Command Palette
Search for a command to run...
面向高效且具成本效益的 Retrieval-Augmented Generation 系统的 Web Retrieval-Aware Chunking (W-RAC) 研究
面向高效且具成本效益的 Retrieval-Augmented Generation 系统的 Web Retrieval-Aware Chunking (W-RAC) 研究
Uday Allu Sonu Kedia Tanmay Odapally Biddwan Ahmed
摘要
检索增强生成(Retrieval-Augmented Generation, RAG)系统极度依赖有效的文档分块(chunking)策略,以平衡检索质量、延迟以及运营成本。传统的分块方法,如固定大小分块、基于规则的分块或完全基于 Agent 的分块,在处理大规模网络内容摄取时,往往面临 token 消耗高、文本生成冗余、可扩展性有限以及可调试性差等问题。在本文中,我们提出了 Web Retrieval-Aware Chunking(W-RAC),这是一种专门为网页文档设计的、具有高成本效益的新型分块框架。W-RAC 通过将解析后的网页内容表示为结构化的、可通过 ID 定址的单元,将文本提取与语义分块规划进行解耦;同时,该框架仅利用 LLMs 进行感知检索的分组决策,而非用于文本生成。这种方式显著降低了 token 使用量,消除了幻觉(hallucination)风险,并提升了系统的可观测性。实验分析与架构对比表明,W-RAC 在实现与传统分块方法相当甚至更优的检索性能的同时,将与分块相关的 LLM 成本降低了一个数量级。
一句话总结
作者提出了 Web Retrieval-Aware Chunking (W-RAC),这是一种针对基于 Web 的 RAG 系统的低成本框架。该框架通过仅利用 LLM 进行感知检索的分组决策,而非进行文本生成,从而将文本提取与语义规划解耦,在保持高检索性能和提升可观测性的同时,降低了 token 消耗和幻觉风险。
核心贡献
- 本文引入了 Web Retrieval-Aware Chunking (W-RAC),该框架通过将确定性的 Web 解析与基于 LLM 的分组决策解耦,将分块(chunking)重新定义为一个语义规划问题。
- 该方法利用解析后的 Web 内容的结构化、ID 可寻址表示,允许 LLM 在不重新生成文本的情况下做出分组决策,从而消除了幻觉风险并提高了系统的可观测性。
- 在 RAG-Multi-Corpus 基准测试上的实验结果表明,与 agentic chunking 相比,W-RAC 实现了相当或更优的检索性能,同时将 LLM 成本降低了 51.7%,并将输出 tokens 减少了 84.6%。
引言
检索增强生成 (RAG) 系统依赖于有效的文档分块,以平衡检索精度、延迟和运营成本,尤其是在摄取大规模 Web 内容时。虽然固定大小和基于规则的方法往往无法保持语义完整性,但 agentic chunking 方法会带来高额的计算开销,通过文本重新生成带来幻觉风险,并且缺乏大规模流水线所需的扩展性。作者利用了一种名为 Web Retrieval-Aware Chunking (W-RAC) 的新颖框架,将分块重新定义为语义规划问题而非生成任务。通过将确定性的 Web 解析与基于 LLM 的分组决策解耦,并使用结构化的 ID 可寻址单元,W-RAC 在显著降低 token 消耗和总 LLM 成本的同时,实现了与 agentic 方法相当的检索性能。
数据集
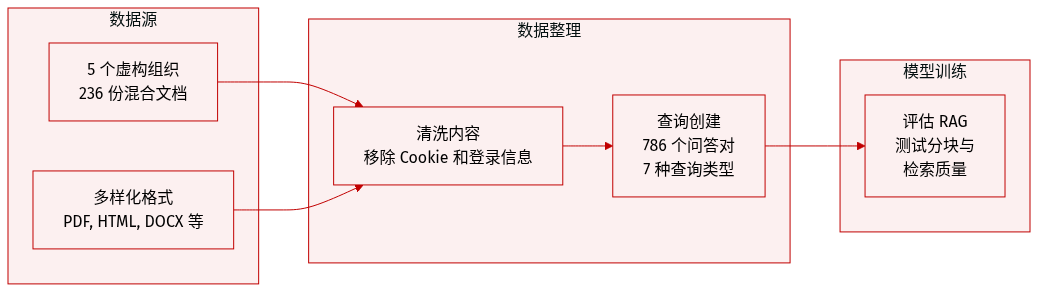
作者引入了 RAG-Multi-Corpus,这是一个旨在模拟真实世界企业知识库的多格式、多领域基准测试。数据集详情包括:
- 数据集组成与来源:该基准测试由来自五个虚构组织的 236 份文档组成。这些文档涵盖了多种企业格式,如 PDF、Markdown、HTML、DOCX 和 PPTX,以反映生产级 RAG 流水线的异构性。
- 查询与回答详情:数据集包含 786 个精心策划的查询-回答对,每个回答都附有标准引用(ground-truth citations)。查询被分为七种不同类型,以确保在事实召回、推理、比较和程序理解方面的均衡覆盖。
- 数据处理与过滤:为了确保数据质量,作者应用了过滤规则来移除无关内容,特别针对 cookie、页面导航元素和登录信息。
- 使用与评估策略:作者使用这种多样化的查询组合来评估检索的鲁棒性,并评估不同的分块策略如何影响检索质量。其分布专门设计用于测试对分块边界和语义连贯性的敏感度,特别是针对程序性和比较性问题。
方法
W-RAC 系统围绕一个三阶段流水线设计,该流水线在强调感知检索分块的同时,保留原始源文本并最大限度地减少计算开销。框架始于确定性的 Web 解析,将原始 Web 内容转换为结构化表示,例如从 HTML 到 Markdown,再到抽象语法树 (AST)。每个语义单元(包括标题和段落)都被分配一个稳定的唯一标识符,以确保处理阶段的一致性。这种结构化表示为后续阶段奠定了基础,实现了精确且可重复的操作。

如上图所示,系统进入基于 LLM 的分块规划阶段,此时大语言模型 (LLM) 的任务是生成分块计划而非重新生成文本。LLM 接收到的不是原始内容,而是一组标识符、层级关系、排序信息以及可选的元数据(如 token 数量和标题层级)。随后,LLM 输出一个结构化的分块计划列表,每个分块表示为标识符的有序数组。这种方法将 LLM 定位为语义分组规划器,负责根据结构和上下文线索确定最佳边界。输出是一个 JSON 格式的分块列表,每个分块包含一组与原始文本单元相对应的标识符序列。
在分块规划之后,系统进入后处理和索引阶段。在此阶段,通过将标识符数组映射回其对应的文本内容,在本地解析分块计划。最终的分块通过按照计划指定的顺序拼接原始文本来组装,然后进行嵌入并索引到检索系统中。这确保了生成的分块既具有语义连贯性,又针对下游检索任务进行了优化。
W-RAC 的一个关键方面是其感知检索的设计,它显式地将检索考虑因素纳入分块规划过程。分块边界受多种因素影响,包括标题深度和章节层级、token 长度限制、实体密度以及语义凝聚力。此外,内容类型(如表格、插图或代码块)被视为一个凝聚单元,绝不会跨分块拆分。这种设计确保了分块与现实世界的查询模式更加契合,从而提高了召回率和精确度。
分块规划过程由一套严格的规则和原则指导。系统强制执行三级标题层级,每个分块组必须包含一级(Level 1)、二级(Level 2)和直接父级(Level 3)标题。缺失的层级使用最匹配的现有标题 ID 进行填充,并允许重用标题 ID。当一个父标题有多个子标题时,父 ID 会包含在每个子组数组中,以确保结构连续性。程序性内容(如逐步说明、编号程序或顺序列表)绝不会跨分块拆分;相反,所有步骤都会被组合到一个单一的分块数组中,以保持逻辑流。较小或缺乏上下文的分块会与相邻内容或标题合并,以确保每个分块都具有充分的上下文。
系统还优先考虑上下文和合并,利用标题层级、父子关系和顺序模式在未明确定义结构的地方进行推断。输入通过一系列步骤进行处理:映射标题层级、识别程序性内容、追踪每个分块的三级层级,并确保父标题包含在子组中。最后,分块被分组为逻辑数组,并以指定的 JSON 格式输出(不带代码块或反引号),每个数组至少包含一个标题或足够的上下文。这种结构化输出确保了清晰度、完整性以及与检索要求的对齐。
实验
实验使用 RAG-Multi-CORPUS 基准测试将 W-RAC 方法与传统的 agentic chunking 进行对比,以评估摄取效率和检索质量。结果表明,W-RAC 通过最大限度地减少输出 token 消耗,显著降低了计算开销、处理时间和成本。此外,该方法在各种查询类型中实现了更优的精确度,同时保持了具有竞争力的召回率和排序性能,为生产系统提供了运营效率与检索有效性的最佳平衡。
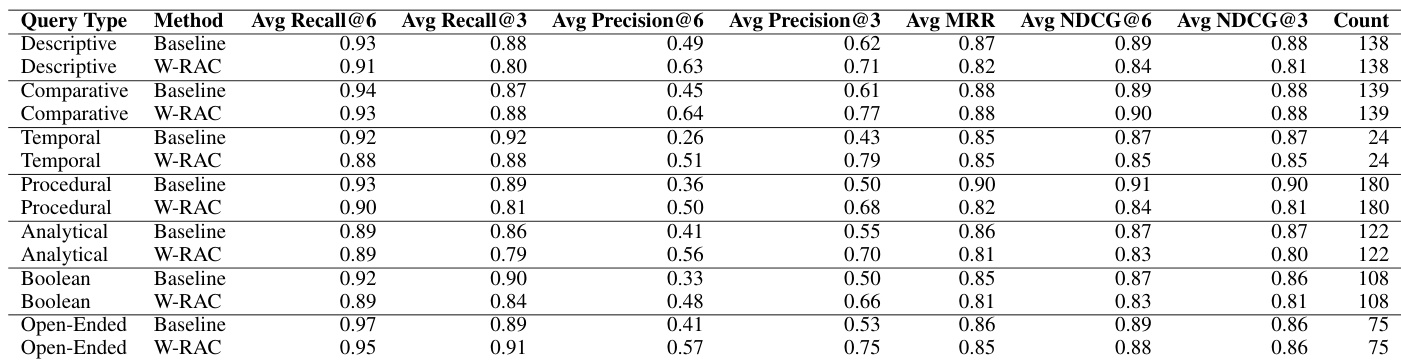
作者从多个指标的检索质量方面将 W-RAC 与基准方法进行了比较。结果显示,W-RAC 在保持竞争力的召回率和排序分数的同时,实现了更高的精确度,表明检索结果的相关性有所提高。与基准相比,W-RAC 在所有评估指标上都提高了精确度。尽管精确度更高,W-RAC 仍保持了具有竞争力的召回率和排序质量。检索结果表明,在其他指标权衡极小的情况下,精确度实现了持续增长。

作者从成本、保真度和扩展性等关键维度比较了传统分块、agentic chunking 和 W-RAC。结果显示,W-RAC 在文本保真度和扩展性方面表现出高性能,同时最大限度地降低了幻觉风险和 LLM token 成本。与传统和 agentic chunking 相比,W-RAC 实现了高文本保真度和低幻觉风险。W-RAC 展示了高扩展性和 Web 适用性,在这些维度上优于其他方法。W-RAC 的 LLM token 成本非常低,使其比传统和 agentic chunking 方法更高效。

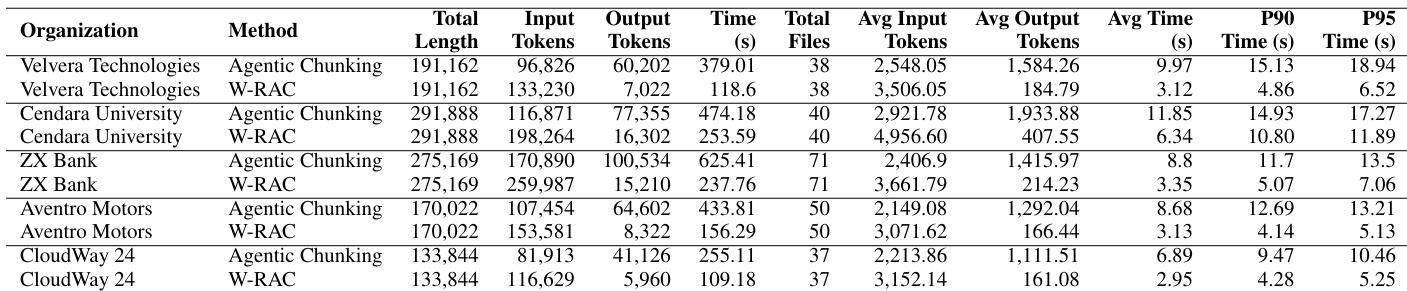
作者比较了 Agentic Chunking 和 W-RAC 的成本效率,重点关注输入、缓存和输出 token 的消耗。结果显示,W-RAC 在增加输入 token 使用量的同时,显著降低了输出 token 成本和总体支出,从而实现了大幅成本节约。尽管输入 token 消耗较高,该方法仍保持了具有竞争力的检索性能。与 Agentic Chunking 相比,W-RAC 降低了 80% 以上的输出 token 成本;W-RAC 虽然增加了 50% 的输入 token 使用量,但实现了显著的整体成本节约;W-RAC 的总成本远低于 Agentic Chunking,证明了其成本效率的提升。

作者在多个组织中将 W-RAC 与传统的 agentic chunking 进行比较,评估了 token 使用量、处理时间和成本效率。结果显示,W-RAC 在增加输入 tokens 的同时,显著减少了输出 tokens 和处理时间,从而实现了大幅成本节约。尽管输入 token 使用量较高,W-RAC 仍保持了具有竞争力的检索性能,并在精确度方面有显著提升。与 agentic chunking 相比,W-RAC 大幅减少了输出 tokens 和处理时间。W-RAC 增加了输入 tokens,但由于较低的输出 token 消耗,实现了实质性的成本节约。W-RAC 在所有组织和查询类型中都提高了检索精确度,同时保持了具有竞争力的召回率和排序质量。
作者在各种查询类型下将 W-RAC 与基准方法进行比较,使用标准指标评估检索有效性。结果显示,W-RAC 在所有查询类别中都实现了更高的精确度,同时保持了具有竞争力的召回率和排序质量。W-RAC 提高了所有查询类型的精确度,其中在时序和比较查询中的提升最为显著。尽管精确度更高,W-RAC 仍保持了具有竞争力的召回率和排序指标。精确度的提升在描述性、程序性、分析性和开放式查询中表现一致。
作者通过针对基准和 agentic chunking 方法的对比实验评估了 W-RAC,重点关注检索质量、文本保真度、扩展性和成本效率。结果表明,W-RAC 在各种查询类型和组织中一致地提高了检索精确度,同时保持了具有竞争力的召回率和排序性能。此外,与现有的分块方法相比,该方法提供了更优的文本保真度和扩展性,且总体成本和处理时间显著降低。