Command Palette
Search for a command to run...
OpenWorldLib:一种统一的代码库与高级 World Models 的定义
OpenWorldLib:一种统一的代码库与高级 World Models 的定义
摘要
世界模型(World models)作为人工智能领域一个极具前景的研究方向,已引起了广泛关注,然而目前仍缺乏一个清晰且统一的定义。在本文中,我们推出了 OpenWorldLib,这是一个针对高级世界模型(Advanced World Models)的全面且标准化的 inference 框架。结合世界模型的发展演变,我们提出了一个明确的定义:世界模型是一种以感知为核心,并具备交互与长期记忆能力,旨在理解和预测复杂世界的模型或框架。此外,我们还对世界模型的核心能力进行了系统性的分类。基于这一定义,OpenWorldLib 在统一的框架内集成了不同任务的模型,从而实现了高效的复用与协同 inference。最后,我们对世界模型研究的潜在未来方向提出了进一步的思考与分析。代码链接:https://github.com/OpenDCAI/OpenWorldLib
一句话总结
来自北京大学、快手科技等机构的研究人员提出了 OpenWorldLib,这是一个标准化的推理框架。通过整合交互式视频生成、3D 生成、多模态推理和视觉-语言-动作(VLA)生成等多种任务中的感知、交互和长期记忆能力,该框架为先进的世界模型建立了统一的定义。
核心贡献
- 本论文为世界模型建立了正式定义,将其视为以感知为中心,并具备交互和长期记忆能力的框架,用于理解和预测复杂环境。
- 该工作引入了 OpenWorldLib,这是一个标准化的推理框架,它整合了跨多个任务的多种模型,以实现高效的复用和协作推理。
- 该框架为包括交互式视频生成、3D 场景重建、音频生成和视觉-语言-动作(VLA)推理在内的核心任务提供了统一接口,从而标准化了多模态输入和交互控制。
引言
随着人工智能从虚拟环境向现实世界应用转型,世界模型已成为使 Agent 能够感知、交互并理解物理动态的关键。然而,该领域目前面临缺乏共识的问题,研究人员经常使用多样且重叠的定义,将文本到视频等通用生成任务与真正的世界建模混为一谈。为了解决这种碎片化问题,作者提出了一个以感知、动作条件模拟和长期记忆为中心的世界模型标准化定义。他们利用这一定义引入了 OpenWorldLib,这是一个统一的推理框架,将包括交互式视频生成、3D 场景重建、多模态推理和视觉-语言-动作(VLA)模型在内的多种能力整合到一个连贯的代码库中。
数据集
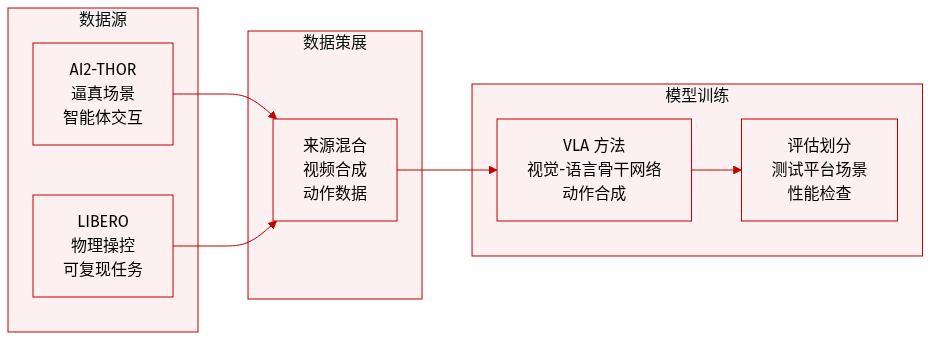
作者在 OpenWorldLib 中利用两种不同的基于模拟的范式,来评估世界模型在具身视频合成和动作生成方面的性能:
-
数据集组成与来源
- AI2-THOR: 用于具身视频生成,以促进逼真的场景渲染和动态的 agent 与环境之间的交互。
- LIBERO: 用于视觉-语言-动作(VLA)评估,提供具有物理依据且可复现的操作环境。
-
数据使用与评估框架
- 这些数据集作为可控测试平台,用于评估世界模型将语义理解与物理动态及细粒度动作规划相结合的能力。
- 该框架评估了多种 VLA 方法,包括 π0 和 π0.5(使用带有 MoE 动作头的 PaliGemma 主干网络)以及 LingBot-VA(采用视频扩散架构进行视觉预测和连续动作合成)。
方法
OpenWorldLib 框架旨在解决世界模型的核心需求,包括接收复杂的物理输入、理解环境、维持长期记忆以及支持多模态输出。该框架围绕模块化架构构建,通过整合不同的组件来实现连贯且可扩展的世界模型交互。如框架图所示,系统从环境交互信号开始,通过中心化流水线进行处理以生成多模态输出。
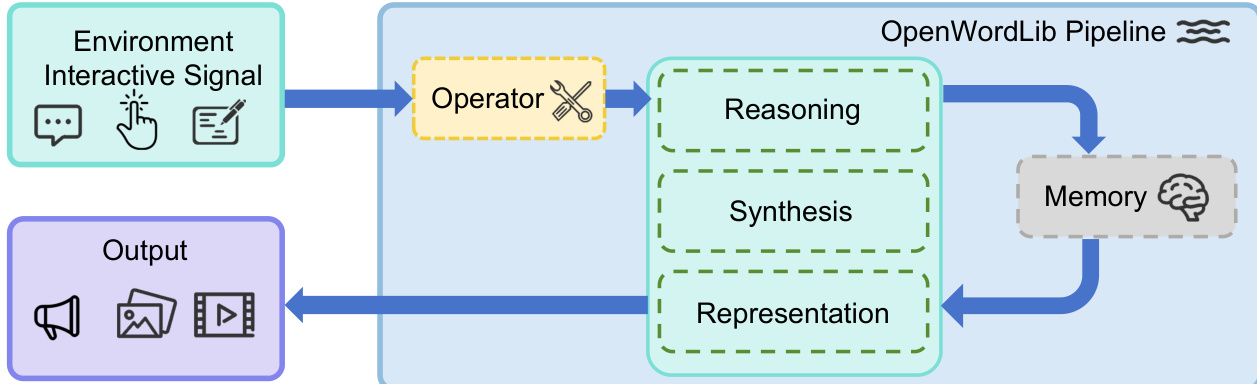
Operator 模块作为原始用户或环境输入与核心处理模块之间的初始接口。它通过执行两个主要功能:验证和预处理,来标准化多样化的数据流,例如文本提示、图像、连续控制动作和音频信号。验证确保输入数据符合预期的格式、形状和类型,而预处理将原始信号转换为标准化的 tensor 表示或结构化格式。为了支持扩展性,定义了一个统一的 BaseOperator 模板,确保所有特定任务的 operator 都能实现一致的 API 集成。
核心处理逻辑由 Pipeline 模块管理,该模块编排 Operator、Reasoning、Synthesis、Representation 和 Memory 模块之间的交互。Pipeline 为单轮推理和多轮交互执行提供了统一的入口点。它接收原始输入,通过 Operator 进行预处理,查询 Memory 模块获取上下文历史,协调 Reasoning、Synthesis 和 Representation 模块的执行,并在更新记忆状态的同时返回结构化输出。这种设计实现了高效的数据流,并在保持可靠通信的同时实现了模块实现的解耦。
Reasoning 模块使系统能够解释多模态输入并生成有依据的语义解释。它分为三个子类别:通用推理、空间推理和音频推理。通用推理使用多模态大语言模型来处理文本、图像、音频和视频,而空间推理专注于 3D 空间理解和物体定位。音频推理则解释听觉信号。统一的 BaseReasoning 模板确保了新推理模型能够一致地集成到框架中。
Synthesis 模块充当标准化条件与多模态输出(包括视觉、听觉和具身信号)之间的生成桥梁。它托管了异构的生成后端,用于产生结构化产物,如图像、视频帧和音频波形。视觉合成层根据文本提示或参考图像等结构化条件生成光栅化输出,支持本地和基于云端的推理。音频合成层根据文本、视频特征和时间元数据生成连续波形,实现丰富的听觉反馈。其他信号合成层专注于物理信号生成,特别是动作控制,将多模态上下文映射为具身任务的可执行动作序列。
Representation 模块处理显式表示(如 3D 结构),这与 Synthesis 生成的隐式表示是分开的。它支持 3D 重建以产生点云、深度图和相机姿态等输出,并为在坐标系中测试预测动作提供模拟支持。它还通过本地或基于云端的 API 与外部物理引擎集成。
Memory 模块作为持久化状态中心,存储多模态交互历史(包括文本、视觉特征、动作轨迹和场景状态),并为多轮任务实现高效的上下文检索。它管理历史存储、上下文检索、状态更新和会话管理,确保跨交互的一致推理和生成。

如下图所示,该框架区分了隐式表示和显式表示。在隐式表示路径中,模型处理交互信号并直接生成输出;而在显式表示路径中,则涉及一个模拟器,该模拟器基于结构化表示来渲染输出。这种双重方法使框架能够同时支持学习到的动力学模型和人类定义的模拟器,为世界模型的测试和验证提供了一个全面的环境。
实验
评估通过包括交互式视频生成、多模态推理、3D 生成和视觉-语言-动作生成在内的任务来考察 OpenWorldLib 框架。结果表明,虽然早期的导航模型在长时程任务中难以保持颜色一致性,但较新的方法实现了更高的视觉质量。此外,实验证明,虽然某些模型支持基础的交互性,但它们往往缺乏先进生成架构中所具备的物理一致性和真实感。