Command Palette
Search for a command to run...
EVENT TENSOR:一种用于编译动态 MEGAKERNEL 的统一抽象方式
EVENT TENSOR:一种用于编译动态 MEGAKERNEL 的统一抽象方式
摘要
现代 GPU 工作负载,尤其是大语言模型(LLM)推理,正面临着 kernel launch 开销过大以及粗粒度同步(coarse synchronization)的问题,这些因素限制了 kernel 之间的并行性。近期的 megakernel 技术通过将多个算子融合为一个单一的 persistent kernel,旨在消除启动间隔并释放 kernel 间的并行潜力,但在处理实际工作负载中的动态形状(dynamic shapes)和数据依赖型计算(data-dependent computation)时表现不佳。我们提出了 Event Tensor,一种用于动态 megakernels 的统一编译器抽象。Event Tensor 对分块任务(tiled tasks)之间的依赖关系进行编码,并实现了对形状依赖和数据依赖两种动态特性的原生支持(first-class support)。基于这一抽象,我们构建了 Event Tensor Compiler (ETC),通过应用静态和动态调度变换来生成高性能的 persistent kernels。评估结果表明,ETC 在显著降低系统预热(warmup)开销的同时,实现了最先进的(state-of-the-art)LLM 服务延迟水平。
一句话总结
作者提出了 Event Tensor,这是一种用于动态 megakernels 的统一编译器抽象,用于编码分块任务之间的依赖关系,以支持形状和数据依赖的动态性,Event Tensor Compiler 应用静态和动态调度变换来生成高性能持久内核,实现了最先进的 LLM 服务延迟,同时显著降低了系统预热开销。
核心贡献
- Event Tensor 被引入作为一种统一的编译器抽象,用于编码分块任务之间的依赖关系,以提供对形状和数据依赖动态性的第一类支持。该抽象紧凑地表示了 GPU 流多处理器跨操作符子任务的细粒度依赖关系。
- 基于此抽象构建,Event Tensor Compiler 应用静态和动态调度变换来生成高性能持久内核。该流水线将操作符实现融合为 megakernels,以解锁超越单操作符模式的内核间并行性。
- 评估表明,该系统实现了最先进的语言模型服务延迟,同时显著降低了系统预热开销。这些结果验证了所提出的调度变换在实际工作负载中的有效性。
引言
现代 GPU 工作负载(如大型语言模型推理)受限于内核启动开销和粗粒度同步,这限制了内核间并行性。虽然 megakernel 技术融合操作符以解决启动成本,但它们难以应对实际工作负载所需的动态形状和数据依赖计算。为了解决这个问题,作者提出了 Event Tensor,这是一种统一编译器抽象,将任务依赖编码为第一类符号对象,以支持形状和数据依赖的动态性。其 Event Tensor Compiler 利用此抽象生成高性能持久内核,实现了最先进的延迟,同时显著降低了预热开销。
方法
Event Tensor Compilation (ETC) 框架通过专门的编程模型和高级编译策略优化 GPU 工作负载。该系统基于三种主要的语言构造:Device Functions、Event Tensors 和 Graph Functions。Device functions 定义并行任务网格,而 Event Tensors 作为多维结构表示任务完成事件,包含 notify() 和 wait() 等操作。Graph functions 编排这些组件,显式管理依赖关系。
参考下面的示例,其中演示了一个 IRModule,求和任务被分区,并使用 Event Tensors 跟踪依赖关系,带有特定的坐标映射。

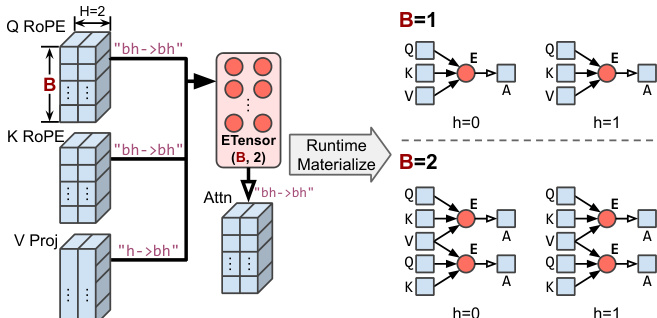
处理动态性 ETC 的一个关键特性是其能够在不重新编译的情况下处理形状和数据依赖的动态性。对于形状动态性,系统利用符号形状 Event Tensors 作为不同运行时形状的模板。
参考下面的图表,其中说明了符号批处理大小 B 如何允许依赖图动态适应不同的输入大小。
对于数据依赖的动态性,例如在 Mixture-of-Experts (MoE) 层中,系统支持不规则任务图,其中依赖关系在运行时确定。
参考下面的比较,其中对比了规则静态任务图与数据依赖任务图,其中运行时张量定义动态事件更新和任务触发。
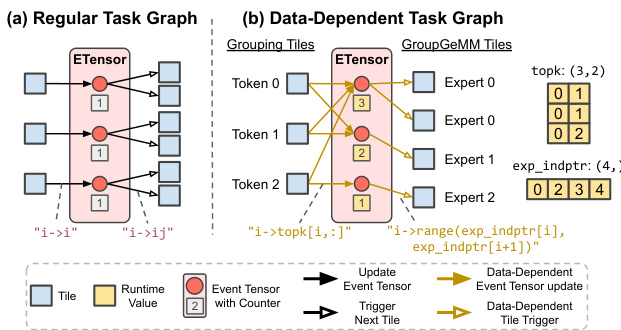
此能力对于 Attention 和 MoE 层等复杂工作负载至关重要,其中动态路由和可变形状很常见。
参考下面的高级工作流,其中描绘了从投影到 MoE 层的流程,突出了管理形状和数据依赖动态性的点。
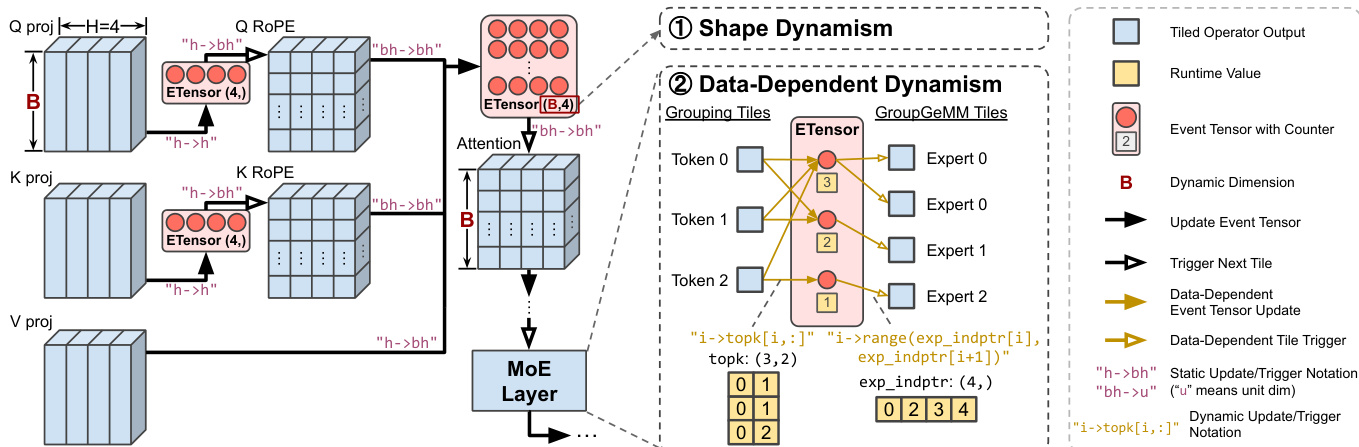
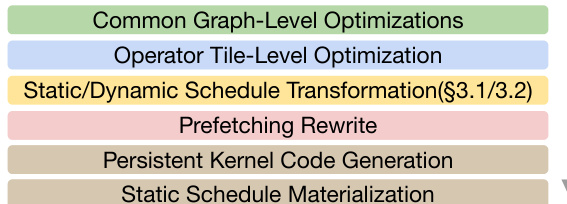
调度策略
编译过程使用静态或动态调度将计算图转换为优化的 megakernels。下面的图表对比了传统内核启动和 CUDA Graphs 与所提出的 megakernel 方法,后者最小化了启动开销并在内核内管理依赖关系。
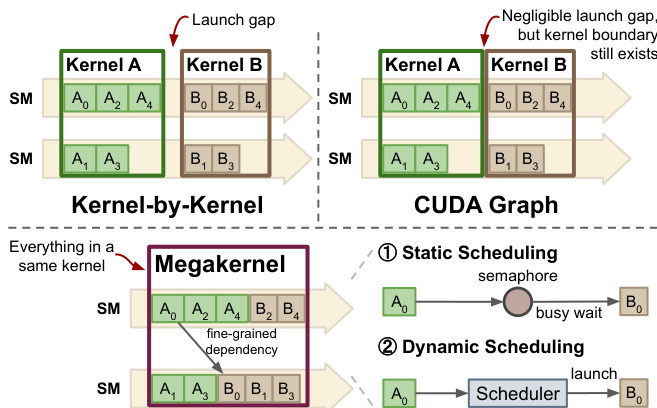
在静态调度中,多个 Device functions 融合为单个持久内核,任务预先分配给特定的 SM。
参考下面的代码变换,其中显示 GEMM 和 Reduce-Scatter 函数被融合,并插入显式的 notify 和 wait 调用以强制执行顺序。
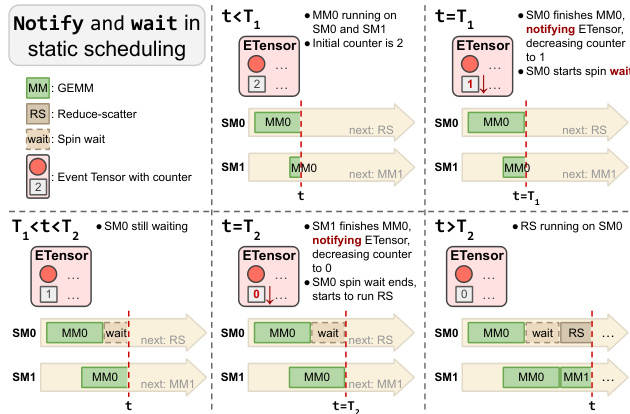
该机制依赖于低级同步,其中任务等待事件计数器归零后再继续。
参考下面的图表,其中可视化了 notify-and-wait 机制,显示 SM 如何等待其他 SM 上的依赖任务完成。
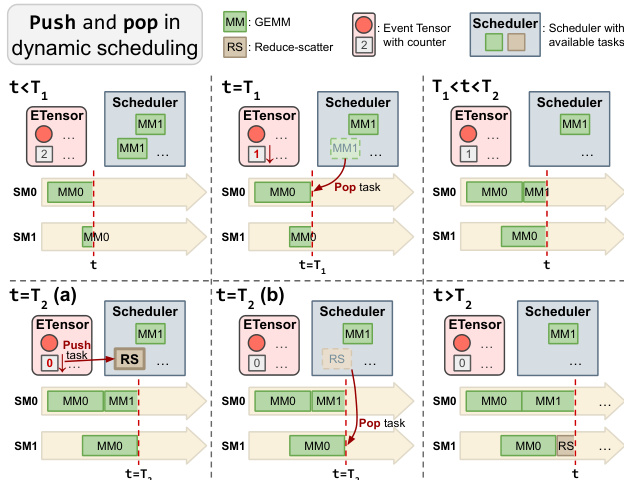
对于不可预测的工作负载,采用动态调度,利用 GPU 上的任务调度器,其中 SM 原子性地弹出就绪任务。
参考下面的代码变换,其中说明了 push-pop 机制,任务在依赖解析后推送到调度器。
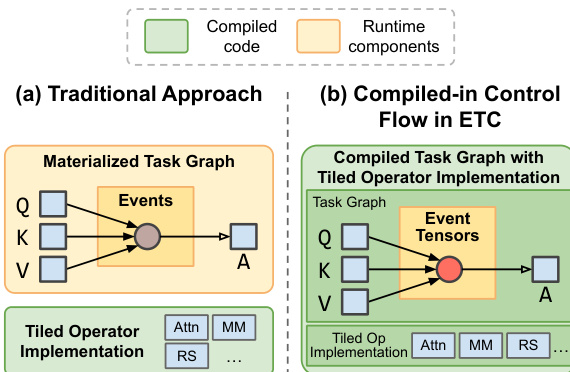
运行时架构 最后,ETC 通过将调度逻辑直接编译到 megakernels 中来最小化运行时开销,避免了在内存中实例化整个任务图的需要。
参考下面的比较,其中对比了传统运行时执行器与 ETC 将调度逻辑嵌入到编译内核中的方法。
实验
实验在 NVIDIA B200 GPU 上进行,评估基准将 ETC 与领先系统进行比较,以评估 Event Tensor 抽象如何在静态和动态任务图中管理细粒度依赖。实验表明,融合 megakernels 通过改进的流水线设计和负载均衡降低了低批量服务中以及 Mixture-of-Experts 层的端到端延迟。此外,该框架通过提前编译消除了运行时预热开销,并揭示了不同工作负载类型下静态和动态调度策略之间的不同性能权衡。
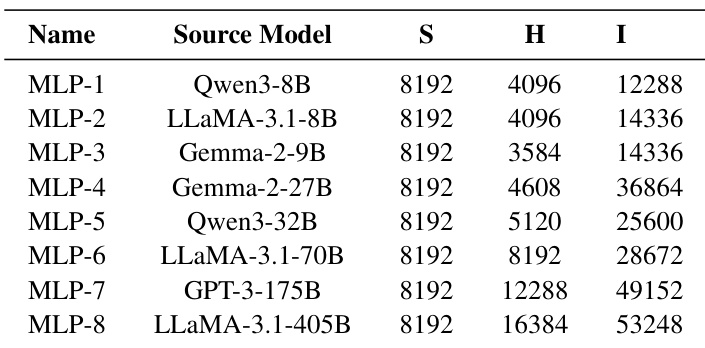
该表格展示了源自多种现代大型语言模型的 MLP 配置,以评估融合通信和计算性能。虽然所有条目的序列长度保持不变,但隐藏维度和中间大小显著缩放,以代表从小型到大型架构的模型。这种多样性允许评估系统在不同计算复杂度和模型规模下的有效性。配置涵盖了从小型到大型架构的广泛模型规模范围。所有测试的模型配置均保持一致的序列长度。随着模型规模的增长,隐藏维度和中间大小逐步增加。
作者分析了在数据依赖 Mixture-of-Experts (MoE) 工作负载上静态和动态调度策略之间的权衡。结果表明,由于更好的负载均衡,动态调度通常为较大工作负载产生更高的相对性能,而静态调度对于最小工作负载大小效率略高。除最小 token 数量外,动态调度在所有 token 数量上均提供优于静态调度的相对性能。静态调度在处理单个 token 时保持相对于动态调度的性能优势。动态调度器在中间 token 数量上达到相对于基线的最大相对增益,然后在较高数量上与静态方法收敛。

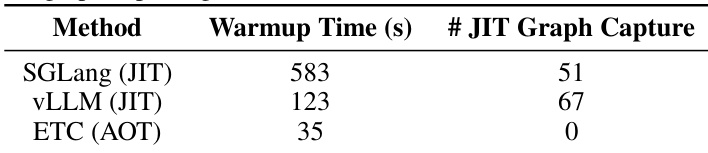
作者评估了 ETC 与基于 JIT 的系统(如 SGLang 和 vLLM)的预热开销,以评估部署影响。结果表明,ETC 的提前编译策略消除了运行时图捕获的需要,与需要捕获多个静态图的基线相比,初始化时间大幅减少。与 SGLang 和 vLLM 相比,ETC 实现了显著更快的预热性能。所提出的方法需要零运行时 JIT 图捕获,而基线需要多次捕获。基线系统由于需要捕获静态图以处理形状变化而产生了高预热成本。
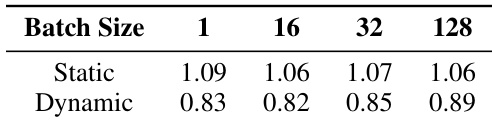
作者评估了静态和动态调度策略在具有张量并行性的规则、密集 transformer 工作负载上的性能权衡。结果表明,静态调度在所有批量大小上始终提供比动态调度更高的相对性能,这表明动态任务管理的开销对规则工作负载的效率有负面影响。静态调度在所有批量大小上始终优于动态调度。与静态方法相比,动态调度显示出降低的相对性能。随着批量大小增加,静态调度的性能优势保持稳定。
该研究评估了系统在不同模型规模和调度策略下的有效性,以评估融合通信和计算性能。结果表明,动态调度通过改进的负载均衡使数据依赖 Mixture-of-Experts 工作负载受益,而静态调度为规则密集 transformer 工作负载产生更高的效率。此外,所提出的 ETC 策略通过避免基线 JIT 系统所需的运行时图捕获,显著降低了初始化开销。