Command Palette
Search for a command to run...
TriAttention:基于三角函数 KV Compression 的高效长文本 Reasoning
TriAttention:基于三角函数 KV Compression 的高效长文本 Reasoning
Weian Mao Xi Lin Wei Huang Yuxin Xie Tianfu Fu Bohan Zhuang Song Han Yukang Chen
摘要
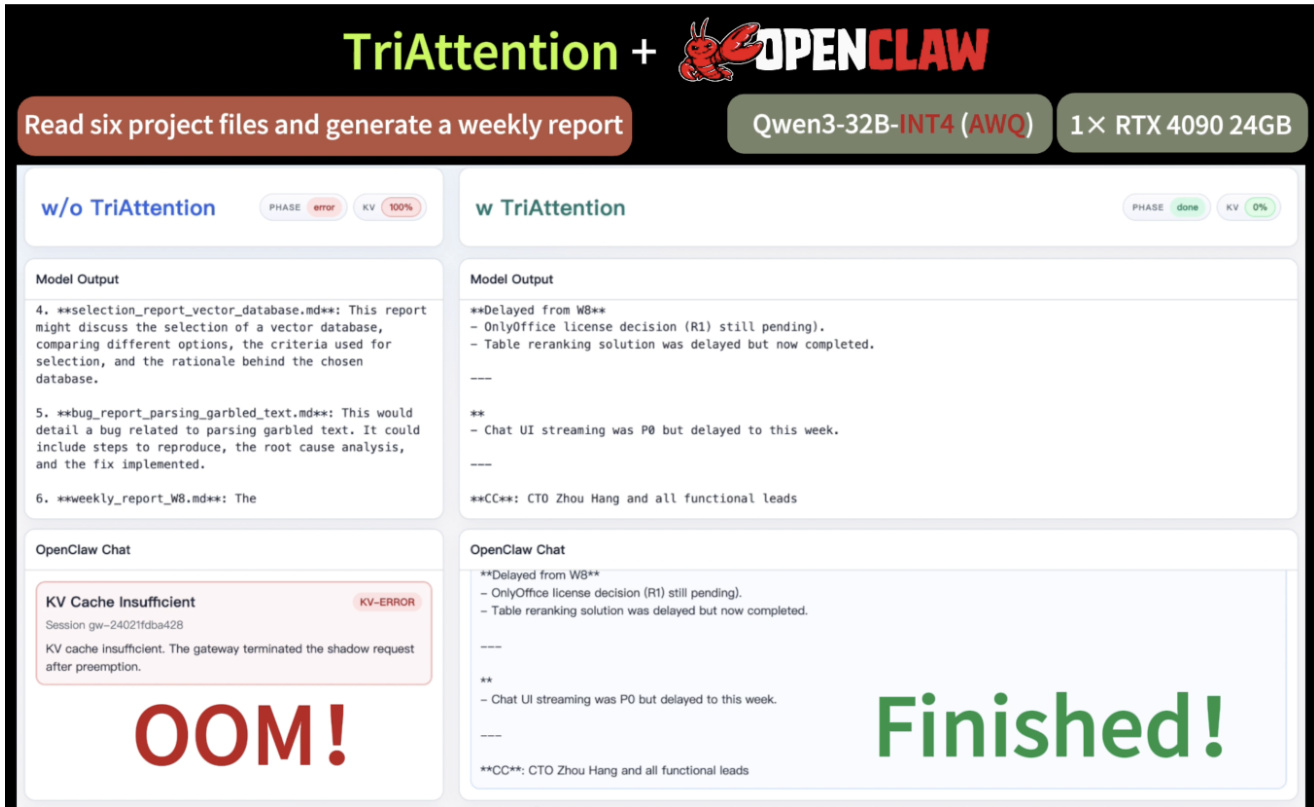
大语言模型(LLMs)中的长程推理(Extended reasoning)会导致严重的 KV cache 内存瓶颈。主流的 KV cache 压缩方法通过使用 RoPE(旋转位置编码)之后的近期 query 的 attention scores 来评估 KV 的重要性。然而,由于 query 在 RoPE 过程中会随位置发生旋转,导致具有代表性的 query 非常稀少,进而引发 top-key 选择偏差以及推理不稳定的问题。为了规避这一问题,我们将视角转向 pre-RoPE 空间。我们观察到,在 pre-RoPE 空间中,Q 和 K 向量高度集中在固定的非零中心附近,并且在不同位置保持稳定——我们称之为 Q/K 集中性(Q/K concentration)。研究表明,这种集中性会导致 query 优先关注特定距离(例如最近的 key)的 key,而这些中心点通过三角级数(trigonometric series)决定了哪些距离会被优先关注。基于这一发现,我们提出了 TriAttention,通过利用这些中心点来评估 key 的重要性。通过三角级数,我们利用由这些中心点表征的距离偏好,根据 key 的位置对其进行评分,并辅以 Q/K norm 作为重要性估计的额外信号。在 AIME25 基准测试中,针对 32K-token 的生成任务,TriAttention 在达到与 Full Attention 相当的推理准确率的同时,实现了 2.5 倍的吞吐量提升或 10.7 倍的 KV 内存缩减;相比之下,领先的基线方法在同等效率下准确率仅能达到约一半。TriAttention 使得在单张消费级 GPU 上部署 OpenClaw 成为可能,而在使用 Full Attention 的情况下,长上下文会导致显存溢出(out-of-memory)。
一句话总结
为了解决 post-RoPE 重要性估计的不稳定性,研究人员提出了 TriAttention。这是一种 KV cache 压缩方法,它利用 pre-RoPE 空间中的 Q/K 集中现象,并使用三角级数来建模基于距离的 attention 偏好。在 AIME25 上,该方法在进行 32K-token 生成时能达到与 Full Attention 相当的准确度,同时实现 2.5 倍的吞吐量提升或 10.7 倍的 KV 内存减少。
核心贡献
- 本文发现了一种称为 pre-RoPE 空间中 Q/K 集中(Q/K concentration)的现象,即无论位置如何,query 和 key 向量都会聚集在稳定的非零中心周围。
- 这项工作引入了 TriAttention,该方法通过使用三角级数来表征基于这些稳定中心的距离偏好,并结合 Q/K 范数作为额外信号,从而估计 key 的重要性。
- 在 AIME25 等基准测试上的实验结果表明,与现有基线相比,TriAttention 在实现 2.5 倍吞吐量提升或 10.7 倍 KV 内存减少的同时,能够匹配 Full Attention 的推理准确度。
引言
随着大语言模型进行长程推理,不断增长的 KV cache 造成了显著的内存瓶颈,阻碍了长上下文性能。现有的压缩方法通常在 post-RoPE 空间中估计 token 重要性,但这些方法效果不佳,因为位置旋转会导致 query 向量不断偏移。这种旋转使得识别具有代表性的 queries 变得困难,并导致重要性估计不稳定或关键方向信息的丢失。作者利用了在 pre-RoPE 空间中发现的一种称为 Q/K 集中(Q/K concentration)的特性,即向量会聚集在稳定的固定中心周围。通过使用三角级数来建模这些中心如何决定基于距离的 attention 偏好,他们提出了 TriAttention,以更可靠、更高效地估计 key 的重要性。
数据集
请提供您希望我总结的论文段落。您在提示词中提供的文本仅包含一个标题和关于基准测试的占位句,不包含起草描述所需的必要技术细节(组成、来源、规模或处理规则)。
一旦您提供了全文,我将按照您的所有要求生成简洁的数据集描述。
方法
作者利用旋转位置嵌入(RoPE)通过向量空间中的旋转来建模位置信息,这是他们方法的基础组件。RoPE 的工作原理是将一个 d 维向量划分为 d/2 个二维子空间,每个子空间关联一个频率带 f。对于每个频带,在位置 p 应用角度为 ωfp 的旋转,其中 ωf=θ−2f/d 且 θ=10000 是一个固定常数。这种旋转被表示为向量分量 (x2f,x2f+1) 上的线性变换,从而产生 post-RoPE 向量。作者观察到,pre-RoPE 空间中的 queries 和 keys 高度集中在非零中心周围,这种现象在不同的位置和上下文中是一致的,如下方图中的分布图所示。
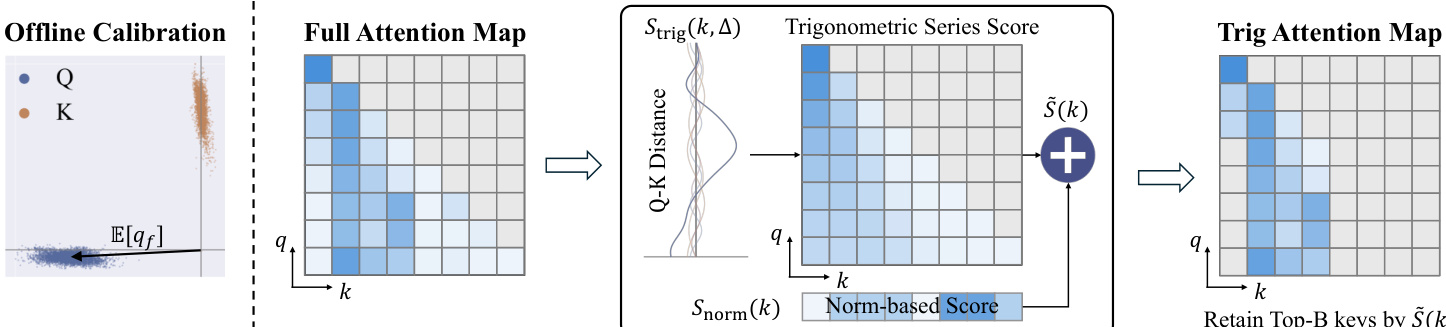
这种集中程度使用平均合向量长度 R=∥E[q]∥/E[∥q∥] 来量化,其中趋近于 1 的值表示具有很强的方向集中性。作者表明,这种集中性使得 attention 计算可以通过三角级数来近似。当 query 和 key 向量近似恒定时,attention logit 会简化为相对位置 Δ=pq−pk 的余弦项和正弦项之和,形成一个系数由向量幅度和相位决定的三角级数。
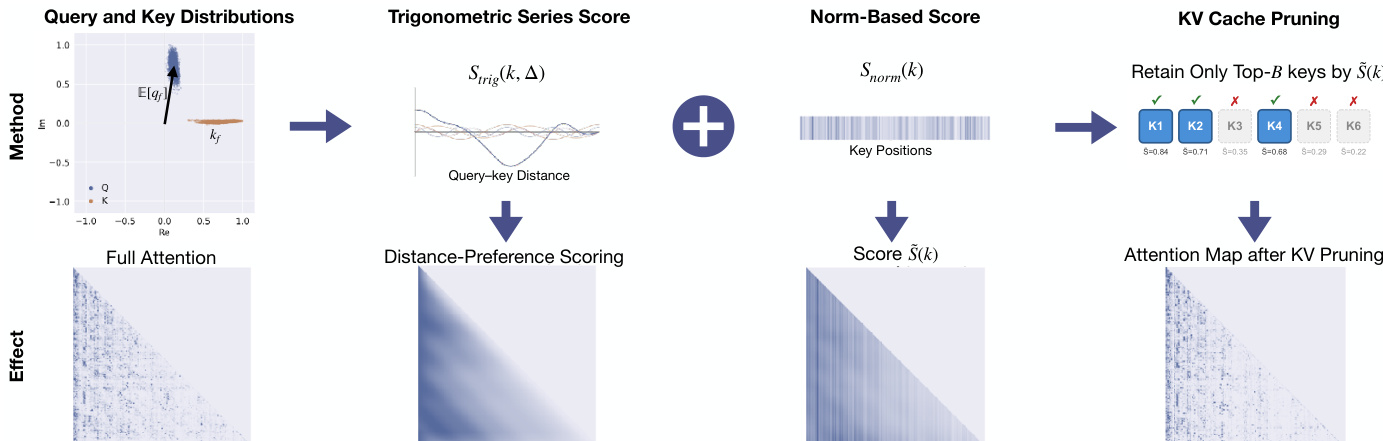
基于此分析,作者提出了 TriAttention,这是一种为剪枝计算 key 重要性得分的 KV cache 压缩方法。评分函数结合了两个组件:三角级数得分 Strig 和基于范数的得分 Snorm。三角级数得分基于距离偏好来估计 attention,使用期望 query 中心 E[qf] 作为未来 queries 的代理,并计算由向量幅度和相位差加权的余弦相似度。基于范数的得分通过使用期望 query 范数 E[∥qf∥] 和 key 幅度 ∥kf∥ 来考虑中心周围的变化。最终的组合得分是 S(k,Δ)=Strig(k,Δ)+Snorm(k)。
为了使评分适应不同程度的集中性,作者引入了一种自适应权重机制。每个频率带 f 的平均合向量长度 Rf 被用于缩放基于范数的得分。当 Rf 较高(强集中)时,减少 Snorm 的贡献,从而强调三角级数。当 Rf 较低(弱集中)时,保留完整的范数贡献。最终得分 Sfinal(k) 通过对多个未来 query 位置的得分取平均,并对 Grouped-Query Attention 应用“先归一化后聚合”的策略得出,其中来自不同 query heads 的得分经过 z-score 归一化,并通过最大值操作进行组合。
该方法采用基于窗口的剪枝实现,每生成 128 个 tokens 触发一次 key 评分和剪枝,以减少计算开销。根据最终得分保留 keys,并将前 B 个 keys 保留在 KV cache 中。整体框架如下方图所示,首先进行离线校准以计算 query 和 key 的分布中心,随后在推理过程中进行评分,最后通过保留得分最高的 keys 来生成剪枝后的 attention map。
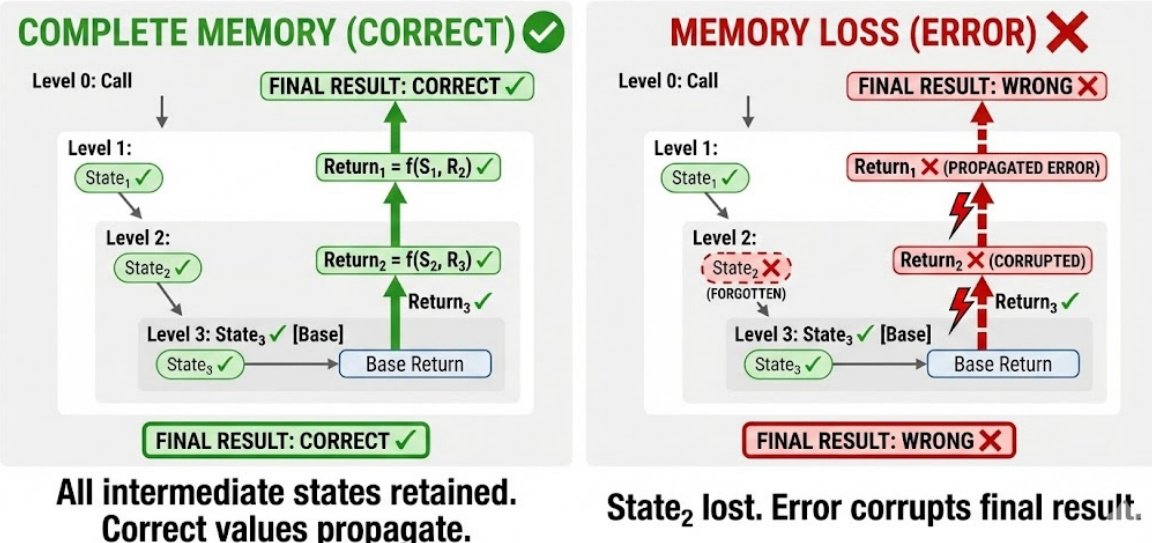
该方法的有效性通过其在递归任务中维持正确内存保留的能力得到了证明。在递归任务中,丢失中间状态会导致错误传播并损坏最终结果,如下方图所示。
实验
研究人员通过测试 TriAttention 重建 attention 模式的能力,以及其在数学推理、检索和 agentic 任务上的表现,对这种 KV cache 压缩方法进行了评估。在各种架构和基准测试上的实验表明,TriAttention 在显著提高吞吐量并减少内存占用的同时,有效地保留了长链推理和内存保留所需的核心信息。结果显示,即使在激进的压缩下,该方法也能保持与 full attention 相当的准确度,优于现有的基于观察的剪枝基线。
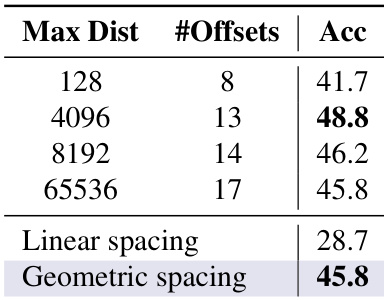
TriAttention 在保持多个基准测试准确度相当的同时,实现了相对于 Full Attention 的显著吞吐量提升。该方法表现出大幅加速,特别是在 MATH 500 上,并减少了 KV cache 内存需求,从而实现了高效的长上下文推理。在 MATH 500 上,TriAttention 的吞吐量最高可达 Full Attention 的 6.3 倍。在 AIME24 和 AIME25 上,TriAttention 在大幅减少 KV 预算的同时匹配了 Full Attention 的准确度。TriAttention 实现了高效的长上下文推理,允许在有限的 GPU 内存内成功完成任务。
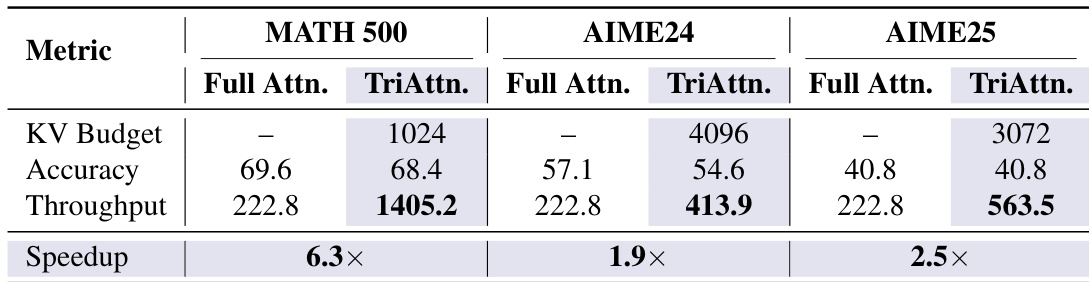
与其他压缩方法相比,TriAttention 在所有测试的 KV cache 预算下均实现了最高的准确度。它在较低的内存使用率下达到了或超过了 FullKV 的性能,展示了卓越的效率和准确度。与其他方法相比,TriAttention 在所有预算水平下都实现了最高的准确度。在较低的内存使用率下,TriAttention 匹配了 FullKV 的性能,显示出改进的效率。在不同的 KV cache 预算下,TriAttention 优于包括 H2O、TOVA 和 RaaS 在内的所有基线。
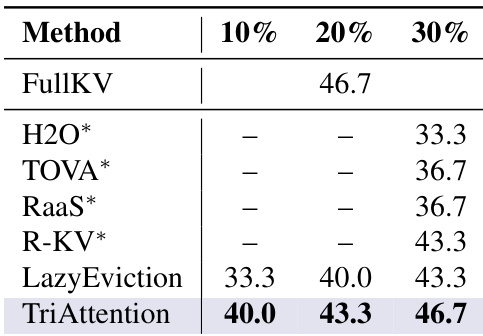
实验评估了未来偏移范围(future offset range)和间距策略对模型准确度的影响。结果表明,增加最大距离可以提高性能,而几何间距在维持准确度方面优于线性间距。增加最大距离可提高准确度;几何间距优于线性间距;准确度随偏移量数量而变化。
{"caption": "AIME performance on reasoning and coding", "summary": "该表格比较了 coding 和 reasoning 任务在 AIME24 和 AIME25 基准测试上的表现。在两个基准测试中,reasoning 任务的表现均低于 coding 任务,表明模型在不同领域的能力存在差距。", "highlights": ["在 AIME24 和 AIME25 上,reasoning 任务的得分均低于 coding 任务。", "对于 coding 和 reasoning 任务,AIME24 的表现始终高于 AIME25。", "AIME25 上 coding 与 reasoning 性能之间的差距比 AIME24 更大。"]}
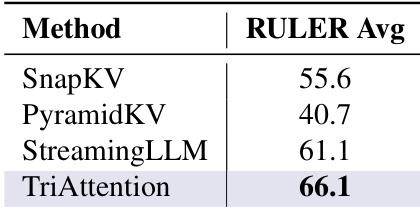
TriAttention 在 RULER 基准测试上获得了最高的平均得分,超越了其他方法。结果证明其性能优于 SnapKV 和 PyramidKV,突显了其在检索任务中的有效性。TriAttention 在所有方法中获得了最高的 RULER 平均分;TriAttention 在 RULER 上显著优于 SnapKV 和 PyramidKV;TriAttention 在 RULER 基准测试中展示了强大的检索能力。
通过在各种基准测试中进行评估,验证了 TriAttention 与 full attention 及现有压缩方法相比的吞吐量、内存效率和检索能力。结果表明,TriAttention 在保持或超过基线模型准确度的同时,显著提高了吞吐量并减少了 KV cache 需求。此外,消融研究表明,通过特定的偏移范围和几何间距策略可以优化性能。