Command Palette
Search for a command to run...
MinerU2.5-Pro:挑战大规模数据中心化文档解析的极限
MinerU2.5-Pro:挑战大规模数据中心化文档解析的极限
摘要
目前的文档解析方法主要在模型架构创新方面展开竞争,而训练数据的系统性工程化研究仍处于探索阶段。然而,不同架构和参数规模的 SOTA 模型在同一组困难样本集上表现出高度一致的错误模式,这表明性能瓶颈源于训练数据中共同存在的缺陷,而非架构本身。基于这一发现,我们提出了 minerupro。在完全保持 mineru 原有的 1.2B 参数架构不变的前提下,仅通过数据工程和训练策略优化,便实现了技术水平(state of the art)的提升。其核心是一个围绕覆盖度(coverage)、信息量(informativeness)和标注准确度(annotation accuracy)协同设计的数据引擎(Data Engine):多样性与难度感知采样(Diversity-and-Difficulty-Aware Sampling):将训练数据从不足 10M 扩展至 65.5M 个样本,并纠正了分布偏移(distribution shift);跨模型一致性验证(Cross-Model Consistency Verification):利用异构模型之间的输出一致性来评估样本难度,并生成可靠的标注;Judge-and-Refine pipeline:通过“先渲染后验证”(render-then-verify)的迭代纠错机制,提升了困难样本的标注质量。此外,我们采用了一种三阶段递进式训练策略——大规模 pre-training、困难样本 fine-tuning 以及 GRPO alignment——按不同质量梯度依次利用这些数据。在评估方面,我们修正了 OmniDocBench v1.5 中的元素匹配偏差(element-matching biases),并引入了一个“困难子集”(Hard subset),从而建立了更具区分度的 OmniDocBench v1.6 评测协议。在未进行任何架构修改的情况下,minerupro 在 OmniDocBench v1.6 上达到了 95.69 的成绩,相比相同架构的基线模型提升了 2.71 个百分点,并超越了包括参数量大其 200 倍以上的模型在内的所有现有方法。
一句话总结
通过利用包含多样性与难度感知采样(Diversity-and-Difficulty-Aware Sampling)、跨模型一致性验证(Cross-Model Consistency Verification)以及 Judge-and-Refine 流水线的 Data Engine,并结合三阶段渐进式训练策略,MinerU2.5-Pro 将训练数据从不足 10M 扩展到了 65.5M 个样本,在全新的 OmniDocBench v1.6 基准测试中取得了 95.69 的高分,同时完全保持了 MinerU2.5 1.2B 参数量的架构不变,从而推动了文档解析领域的先进水平。
核心贡献
- 本文介绍了 MinerU2.5-Pro,这是一种文档解析模型,通过专注于系统性的数据工程和训练策略优化而非架构变更,实现了最先进的性能。通过保持 1.2B 参数架构固定,该方法将 OmniDocBench v1.6 的得分提升至 95.69,超越了参数量显著更大的现有模型。
- 提出了一种专门的 Data Engine,通过多样性感知采样、用于可靠标注的跨模型一致性验证,以及用于迭代纠错的 Judge-and-Refine 流水线,将训练数据从不足 10M 扩展到 65.5M 个样本。该引擎配合三阶段渐进式训练策略,依次利用大规模预训练、困难样本微调和 GRPO 对齐,以充分利用不同质量层级的数据。
- 该工作建立了 OmniDocBench v1.6 评估协议,其中引入了多粒度自适应匹配(Multi-Granularity Adaptive Matching)以消除元素匹配偏差,并引入了专门的 Hard 子集以更好地区分模型性能。与之前的版本相比,这一更新后的基准测试提供了更具判别性的解析能力评估。
引言
文档解析通过将非结构化 PDF 转换为 Markdown 等机器可读格式,成为构建 LLM 训练流水线和检索增强生成(RAG)系统的关键组件。虽然传统研究主要集中在架构创新和推理效率上,但作者观察到,不同规模的最先进模型在相同的困难样本上表现出一致的失败模式。这表明主要的性能瓶颈不在于模型架构,而在于训练数据的共同缺陷,特别是对长尾场景覆盖不足以及复杂结构的自动标注不可靠。
作者采用以数据为中心的方法开发了 MinerU2.5-Pro,在不修改底层 1.2B 参数架构的情况下实现了显著的性能提升。他们引入了一个全面的 Data Engine,利用多样性与难度感知采样和跨模型一致性验证,将训练集从 10M 扩展到 65.5M 个样本。为了解决困难情况下的标注噪声,他们实现了一个 Judge-and-Refine 流水线,使用“先渲染后验证”机制来提高结构准确性。此外,作者贡献了 OmniDocBench v1.6,这是一个升级版的评估协议,纠正了元素匹配偏差并引入了专门的困难子集,以提供更具判别性的基准测试。
数据集
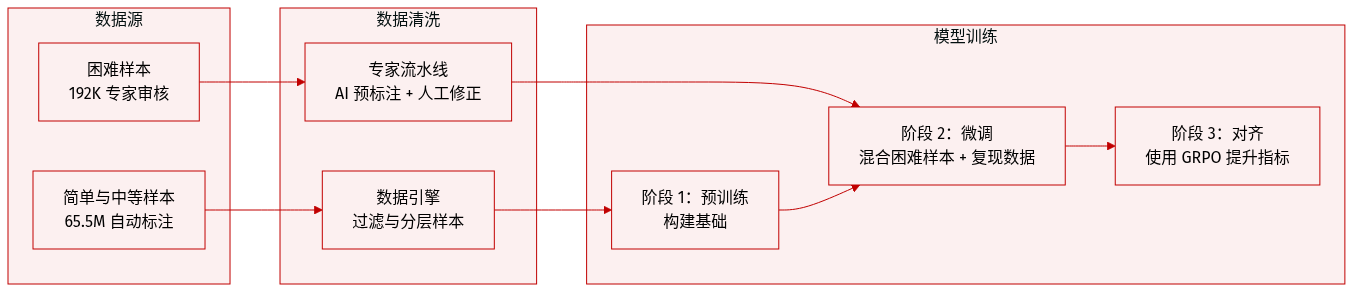
作者利用多阶段数据引擎构建了一个分层数据集,旨在用于模型的渐进式训练。数据集的构成和用法总结如下:
-
数据集构成与来源
- 简单与中等样本: 通过 Data Engine 生成的约 65.5M 个样本。这些样本使用 CMCV(多模型共识)方法进行自动标注,包括文本识别 (21M)、布局分析 (14M)、公式识别 (13M)、表格识别 (11.5M) 和图像分析 (6M)。
- 困难样本: 192K 个高质量样本,经过专门的专家标注流水线。该流水线使用 Gemini 3 Pro 进行 AI 预标注,随后由专家进行审查和修正,以确保 ground truth 的质量。
- 困难评估子集: 一个包含 296 页的独立集合,涵盖嵌套表格和密集公式等复杂场景。该子集被严格排除在所有训练阶段之外,以确保评估的公正性。
-
数据处理与过滤
- 难度分层: 作者使用 DDAS 采样和 CMCV 难度分层对样本进行分类。
- 精炼工作流: 使用 Judge-and-Refine 过程来修正标注。对于自动修正失败的样本,针对模型表现最弱的高置信度错误位置和子任务类别,优先进行专家人工标注。
- 质量保证: 采用自动化 QA 工具和标注者间交叉验证来维持标注的一致性。
-
训练策略与混合比例
- 阶段 1(预训练): 使用 65.5M 个简单和中等样本来构建基础能力。
- 阶段 2(监督微调): 通过将 192K 个专家标注的 Hard 样本与阶段 1 的回放数据(replay data)混合,专注于困难场景以防止灾难性遗忘。混合比例(Hard 对 Replay)根据子任务进行定制:布局分析 (6:1)、图像分析 (1:4)、表格识别 (1:10)、公式识别 (1:25) 和文本识别 (1:50)。
- 阶段 3(对齐): 利用专家标注的 Hard 样本进行 GRPO 对齐,以达到指标层面的性能。
方法
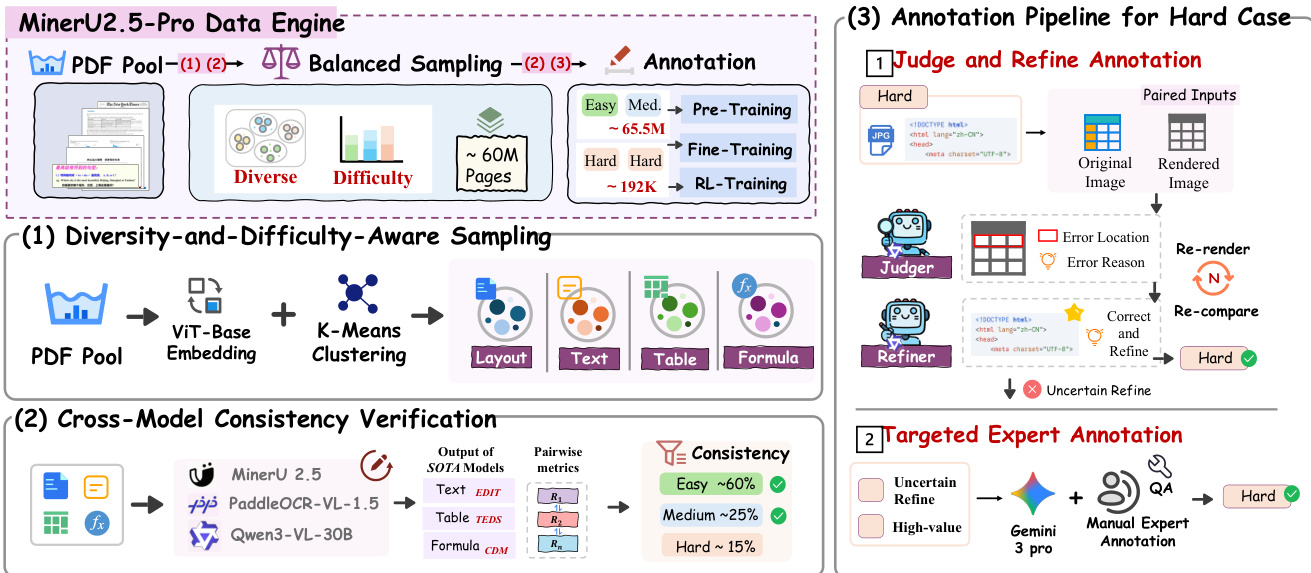
作者利用协同设计的 Data Engine,在通过闭环演进提升标注质量的同时,系统地将训练数据从不足 1000 万页扩展到 6550 万页。该框架围绕覆盖度、信息量和标注准确性三个核心维度构建,包含四个协同组件:多样性与难度感知采样 (DDAS)、跨模型一致性验证 (CMCV) 以及 Judge-and-Refine 标注流水线,超过自动修正能力的样本将被路由至专家标注。整体流水线如图所示。
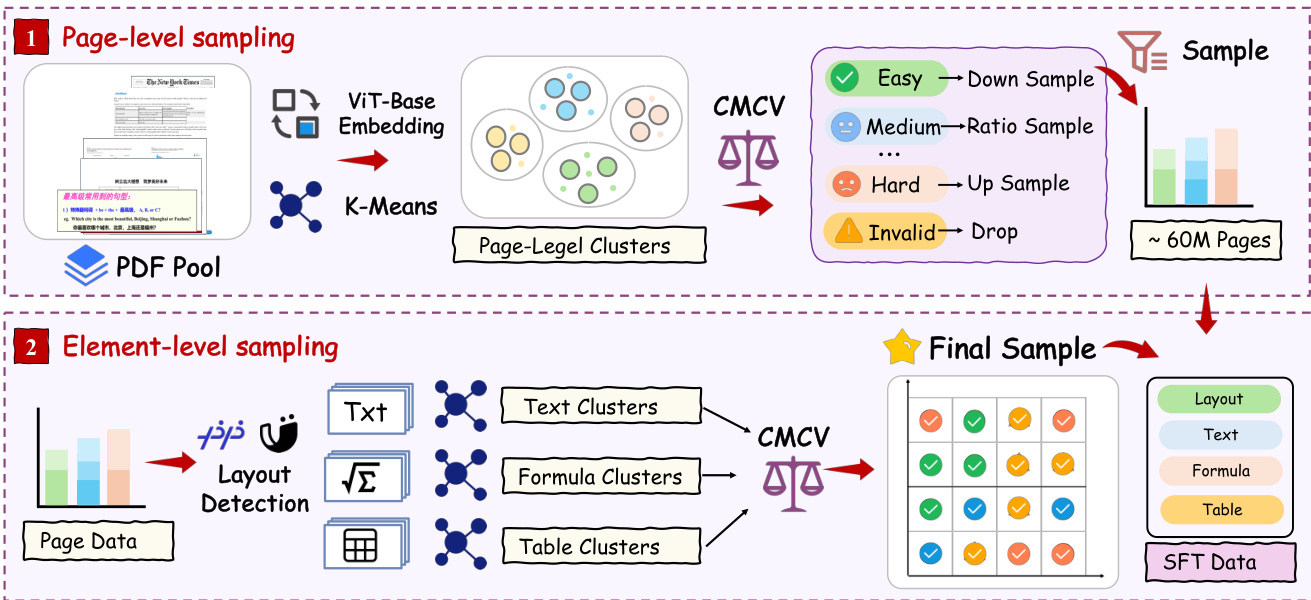
第一个组件 DDAS 在两个粒度级别运行,以平衡多样性和难度。在页面级别,通过 ViT-base 提取的视觉特征使用 K-Means 进行聚类,并在聚类中心进行均匀的初始采样。生成的候选集经过页面级 CMCV 以获取难度标签,随后用于调整采样权重:具有多样化难度分布的簇会被增加权重,而由简单或无效内容主导的簇则会被降低权重或过滤。这产生了一个具有平衡难度覆盖的页面级候选集。在元素级别,选定的页面使用布局检测模型解析为文本、公式和表格块。对于每种元素类型,进行独立的聚类,并运行块级 CMCV 以获取难度标签。最终采样通过在涵盖布局、文本、公式和表格这四个子任务的联合聚类-难度空间中进行平衡采样,将这两个级别结合起来。这一过程纠正了长尾分布偏移,并增加了中等和困难样本的权重,以增强训练信号的信息量。如下图所示,DDAS 流水线在页面级和元素级粒度上运行,两个级别结合产生所有子任务的最终训练数据。
第二个组件 CMCV 通过将难度估计从单模型内省扩展到多模型交叉验证,实现了在海量无标注数据上进行难度评估,而无需人工标注。其基本假设是:多个异构模型的一致输出表明结果正确,而显著的分歧则意味着该样本确实很困难。作者在来自 DDAS 的候选数据上运行 K 个异构 SOTA 模型(MinerU2.5、PaddleOCR-VL 和 Qwen3-VL-30B),计算特定任务的两两一致性指标:文本的编辑距离、表格的 TEDS 和公式的 CDM。样本根据一致性模式被分为三个难度层级:Easy(MinerU2.5 的输出与至少一个外部模型一致)、Medium(外部模型达成一致但 MinerU2.5 不同)和 Hard(所有模型都不一致)。这种区分对于标注策略的设计至关重要,因为 Easy 数据构成了基础,Medium 数据指出了模型的能力差距,而 Hard 数据则需要进一步精炼或专家标注。CMCV 过程如下图所示,展示了从模型输出到一致性指标及难度分类的流程。

第三个组件 Judge-and-Refine 标注流水线通过“先渲染后验证”的迭代修正过程,提高了困难样本的标注准确性。对于困难样本,将原始图像渲染为高保真版本,然后将其与模型的输出进行比较以识别错误。随后根据识别出的错误位置和原因对模型进行精炼。如果精炼成功,样本将被标记为正确并完成精炼;否则,它将被路由到定向的专家标注。该过程如下图所示,展示了从配对输入到 judge 和 refiner,以及迭代修正过程的流程。

作者还引入了与 Data Engine 产生的数据质量层级相匹配的三阶段渐进式训练策略。模型从 MinerU2.5 的 Stage 0 检查点初始化,在 CMCV 自动标注数据上进行大规模预训练以构建基础能力。随后在专家标注的困难样本上进行高质量微调,以强化在挑战性场景下的性能。最后阶段通过使用 Group Relative Policy Optimization (GRPO) 的强化学习来对齐输出格式和结构规范。该阶段通过对 G 组候选输出进行采样,根据这些指标计算奖励,并使用组内相对优势更新策略,从而直接优化任务级指标:文本的编辑距离、公式的 CDM、表格的 TEDS 以及布局检测的类别 IoU。训练数据由 Stage 2 模型的 rollout 生成,并通过过滤保留中等奖励样本,以确保可靠的 policy gradients。训练配置总结在表 1 中。作者还提出了多粒度自适应匹配 (MGAM),通过在预测端自适应调整分割粒度来消除评估中的匹配偏差,确保更公平且更具判别性的评估。整体框架和关键组件如下图所示。
实验
实验使用包含标准和挑战子集的 OmniDocBench v1.6 基准测试,将 MinerU2.5-Pro 与专门的文档解析模型和通用 VLM 进行对比评估。结果表明,所提出的数据引擎和渐进式训练策略显著增强了在复杂场景下的鲁棒性,特别是在表格、公式和阅读顺序识别方面。该模型在端到端解析和特定元素任务中取得了卓越的性能,在保持对旋转表格和多行公式等困难结构元素的高准确性的同时,超越了更大的通用模型。
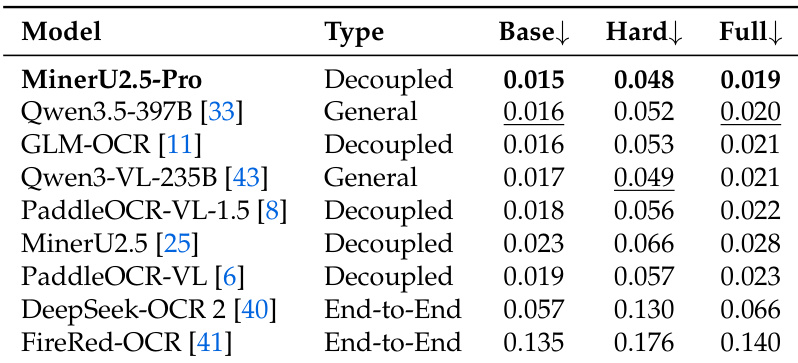
作者使用编辑距离指标,在 OmniDocBench v1.6 的 Base、Hard 和 Full 子集上比较了多个模型的文本识别性能。结果显示,MinerU2.5-Pro 在 Base 子集上表现最佳,而像 Qwen3.5-397B 这样的通用模型表现具有竞争力,端到端模型的性能则显著较低。MinerU2.5-Pro 在 Base 子集上实现了最佳文本识别性能。通用模型表现出竞争力的性能,而端到端模型的表现明显较差。性能在不同子集之间差异显著,与 Base 子集相比,Hard 和 Full 子集的错误率更高。
作者在 OmniDocBench v1.6 上使用三层评估协议,将 MinerU2.5-Pro 与通用 VLM 和专门的文档解析模型进行评估。结果显示,MinerU2.5-Pro 在 Full 和 Hard 子集上取得了顶尖性能,证明了其相对于基线的显著改进以及在挑战性场景下的强大鲁棒性。MinerU2.5-Pro 在 Hard 子集上领先,表现出优于其他模型的鲁棒性。该模型在公式和表格识别方面取得了最佳分数,特别是在复杂和困难场景下。相对于基线的性能提升归功于数据工程和训练策略优化,而非模型架构的改变。

作者在 OmniDocBench v1.6 的多个子集和基准测试上评估了 MinerU2.5-Pro 和其他模型。结果显示,MinerU2.5-Pro 在多项任务中取得了顶尖性能,特别是在公式和表格识别方面,同时与其他模型相比,在困难场景上也表现出强大的鲁棒性。MinerU2.5-Pro 在包括 CPE 和 SPC 在内的多个基准测试中获得了最高分,表明其在公式识别方面具有强大性能。MinerU2.5-Pro 在困难子集上表现出优异的鲁棒性,与其他出现显著下降的模型相比,保持了高性能。该模型在表格识别方面表现出色,在 Base 和 Hard 子集上均获得了最高分,超越了专门模型和通用模型。
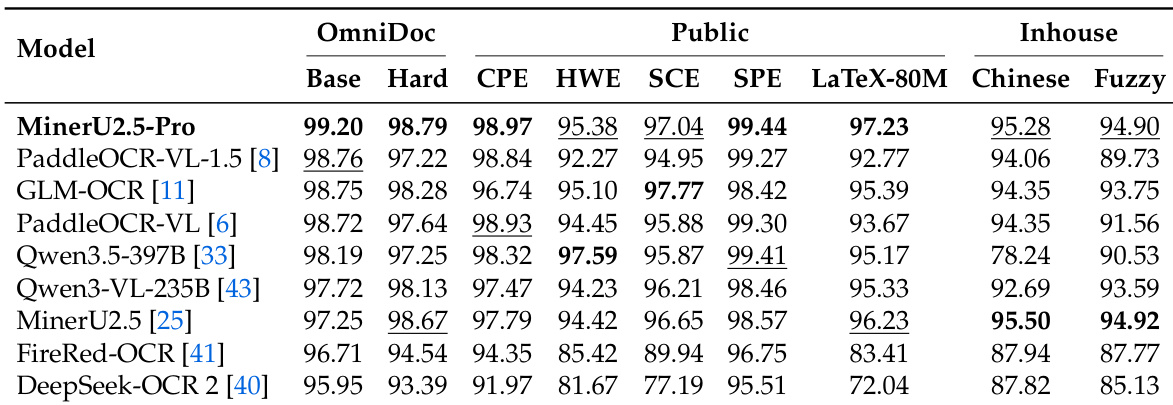
作者使用三层协议在 OmniDocBench v1.6 上评估 MinerU2.5-Pro,并将其与通用 VLM 和专门的文档解析模型进行比较。结果显示,MinerU2.5-Pro 在 Full 和 Hard 子集上取得了顶尖性能,在公式和表格识别方面展示了强大的鲁棒性和极具竞争力的准确性。渐进式训练策略对性能有增量贡献,每个阶段都在改进特定的子指标。MinerU2.5-Pro 在 Full 和 Hard 子集上取得了顶尖性能,展示了在挑战性场景下的强大鲁棒性。该模型在公式和表格识别方面表现出色,在关键子指标上较基线有显著改进。每个训练阶段都对性能做出增量贡献,其中 Data Engine 和强化学习在提高准确性方面发挥了关键作用。
作者在 OmniDocBench v1.6 上使用包含 Base、Hard 和 Full 子集的三层协议,将 MinerU2.5-Pro 与各种文档解析模型和通用 VLM 进行评估。结果显示,MinerU2.5-Pro 获得了最高的总分,并在多个子指标中领先,特别是在公式和表格识别方面,证明了在标准和挑战性场景下的强大性能。MinerU2.5-Pro 获得了最高的总分,并在公式和表格识别指标中领先。该模型在 Hard 子集上表现强劲,超越了多个专门模型。MinerU2.5-Pro 展示了鲁棒性,与其它模型相比,从 Base 到 Hard 的性能下降幅度更小。
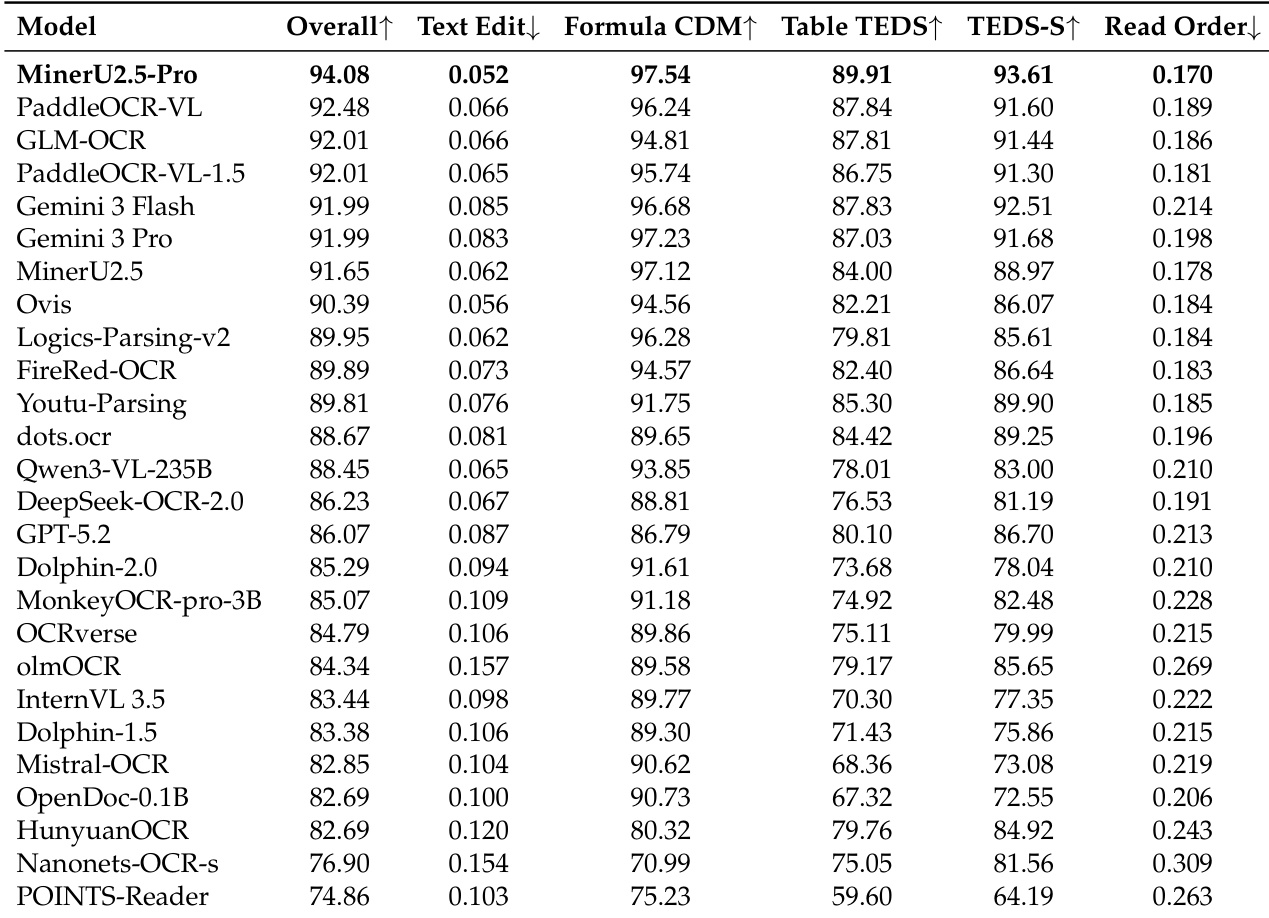
作者使用多层级的 OmniDocBench v1.6 基准测试,将 MinerU2.5-Pro 与通用 VLM 和专门的文档解析模型进行对比。实验验证了该模型在不同难度水平下的文本识别、公式和表格解析能力。结果表明,与其他模型相比,MinerU2.5-Pro 取得了更优越的性能,并在挑战性场景下保持了更高的鲁棒性。这些改进主要归功于优化的数据工程和渐进式训练策略,而非模型架构的改变。