Command Palette
Search for a command to run...
InCoder-32B-Thinking:面向推理的工业级代码世界模型
InCoder-32B-Thinking:面向推理的工业级代码世界模型
摘要
在芯片设计、GPU 优化及嵌入式系统等领域的工业软件开发中,目前尚缺乏能够展示工程师如何推理硬件约束与时序语义的专家级推理轨迹。为此,我们提出了 InCoder-32B-Thinking 模型。该模型基于错误驱动思维链(Error-driven Chain-of-Thought, ECoT)合成框架进行训练,并引入工业代码世界模型(Industrial Code World Model, ICWM)以生成高质量的推理轨迹。具体而言,ECoT 通过结合多轮对话中的思考内容与来自环境反馈的错误信息,合成推理链条,并显式地对错误修正过程进行建模。ICWM 则基于 Verilog 仿真、GPU 性能分析等特定领域的执行轨迹进行训练,学习代码如何影响硬件行为的因果动态机制,并能够在实际编译之前预测执行结果,从而实现自我验证。所有合成的推理轨迹均通过领域工具链进行验证,从而构建出与工业任务自然推理深度分布相匹配的训练数据。在 14 项通用基准测试(在 LiveCodeBench v5 上达到 81.3%)和 9 项工业基准测试(在 CAD-Coder 上达到 84.0%,在 KernelBench 上达到 38.0%)的评估中,InCoder-32B-Thinking 在所有领域均取得了开源模型中的顶尖性能。
一句话总结
北京航空航天大学与 IQest 研究院的研究人员推出了 InCoder-32B-Thinking,该模型利用误差驱动的思维链(Error-driven Chain-of-Thought)和工业代码世界模型,生成用于芯片设计和 GPU 优化的专家级推理轨迹,在通用及专用工业基准测试中均取得了顶尖性能。
主要贡献
- 本文提出了误差驱动思维链(ECoT)合成框架,该框架通过对比错误尝试与环境反馈同正确解决方案,显式建模纠错过程,从而生成推理轨迹,以捕捉迭代式的工程优化模式。
- 本研究开发了一个工业代码世界模型,该模型基于 Verilog 仿真和 GPU 性能分析中的领域特定执行轨迹进行训练,学习代码与硬件行为之间的因果动态,从而无需昂贵的工具链执行即可实现自我验证和合成轨迹生成。
- 最终生成的 InCoder-32B-Thinking 模型将 ECoT 合成的推理与世界模型预测相结合,在 14 个通用基准和 9 个工业基准测试中取得了顶尖的开源结果,包括在 LiveCodeBench v5 上达到 81.3%,在 CAD-Coder 上达到 84.0%。
引言
在芯片设计、GPU 优化和嵌入式系统等领域的工业软件开发中,工程师需要深入推理硬件约束和时序语义,然而现有数据集缺乏教导大语言模型(LLM)掌握这些复杂技能所需的专家级推理轨迹。先前的方法往往专注于孤立的子领域,或依赖无法捕捉工业工具链特有动态的通用网络规模语料库,导致在 Verilog 调试或 CUDA 内核优化等任务上成效有限。为此,作者推出了 InCoder-32B-Thinking,该模型结合了误差驱动思维链合成框架与新颖的工业代码世界模型,利用模拟硬件反馈来生成和验证推理轨迹。
数据集
-
数据集构成与来源 作者复用了 InCoder-32B 的核心数据,包括查询、单元测试和执行环境。他们将每个任务种子与其特定的环境上下文打包,创建完全指定且可复现的执行对。对于 Verilog 任务,模块与测试平台和 Yosys 综合脚本捆绑在一起;而 STM32 固件片段则与内存布局、CMSIS 头文件和链接脚本耦合。
-
各子集的关键细节
- 通用代码基准:该套件涵盖代码生成、推理、效率、文本转 SQL、智能体编程和工具使用,使用的数据集包括 EvalPlus、BigCodeBench、FullStackBench、CRUXEval、LiveCodeBench、Mercury、Spider、BIRD、Terminal-Bench、SWE-bench Verified、Mind2Web、BFCL V3 以及 τ2-bench。
- 工业代码基准:这些基准专注于硬件和工程密集型任务。芯片设计基准包括 VeriScope(568 个问题)、RealBench(60 个模块级和 4 个系统级子任务)、ArchXBench(51 个设计)以及新构建的 VeriRepair(约 22,000 个训练样本和 300 个测试样本)。GPU 优化使用 KernelBench(250 个 PyTorch 工作负载)和 TritonBench(184 个真实世界算子)。代码优化依赖 EmbedCGen(500 个嵌入式 C 问题)和 SuperCoder(8,072 个汇编程序)。3D 建模利用 CAD-Coder,该数据集源自 Text2CAD,包含 11 万个三元组。
-
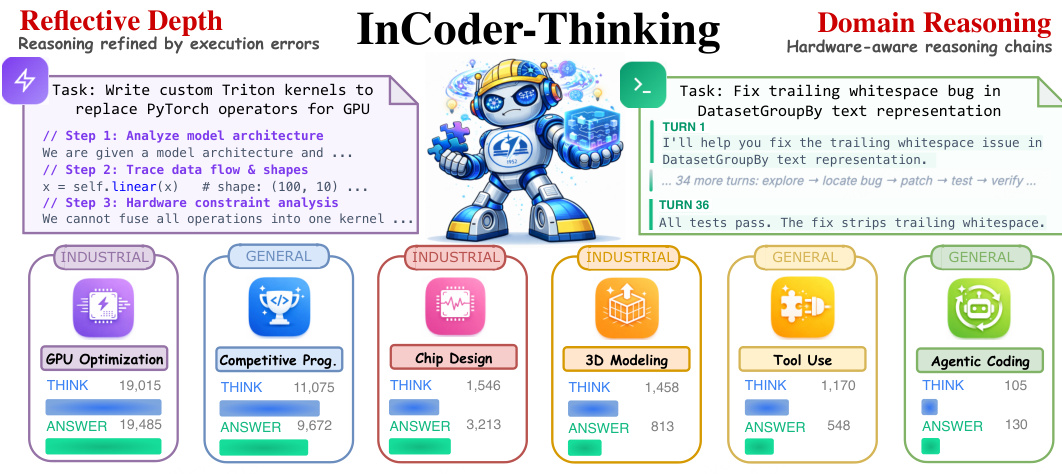
模型使用与训练策略 训练语料库是通过误差驱动合成管道生成的,该管道基于真实或模拟的执行反馈创建推理轨迹,而非固定模板。这一过程自然产生了广泛的思维深度谱系,从智能体编程的 91 个字符到 GPU 内核优化的 19,015 个字符不等。模型学习自适应地校准其推理投入,为复杂的工业后端投入深度的多步思考,而对于反馈循环短的任务则保持轨迹简洁。
-
处理与元数据构建 作者构建了任务 - 环境对 ⟨stask,senv⟩,以确保每个下游步骤都有明确的上下文。验证管道是领域特定的,范围从 Verilog 的仿真和编译检查到嵌入式 C 的交叉编译和系统级仿真。对于 VeriRepair 等基准,元数据包括错误代码、错误类别、位置、修正参考和测试平台。在 CAD-Coder 中,数据按质量分层为高、中、难案例,部分样本标注了思维链推理。
方法
作者针对多样化的工业编码领域,从 GPU 优化和芯片设计到 3D 建模和智能体编程,如概念概览图所示。
为了应对这些任务的复杂性,作者利用了一个两阶段数据引擎管道,旨在合成误差驱动的思维轨迹。该管道在下方的框架图中详细说明,概述了从任务种子到分布式执行和模型训练的整个流程。
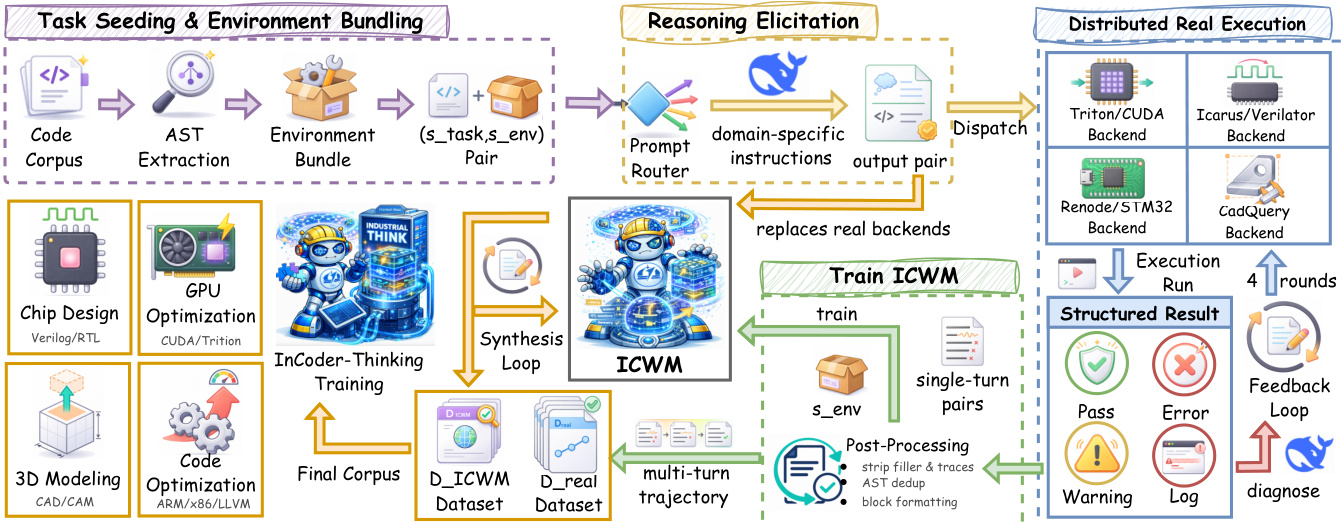
在第一阶段(基于基础的收集),作者从任务种子和环境捆绑开始。代码语料库经过处理以提取抽象语法树(AST),并与特定的环境配置捆绑。这些对被传递给推理激发模块,其中轻量级提示路由器选择特定领域的指令。例如,GPU 内核任务需要推理关于线程束发散(warp divergence)的问题,而 RTL 任务则关注组合路径深度。生成器随后生成初始的推理内容和代码对。
该候选代码被发送到分布式真实执行后端,如 Triton/CUDA、Renode 或 CadQuery。每个后端返回一个包含结果标签和诊断日志的结构化结果。当执行产生错误时,反馈被打包为观察值并反馈给生成器以进行修订。此循环最多迭代 K 次修正轮次,生成多轮轨迹 τ,捕捉解决失败所需的推理步骤。
为了扩展此过程,第二阶段采用 ICWM 驱动的数据放大。收集到的真实轨迹用于训练工业代码世界模型(ICWM),该模型作为执行后端的已学习代理。ICWM 接收环境捆绑 senv 和候选程序 c(k) 作为输入,以预测可观察反馈 o^(k)。训练完成后,ICWM 在反馈循环中取代真实后端,从而在无需重复真实执行带来的计算成本的情况下实现大规模轨迹合成。最终的训练语料库结合了真实执行和 ICWM 模拟的数据。
实验
- 通用和工业代码基准测试验证了 InCoder-32B-Thinking 实现了卓越的代码推理能力,在芯片设计和 GPU 优化方面优于更大的开源权重模型和专有系统,同时在通用生成任务中保持竞争力。
- 保真度分析证实,工业代码世界模型可以可靠地替代真实执行后端以进行大规模轨迹合成,在预测结果方面具有高准确性,并在多轮纠错序列中保持一致性。
- 扩展实验表明,将思维训练数据从 1.8 亿 token 增加到 5.4 亿 token 持续增强了深度推理能力和工业编码技能,尽管某些复杂的优化任务可能需要超越单纯数据量的针对性策略。
- 总体结论表明,将误差驱动思维链合成与特定领域世界模型相结合,有效地弥合了通用编程能力与硬件感知工业软件开发严格要求之间的差距。