentSPEX 保持了稳定的结果。其他框架在模型版本转换时表现出更大的性能下降。
通过在三个关键能力方面将 AgentSPEX 与几种现有的 agent 框架进行比较:自然语言规范、显式上下文管理和可视化编辑。结果显示,AgentSPEX 支持自然语言和显式上下文,同时也提供可视化编辑器,使其成为一个全面的框架。其他框架要么缺乏其中一项或多项功能,要么仅部分支持。与大多数其他框架不同,AgentSPEX 支持自然语言规范、显式上下文管理和可视化编辑器。包括 LangGraph 和 n8n 在内的几个框架支持可视化编辑器,但缺乏对自然语言或显式上下文的完整支持。通过结合这三种能力,AgentSPEX 被定位为一个更全面的框架,而其他框架仅提供部分或有限的支持。
在科学、数学、写作、论文理解和软件工程的多个基准测试中评估了 AgentSPEX,并将其与 CoT 和 ReAct 等基准进行了比较。结果显示,AgentSPEX 在所有领域均持续优于基准,在需要扩展推理或复杂输入处理的任务中提升尤为显著。该框架在软件工程基准测试中也表现出强劲性能,取得了与专门化 agents 相当的结果。用户研究表明,参与者认为 AgentSPEX 更具可解释性且更易于使用,尤其是对于非编程人员,尽管他们认为 LangGraph 更适合复杂的工作流。与 CoT 和 ReAct 基准相比,AgentSPEX 在所有评估的基准测试中均实现了最高的性能。在涉及大量输入或多步推理的任务(如论文理解和化学问题)中,该框架表现出显著改进。用户评价 AgentSPEX 更具可解释性和易用性,特别是对于没有编程经验的人员。
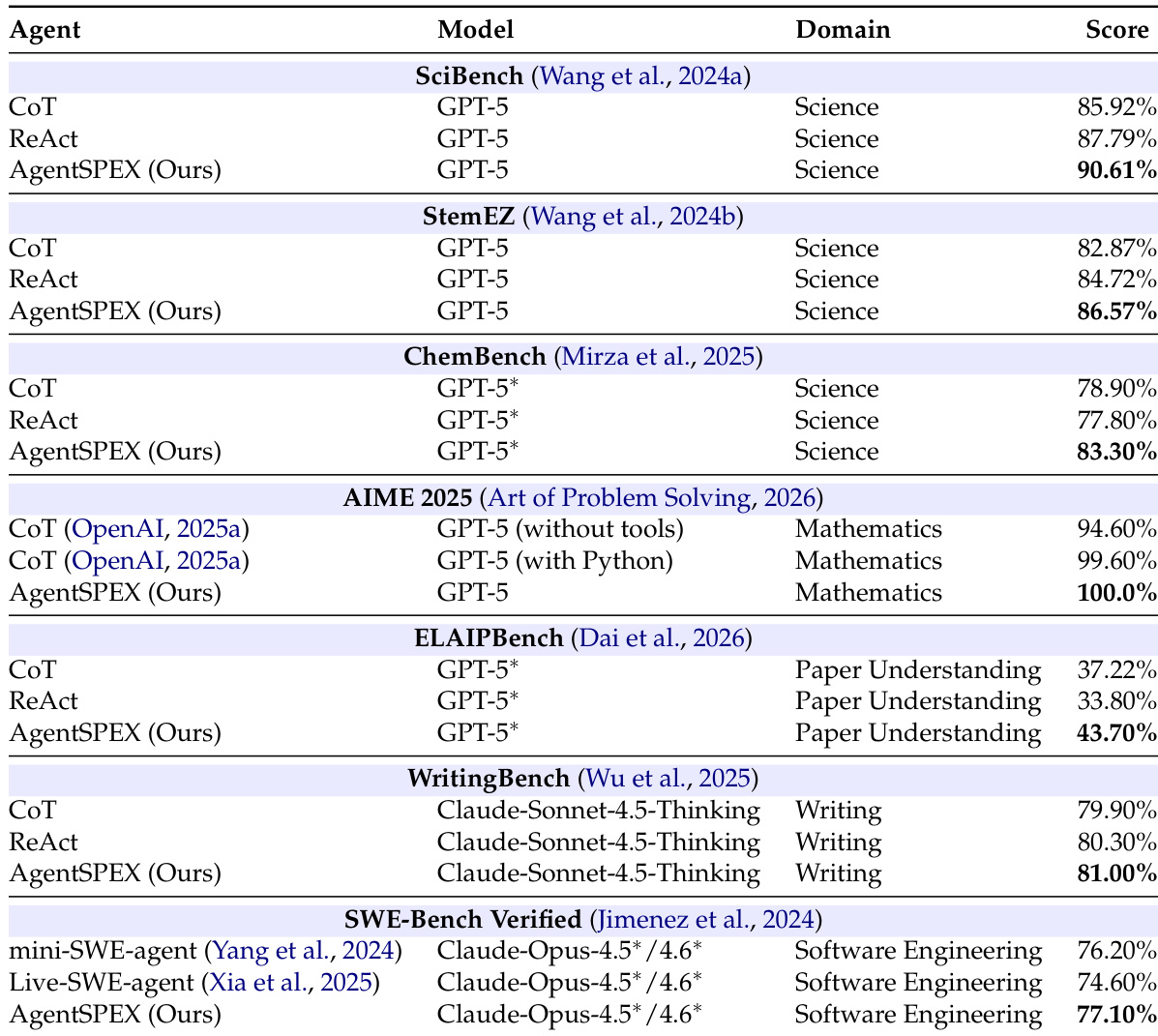
在涵盖科学、数学、写作、论文理解和软件工程领域的七个基准测试中评估了 AgentSPEX,并将其与 chain-of-thought 和 ReAct 等基准进行了比较。结果显示,AgentSPEX 在每个基准测试中都优于所有对比方法,在需要扩展推理或复杂输入处理的任务中提升尤为强劲。在跨越不同领域的七个评估基准中,AgentSPEX 均实现了最高的性能。在涉及长篇推理和多步问题解决的基准测试中,该框架较基准有了显著改进。AgentSPEX 优于 chain-of-thought 和 ReAct 基准,在需要广泛上下文管理的任务中观察到更大的增益。

通过与现有框架和推理基准的基准测试对比,结合评估可用性的用户研究,对 AgentSPEX 进行了评估。结果表明,AgentSPEX 在不同模型版本之间提供了卓越的稳定性,并通过集成自然语言规范、显式上下文管理和可视化编辑提供了更全面的功能集。此外,该框架在不同领域中持续优于标准推理方法,特别是在需要复杂、多步推理的任务中,同时对非编程人员保持了高度的可解释性和易用性。