Command Palette
Search for a command to run...
PersonaVLM:长期的个性化 Multimodal LLMs
PersonaVLM:长期的个性化 Multimodal LLMs
Chang Nie Chaoyou Fu Yifan Zhang Haihua Yang Caifeng Shan
摘要
多模态大语言模型 (Multimodal Large Language Models, MLLMs) 已成为数百万用户的日常助手。然而,它们生成符合个体偏好响应的能力仍然有限。现有的方法仅能通过输入增强(input augmentation)或输出对齐(output alignment)实现静态的、单轮的个性化,因此无法捕捉用户随时间推移而演变的偏好与人格特征(见图1)。在本文中,我们提出了 PersonaVLM,这是一个专为长期个性化设计的创新型个性化多模态 Agent 框架。它通过整合三种核心能力,将通用型 MLLM 转化为个性化助手:(a) 记忆 (Remembering):它能够主动从交互中提取并总结按时间顺序排列的多模态记忆,并将其整合到个性化数据库中。(b) 推理 (Reasoning):通过从数据库中检索并整合相关记忆,进行多轮推理。(c) 响应对齐 (Response Alignment):通过长期交互推断用户不断演变的人格特征,以确保输出始终与其独特的特征保持一致。为了进行评估,我们建立了 Persona-MME,这是一个包含 2,000 多个精选交互案例的综合性 benchmark,旨在从 7 个关键维度和 14 个细粒度任务来评估 MLLM 的长期个性化能力。广泛的实验验证了我们方法的有效性:在 128k 上下文长度下,我们的方法相比基线模型在 Persona-MME 和 PERSONAMEM 指标上分别提升了 22.4% 和 9.8%,同时分别超越了 GPT-4o 5.2% 和 2.0%。项目主页:https://PersonaVLM.github.io
一句话总结
为了解决多模态大语言模型中静态个性化的局限性,作者提出了 PersonaVLM。这是一个通过主动多模态记忆提取、多轮推理和演进式人格推理来实现长期用户对齐的框架,在新建的 Persona-MME 基准测试中显著优于基准模型。
核心贡献
- 本文引入了 PersonaVLM,这是一个统一的 Agent 框架,通过整合主动记忆提取、基于记忆检索的多轮推理以及演进式响应对齐,为多模态大语言模型实现了长期的动态个性化。
- 本研究提出了 Persona-MME,这是一个全面的基准测试,包含超过 2,000 个精心策划的交互案例,旨在从七个关键方面和 14 个细粒度任务评估长期个性化能力。
- 实验结果表明,PersonaVLM 显著提升了个性化能力,在 Persona-MME 基准测试中不仅优于 GPT-4o 等闭源模型,还比领先的开源替代方案高出 22.4%。
引言
随着多模态大语言模型 (MLLMs) 成为日常助手,它们对超越通用问题解决、转向个性化长期交互的需求日益增长。目前的个性化策略很大程度上局限于通过输入增强或输出对齐实现的静态、单轮方法。这些方法无法捕捉不断变化的用戶偏好,也无法适应在长期交互过程中发生的人格转变。
作者利用一种名为 PersonaVLM 的新型 Agent 框架来实现动态的长期个性化。该框架集成了三个核心能力:主动多模态记忆管理、通过检索实现的多轮推理,以及适应用户演进人格的响应对齐。为了支持这一点,作者引入了一种专门的记忆架构和一个名为 Persona-MME 的全面基准测试,以评估多维度的个性化性能。
数据集
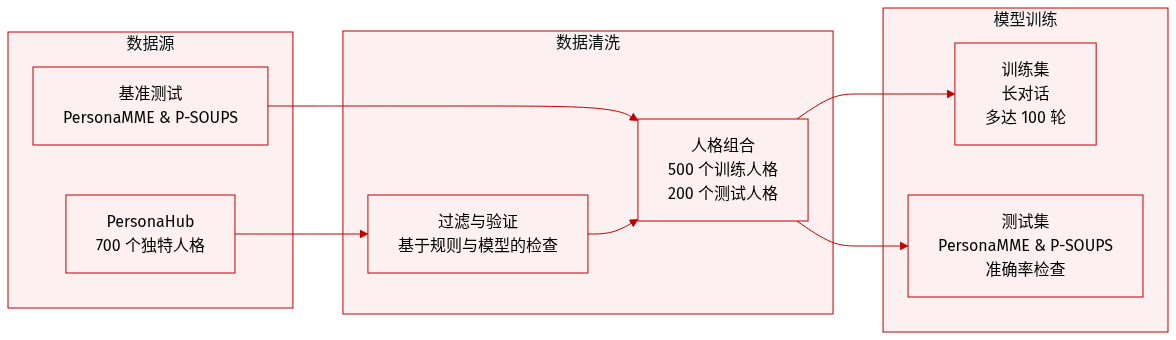
数据集概览
作者结合了合成的长期多模态对话数据和既有的基准测试来训练和评估他们的模型:
-
合成多模态对话数据集
- 组成与来源: 作者通过从 PersonaHub 中采样 700 个独特的 persona 合成了一个大规模数据集。
- 子集与分布: 数据被分为 500 个用于训练的 persona 和 200 个用于测试的 persona。训练对话包含 20 到 100 轮,模拟长达一个月的时长。
- 处理与验证: 为了确保质量、准确性和安全性,作者实施了包含基于规则的检查和基于模型的验证的两阶段过滤过程。在合成过程中,模型会生成结构化的元数据,包括情节主题的时间戳和对话轮次索引,用于数据验证。
-
评估基准测试
- PERSONAMEM: 该基准测试通过合成的多会话数据来评估具有时间线感知能力的对话能力。作者使用了两种上下文长度设置进行评估:32k 和 128k。128k 设置是通过对原始 2,728 个 persona 进行采样创建的,产生了 1,362 个多选题;而 32k 设置包含 589 个问题。
- P-SOUPS: 该基准测试从专业知识 (Expertise)、信息量 (Informativeness) 和风格 (Style) 三个维度衡量个性化。它总共包含 1,800 个测试案例(每个维度 600 个)。每个案例提供一个用户提示、一个 profile 以及一对响应(一个被选中,一个被拒绝),要求模型选择与 profile 对齐的响应。对于 few-shot 实验,作者通过单个 Pair-wise Comparative Feedback 示例来增强输入。
方法
PersonaVLM 框架旨在通过包含 Response 阶段和 Update 阶段的双阶段过程实现长期个性化,这两个阶段都在个性化记忆架构内运行。整体系统架构(如框架图所示)以包含用户查询、profile 和对话上下文的多模态输入为中心。该输入由 PersonaVLM 模型处理,模型与由四种不同记忆类型组成的个性化记忆系统进行交互:核心记忆 (Core Memory)、语义记忆 (Semantic Memory)、情节记忆 (Episodic Memory) 和程序记忆 (Procedural Memory)。这些记忆被存储和管理,以维持一个全面的长期用户 profile。系统的运行围绕两个协作阶段展开:Response 阶段负责生成感知上下文的个性化响应,Update 阶段负责演进用户的性格 profile,并在空闲期间主动更新记忆数据库。
Response 阶段负责通过执行多步推理和基于时间线的检索,在第 m 轮生成个性化响应 Rm。该过程由用户的当前查询 Qm 启动,其中包含文本指令、可选图像和时间戳,以及对话上下文 Cm 和个性化记忆数据库的状态 Mm−1。该阶段的实现涉及 PersonaVLM Agent 与其记忆系统之间的多步交互。在初始步骤中,模型接收用户指令、上下文和整合后的 profile 的提示。随后,模型输出详细的推理过程和动作结果。如果模型判定需要检索,它会生成检索条件(包括时间段和关键词),用于搜索记忆数据库。Agent 会隔离推断时间段内的记忆,并在语义、情节和程序记忆类型中进行并行搜索。每种类型的 top-k 结果会被收集并反馈给模型,以启动下一步推理。这一迭代过程持续进行,直到模型输出最终响应。这种设计通过允许模型不仅决定检索什么,还决定是否需要检索以及从何时检索,从而解决了直接语义检索和忽视时间线线索的局限性。
Update 阶段在响应生成后自动执行,负责演进用户的性格 profile 并主动更新记忆。该阶段使用提出的性格演进机制 (Personality Evolving Mechanism, PEM) 来更新用户的性格 profile Pm。PEM 将长期性格 profile 维护为一个对应于大五人格维度的向量 p∈R5。在每一轮 m,PEM 从用户最新的查询中推断出一个临时性格向量 pm′,并使用具有动态平滑因子 λ 的指数移动平均 (EMA) 来更新长期 profile。为了确保在对话早期具有高适应性,同时随着时间的推移保持稳定性,λ 采用了余弦衰减调度。更新后的数值向量 pm 随后被转换回描述性的文本摘要 Pm,用于 Response 阶段。记忆类型的更新是选择性的:语义记忆在每一轮后通过提取和存储关键信息进行更新;核心记忆和程序记忆在每个会话结束时通过自动化的 CRUD 操作进行更新;情节记忆则通过将对话分割为基于主题的条目来构建,每个条目包含摘要、关键词和相关的对话轮次。
PersonaVLM 的训练分为两个阶段,使用 Qwen2.5-VL-7B 模型作为骨干。第一阶段是在 78k 个样本的精选合成数据集上进行监督微调 (SFT),旨在使模型具备基础的记忆管理和多轮推理技能。训练数据包括记忆机制的示例(包括性格推断和四种类型的记忆 CRUD 操作),以及带有完整多步推理轨迹的 QA 对。经过 SFT 后,模型能够生成格式良好的推理和检索动作。第二阶段是强化学习 (RL),旨在进一步增强模型的多轮推理能力。该阶段采用改进的 PPO 算法——群体相对策略优化 (Group Relative Policy Optimization, GRPO) 来训练策略模型 πθ。在生成过程中,强制执行严格的结构化输出格式,要求模型首先在 <think> 标签内输出其推理过程,随后是在 <retrieve> 标签中输出检索条件,或在 <answer> 标签中输出最终响应。对于每个训练样本,会采样一组多轮轨迹,并根据准确性、逻辑一致性和格式遵循情况计算奖励。每个轨迹的优势 (advantage) 通过在其采样组内标准化其奖励来计算。
实验
评估利用了新构建的 Persona-MME 基准测试和现有的 PERSONAMEM 数据集,从记忆、意图和性格对齐等维度评估多模态大语言模型。实验通过测试 PersonaVLM 框架召回长期用户信息、对齐演进性格特征以及执行个性化开放式生成的能力来验证其有效性。研究结果表明,PersonaVLM 显著优于强大的开源模型,并能与 GPT-4o 等闭源模型竞争,特别是在涉及成长建模和行为感知的复杂任务中。定性分析进一步证实,该框架的多步推理和集成的记忆组件能有效防止幻觉,并在长期交互中保持一致的语气对齐。
{"caption": "Persona-MME dataset statistics", "summary": "该表格展示了 Persona-MME 基准测试的关键统计数据,突出了平均对话长度、多模态内容比例以及问答长度。这些指标反映了该基准测试在评估多模态交互中长期个性化方面的设计。", "highlights": ["平均对话超过 140 轮,表明用于评估的对话历史非常广泛。", "数据集中约 15.87% 的轮次是多模态的,强调了视觉和文本输入的包含。", "很大一部分问题需要视觉信息,其中 34.02% 与图像相关,突显了该基准测试的多模态特性。"]}
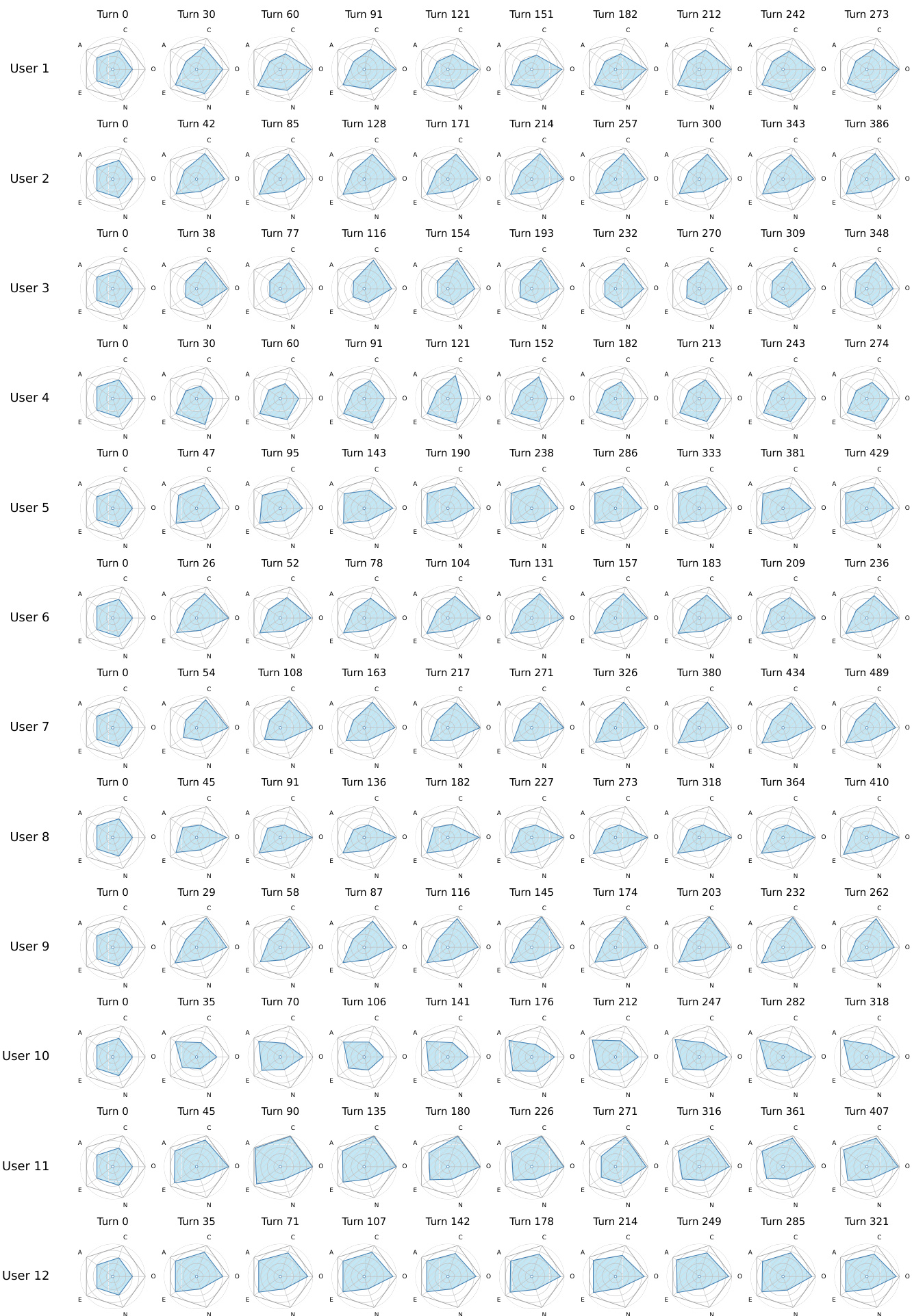
该图可视化了多个用户在系列对话轮次中性格特征的动态演变。每个用户的性格 profile 表示为一个随时间变化的雷达图,展示了随着交互推进,诸如开放性、尽责性和外向性等特征的变化。随着交互的进行,每个用户的性格特征会随时间发生变化。雷达图显示了不同用户之间截然不同的特征演变模式。可视化突出了在长时间对话过程中用户特征的纵向变化。
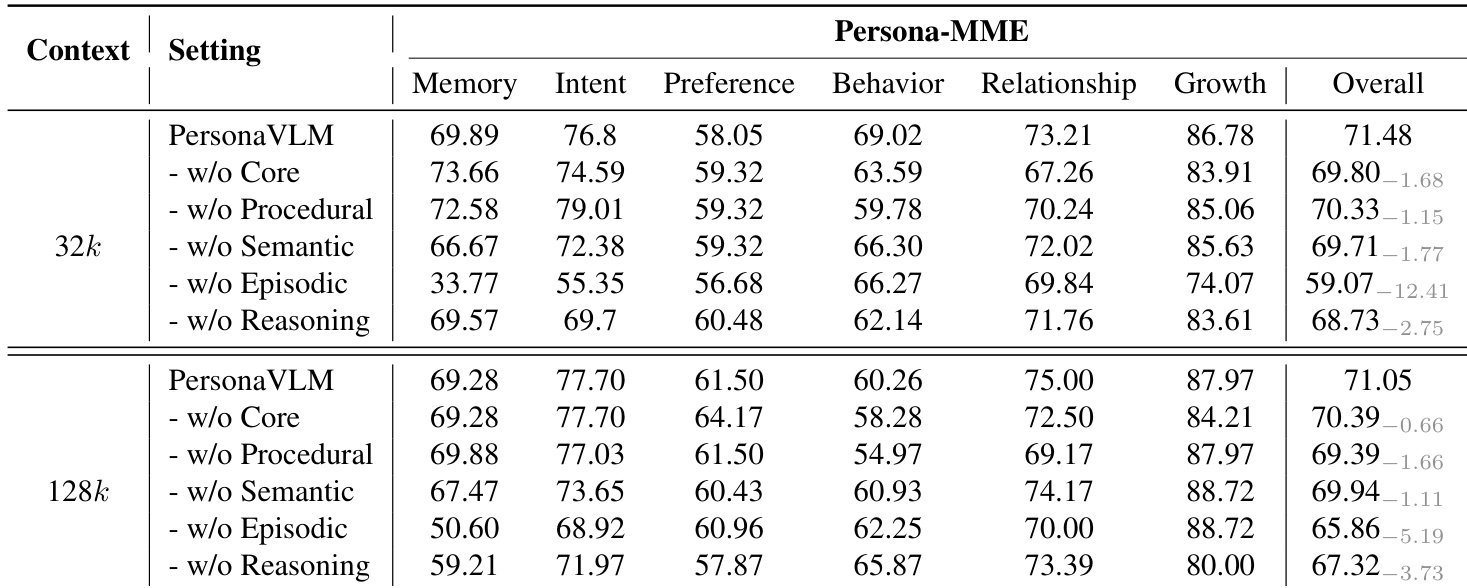
该表格展示了在 Persona-MME 基准测试上的消融实验,评估了移除 PersonaVLM 框架关键组件的影响。结果显示,完整模型在所有上下文设置下均实现了最高性能;当移除情节记忆或推理等特定组件时,性能出现显著下降,表明它们在长期个性化中起着至关重要的作用。移除情节记忆在两种上下文设置下都会导致最大的性能下降。推理组件有助于提升性能,特别是在 128k 上下文设置中。所有记忆类型和推理都是必不可少的,因为它们的移除都会降低整体性能。
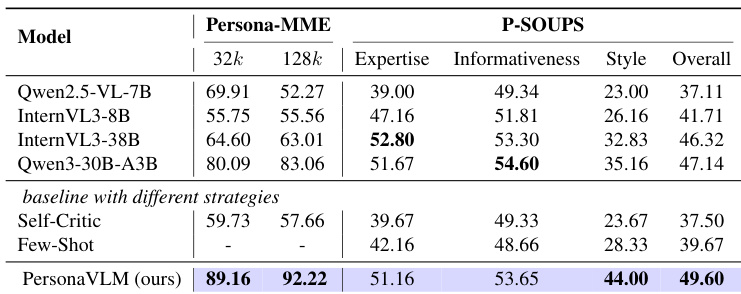
该表格对比了各种模型在 Persona-MME 和 P-SOUPS 基准测试上的表现,重点关注了不同上下文长度和对齐维度的性能。结果显示,所提出的 PersonaVLM 模型实现了具有竞争力的或更优的性能,特别是在 128k 上下文设置和关键对齐指标方面。PersonaVLM 在 128k 上下文设置和整体对齐指标上获得了最高分。该模型优于采用不同策略(包括 Self-Critic 和 Few-Shot)的基准模型。与其它模型相比,PersonaVLM 在专业知识和风格对齐方面表现出显著改进。
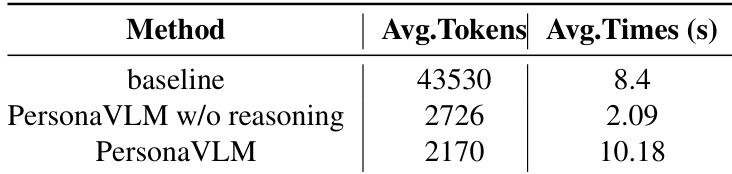
该表格对比了带有和不带有推理功能的 PersonaVLM 与基准模型的效率,测量了平均 token 消耗和响应时间。结果显示,禁用推理会显著减少 token 使用量并加快响应速度,而添加推理则会进一步减少 token 数量但增加延迟。与基准模型相比,禁用推理显著降低了 token 消耗和响应时间。与不带推理的版本相比,添加推理虽然进一步减少了 token 使用量,但增加了响应时间。不带推理的 PersonaVLM 相比基准模型实现了 93.7% 的 token 消耗减少和 4.8 倍的加速。
Persona-MME 基准测试通过广泛的对话历史和演进的用户性格特征来评估长期多模态个性化。消融实验和对比评估表明,PersonaVLM 框架通过利用情节记忆和推理等关键组件,在专业知识和风格对齐方面表现出色,特别是在长上下文设置中。虽然引入推理可以增强性能并减少 token 消耗,但它也通过增加响应延迟引入了权衡。