Command Palette
Search for a command to run...
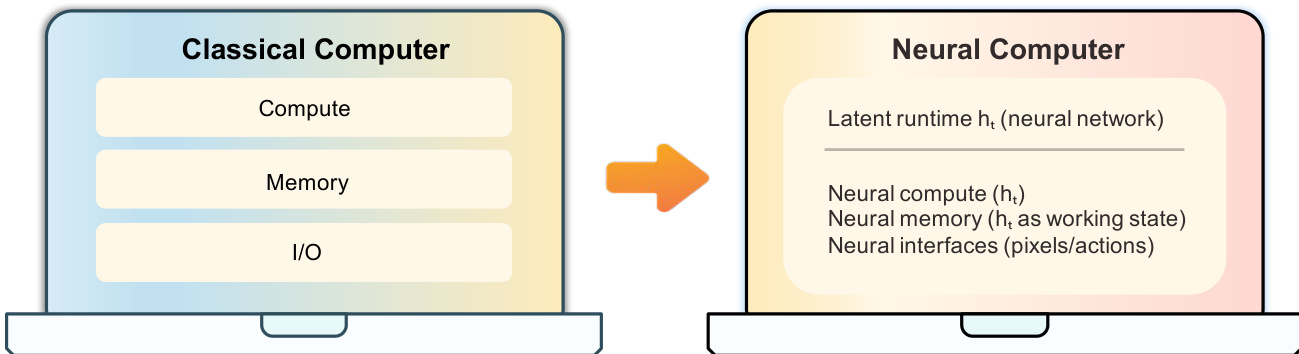
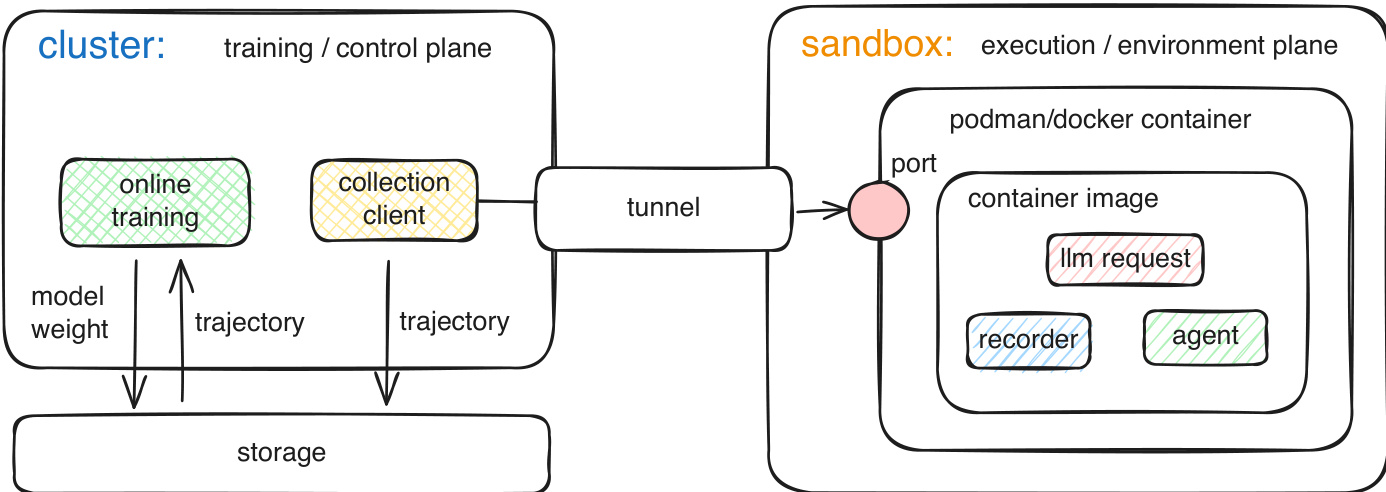
神经计算机
神经计算机
摘要
我们提出了一种全新的前沿概念:神经计算机 (Neural Computers, NCs)。这类计算机旨在通过学习到的运行时状态(learned runtime state),将传统计算机的计算、存储与 I/O 功能统一起来。我们的长期目标是实现全神经计算机 (Completely Neural Computer, CNC):即这种新兴机器形式的成熟、通用化实现,具备稳定的执行能力、显式的重编程能力以及持久的能力复用能力。作为初步探索,我们研究了是否可以仅通过收集到的 I/O 轨迹(I/O traces),在无需插桩程序状态(instrumented program state)的情况下,学习到基础的 NC 原语(primitives)。具体而言,我们将 NC 实例化为视频模型,使其能够在 CLI(命令行界面)和 GUI(图形用户界面)场景下,根据指令、像素以及用户操作(如果可用)来推演(roll out)屏幕帧。研究结果表明,NCs 能够习得基础的交互原语,尤其是在 I/O 对齐(I/O alignment)和短时程控制(short-horizon control)方面;然而,常规的任务复用、受控的更新以及符号稳定性(symbolic stability)仍面临挑战。我们概述了通往 CNC 的发展路线图,旨在建立一种超越当今 Agent 和传统计算机的新型计算范式。
一句话总结
通过将 Neural Computers (NCs) 实例化为能够根据指令、像素和用户操作推演屏幕帧的视频模型,研究人员证明了这些模型可以直接从收集到的 I/O 轨迹中学习基础的界面原语,例如 I/O 对齐和短时程控制。
核心贡献
- 本文引入了 Neural Computers (NCs) 的概念,这是一种新的机器范式,通过张量统一流水线将计算、存储和 I/O 统一到单个学习到的运行时状态中。
- 该工作提出了一种仅从收集到的 I/O 轨迹中学习基础 NC 原语的方法,将模型实例化为视频生成器,能够在 CLI 和 GUI 环境中根据指令、像素和用户操作推演屏幕帧。
- 实验结果表明,这些 NCs 可以获取早期阶段的运行时原语,特别是在界面设置中实现了 I/O 对齐和短时程控制。
引言
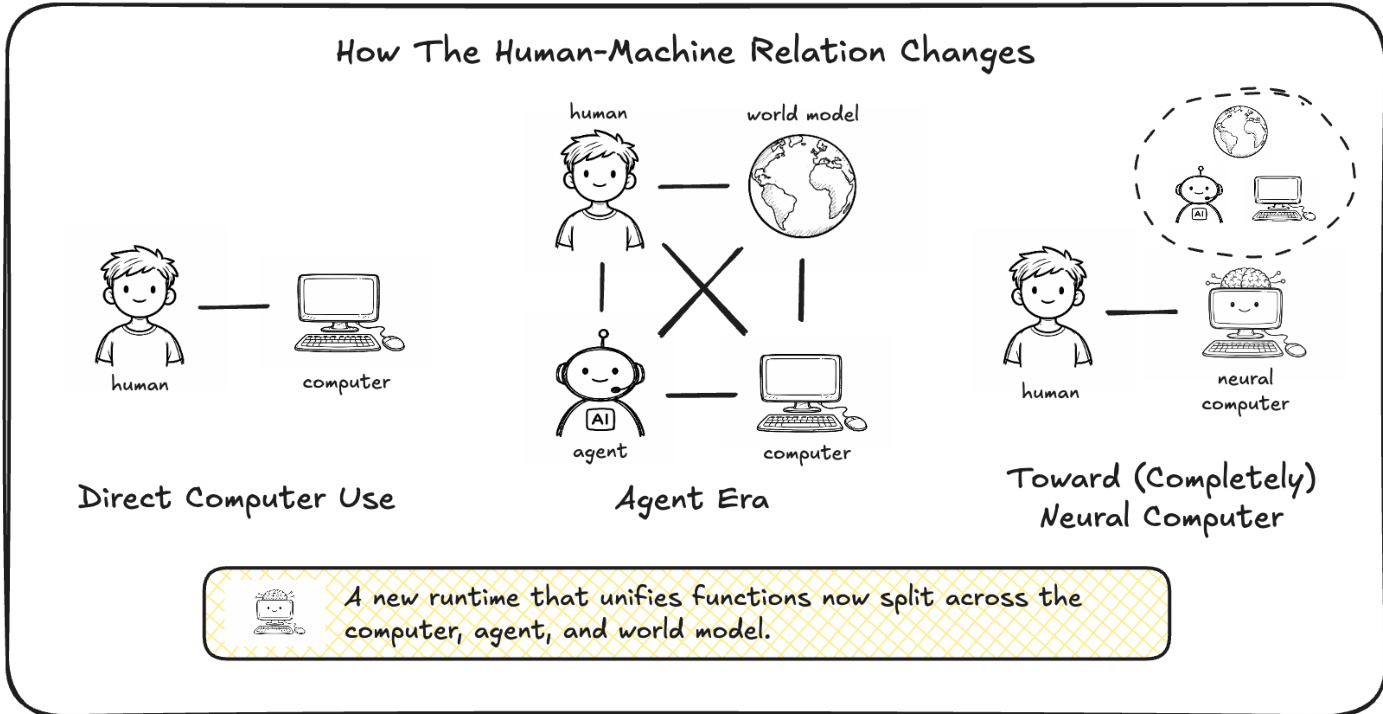
现代计算依赖于将计算、存储和 I/O 分离为不同硬件和软件层的模块化堆栈。虽然当前的 AI Agent 和世界模型试图与这些系统交互,但它们仍处于执行环境之外,导致实际运行状态处于神经模型之外。本文提出了一种名为 Neural Computers (NCs) 的新范式,将这些功能统一到单个学习到的运行时状态中。通过将 NCs 实例化为用于 CLI 和 GUI 界面的视频模型,证明了这些系统可以直接从原始交互轨迹中学习 I/O 对齐和短时程控制等基础原语。尽管目前的原型在符号稳定性及长时程推理方面存在挑战,但这项工作为迈向图灵完备且可通用编程的完全神经计算机 (Completely Neural Computers, CNCs) 提供了技术基础和路线图。
数据集
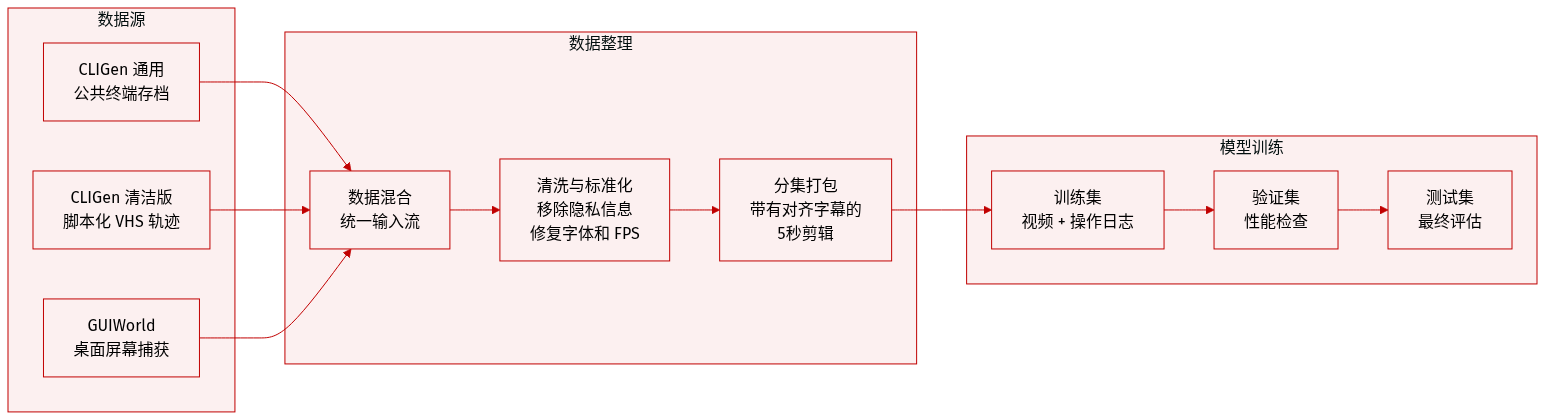
数据集概览
构建了一个专为终端和 GUI 交互建模设计的多源数据集,包含三个主要部分:CLIGen (General)、CLIGen (Clean) 和 GUIWorld。
1. 数据集组成与来源
- CLIGen (General): 源自公开的 asciinema .cast 存档。通过官方工具重放这些会话,以保留符合 ANSI 标准的解码、终端几何形状和调色板转换。
- CLIGen (Clean): 使用开源的 vhs 工具包创建。编写了约 250k 个确定性脚本,在 Docker 化环境中执行,以确保可重复且节奏良好的终端演示。
- GUIWorld: 通过受控的桌面采集设备在 Ubuntu 22.04 环境 (XFCE4) 下捕获。包括“随机慢速”(1,000 小时刻意且稀疏的移动)、“随机快速”(400 小时密集的打字和动作)以及通过 Claude CUA 收集的有监督轨迹(110 小时)。
2. 关键子集详情
- CLIGen (General): 包含 823,989 个视频流,总计约 1,100 小时。
- CLIGen (Clean): 经过 51.21% 的保留率过滤后,该子集包括:
- ~78k 个常规轨迹(例如,软件包安装、交互式 REPL 使用)。
- ~50k 个 Python 数学验证轨迹。
- GUIWorld: 提供探索数据(随机交互)与高信号、目标导向的有监督轨迹的混合。
3. 处理与训练准备
- 时间归一化: 所有片段被分割成约五秒的片段。为了保持固定长度,较短的片段会重复最后一帧,而较长的片段则进行均匀下采样。
- 帧率: 视频流被重采样为 15 FPS。
- 标注与元数据:
- 对于 CLIGen (General),使用 Llama 3.1 70B 根据底层缓冲区和日志生成三种不同的标注风格(语义、常规和详细)。
- 对于 CLIGen (Clean),标注直接源自原始 vhs 脚本。
- GUIWorld 数据集同时打包了原始动作视图和元动作视图,以支持灵活的编码器训练。
- 清洗: 流水线应用过滤器以移除敏感字符串,并对可能包含隐私内容的 GUI 区域进行脱敏处理。
4. 标准化与渲染
- 终端一致性: 为了消除排版干扰,通过固定单一的等宽字体和大小、使用一致的成功/错误状态颜色调色板以及锁定分辨率来标准化 CLIGen (Clean)。
- GUI 一致性: GUIWorld 录制使用固定的 1024x768 虚拟显示器,并配备一组特定的开源应用程序(如 Firefox、VS Code、Terminal)以确保环境稳定性。
- 对齐: 所有模态共享单一的单调时钟,以确保指针、按键和文本事件在时间上与渲染帧对齐。
方法
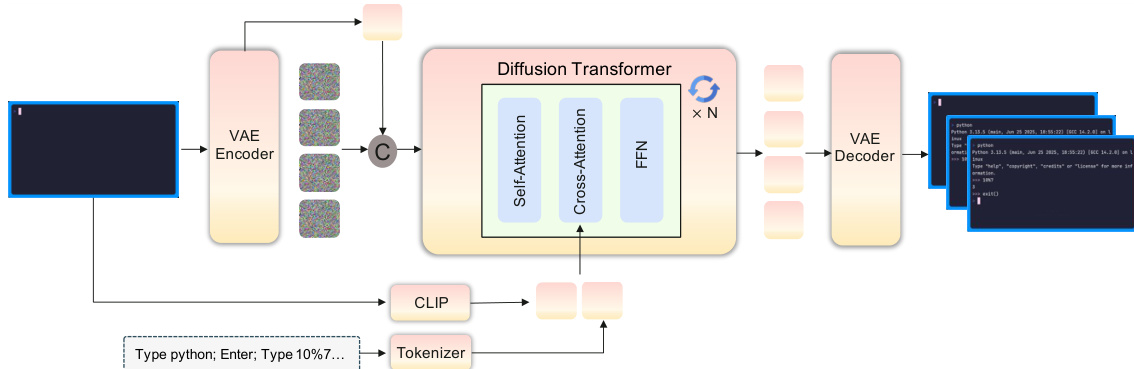
提出了一种 Neural Computers (NCs) 框架,将范式从经典计算转向统一的神经运行时。在这种架构中,潜在运行时状态 ht 由模型的随时间索引的视频潜在变量 zt 实现。Diffusion Transformer 作为状态更新映射,消耗先前的潜在变量以及当前的观测值和条件输入,从而产生更新后的状态。
该框架通过两个主要原型实例化:用于命令行界面的 CLIGen 和用于图形用户界面的 GUIWorld。对于 CLIGen,模型将生成视为文本和图像到视频的任务。第一个终端帧通过 VAE 编码为条件潜在变量,同时使用 CLIP 图像编码器和文本编码器分别提取视觉和语义特征。这些特征与扩散噪声拼接,并由 Diffusion Transformer (DiT) 堆栈处理。
在 GUIWorld 设置中,架构结合了显式的动作条件模块,以处理诸如光标追踪和键盘输入等细粒度交互。评估了两种类型的编码器:保留细粒度事件流的原始动作编码器,以及将交互抽象为类型化模式的元动作编码器。为了将这些动作特征集成到扩散骨干网络中,探索了四种不同的注入模式。

四种注入模式为:
- 外部条件 (External conditioning): 动作信息在进入 Transformer 之前调制 VAE 潜在变量。
- 上下文条件 (Contextual conditioning): Action token 与视觉 token 拼接,并通过结构化时间掩码确保因果对齐。
- 残差条件 (Residual conditioning): 轻量级动作模块在特定的 Transformer 层对隐藏状态应用残差更新。
- 内部条件 (Internal conditioning): 动作交叉注意力子层直接集成在 Transformer 块内。
为了确保高保真度的光标渲染,采用了显式的光标流水线。不再仅仅依赖全局扩散损失,而是使用 SVG 模板将光标渲染为一等公民条件信号,并应用掩码补丁损失 (masked patch loss) 来监督重建的光标区域。此外,利用时间对比损失将动作路径与潜在视频时间线对齐,在考虑用户动作与视觉反馈之间自然延迟的同时,推动匹配的帧与动作特征趋于一致。
实验
对神经计算机 (NC) 原型的评估表明,模型实现了高保真度的终端渲染和字符级准确度,特别是在使用详细的字面标注进行文本到像素对齐时。虽然模型在算术任务的固有符号推理方面存在困难,但通过系统级条件化和重新提示,性能得到了显著提升,而无需强化学习。在交互式 GUI 环境中,结果表明,高质量、目标导向的数据和深层动作注入方案对于稳定的响应性比单纯的数据集规模更为关键。此外,为光标动态提供显式的视觉监督,对于实现精确控制和克服基于抽象坐标的编码限制至关重要。
评估了改进神经计算机光标控制准确度的不同监督方法。结果显示,虽然基于坐标的监督提供的准确度极低,但显式的视觉条件化显著增强了精度。仅基于坐标的监督产生较低的准确度。在位置数据中添加傅里叶特征仅带来微小的改进。使用显式的 SVG 掩码和参考帧会导致光标准确度大幅提升。

在内部注入模式下,比较了两种不同的动作编码方法,以评估其对 GUI 交互保真度的影响。结果显示,与原始事件流编码相比,使用结构化的元动作表示在所有测量的动作后指标上都表现出更好的性能。与原始动作编码相比,元动作编码提高了结构一致性并减少了时间失真。API 式表示比事件流方法实现了更低的感知距离。相对于改变动作注入方案带来的巨大收益,编码粒度提供的改进较为有限。

评估了不同的动作注入方案,以确定条件化的深度如何影响动作后的界面保真度。结果显示,将动作信息更深层地集成到模型骨干网络中,可以带来更好的结构一致性和更低的时间失真。在测试的方案中,内部注入实现了最高的结构相似度和最低的时间失真。残差注入在最小化感知距离方面提供了最佳结果。从外部条件化转向更深层的 token 级融合,显著提升了结构和感知指标。

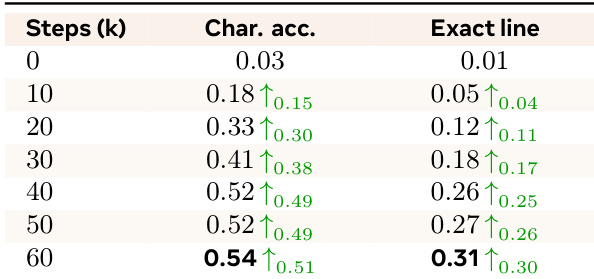
评估了模型在训练过程中字符级的文本渲染准确度。结果显示,字符准确度和精确行准确度在训练早期阶段均显著提高,随后达到平台期。字符准确度从初始化开始在最初的 40k 步内稳步增长。精确行准确度随着训练的进行呈现持续上升趋势。基于 OCR 的指标的大部分性能增益是在最初的 40k 到 60k 步内实现的。
通过算术探测任务评估了各种视频模型的符号推理能力。结果表明,与人类表现相比,大多数当前模型在这些符号操作方面都面临巨大挑战。大多数测试的视频模型在基础算术任务上的准确度非常低,Sora2 是一个显著的离群值,其性能明显高于其他模型。低分表明,对于这些神经计算机实例化而言,固有的符号推理仍然是一个主要挑战。

评估了神经计算机性能的各个组成部分,包括监督方法、动作编码、注入方案、文本渲染和符号推理。研究结果表明,显式的视觉条件化和更深层的内部动作注入显著增强了光标精度和界面保真度,而结构化的元动作表示优于原始事件流。尽管文本渲染准确度在训练早期稳步提高,但大多数当前的视频模型在基础符号推理任务方面仍面临困难。