Command Palette
Search for a command to run...
自蒸馏的 RLVR
自蒸馏的 RLVR
Chenxu Yang Chuanyu Qin Qingyi Si Minghui Chen Naibin Gu Dingyu Yao Zheng Lin Weiping Wang Jiaqi Wang Nan Duan
摘要
在线策略蒸馏(On-policy Distillation, OPD)已成为大语言模型(LLM)社区中一种流行的训练范式。该范式选取一个更大规模的模型作为教师,为每条采样轨迹提供稠密且细粒度的信号;相比之下,基于可验证奖励的强化学习(RLVR)仅能从环境中的可验证结果获取稀疏信号。近期,学界开始探索在线策略自蒸馏(On-policy Self-Distillation, OPSD),即同一模型同时充当教师与学生角色,其中教师接收参考答案等额外的特权信息(privileged information),以驱动模型的自我演进。本文指出,若学习信号完全源自具备特权信息的教师,将导致严重的信息泄露,并引发长期训练的不稳定性。为此,我们明确了自蒸馏的最佳适用场景,并提出 RLSD(RLVR with Self-Distillation)。具体而言,RLSD 利用自蒸馏获取 token 级别的策略差异,以此确定细粒度的更新幅度;同时,继续借助 RLVR 从环境反馈(如响应正确性)中推导可靠的更新方向。该方法使 RLSD 能够同时融合 RLVR 与 OPSD 的优势,从而实现更高的收敛上限与更优越的训练稳定性。
一句话总结
中国科学院与京东的研究人员提出了 RLSD,这是一种新颖的训练范式,它将可验证奖励强化学习(RLVR)与自蒸馏相结合,在保持来自环境反馈的可靠方向的同时,确定细粒度的更新幅度。该方法克服了先前方法中的信息泄露问题,实现了大语言模型(LLM)后训练过程中更优的稳定性和更快的收敛速度。
主要贡献
- 本文提出了 RLSD,这是一种训练范式,它通过利用环境反馈确定可靠的更新方向,同时利用特权教师(privileged teacher)的 token 级策略差异来调节更新幅度,从而将 RLVR 与自蒸馏相结合。
- 本文提供了理论证明,表明在线策略自蒸馏中的信息不对称会产生不可约的互信息间隙,解释了为何仅依赖特权教师信号会导致信息泄露以及长期训练的不稳定。
- 在推理任务上的实验结果表明,与标准 RLVR 相比,所提出的方法实现了更高的收敛上限和更优的稳定性,其性能水平超过了训练步数为其两倍的基线模型。
引言
大型推理模型越来越依赖可验证奖励强化学习(RLVR)来针对可验证的结果进行优化,然而这种方法受限于稀疏的序列级信号,无法区分关键的推理步骤与填充 token。虽然在线策略自蒸馏(OPSD)试图通过使用模型自身的特权输出作为密集训练信号来解决这一问题,但它引入了致命的信息不对称:学生模型学会了泄露其在推理阶段无法访问的参考答案,导致性能在初期提升后出现退化。作者通过提出 RLSD 解决了这一问题,该范式将更新方向与更新幅度解耦:将梯度方向锚定在可靠的环境奖励上,而仅使用自蒸馏来调节 token 级更新的细粒度强度。
数据集
-
数据集构成与来源:作者在 MMFineReason-123K 上训练模型,这是从更大的 MMFineReason-1.8M 语料库中提取的一个具有挑战性的子集。该数据集专注于需要视觉感知和领域知识的多模态推理问题。
-
关键细节与过滤规则:该子集是基于难度过滤策略创建的。作者使用 Qwen3-VL-4B-Thinking 对原始语料库中的每个样本进行推理,并执行四次独立的 rollout。仅保留模型在四次尝试中全部失败的样本。这种保守的方法丢弃了简单的示例,将训练信号集中在困难问题上。
-
训练中的使用:过滤后的数据集作为 Qwen3-VL-8B-Instruct 基础模型的主要训练数据。训练设置使用批量大小为 256,每个提示采样 8 次 rollout,温度为 1.0。最大上下文长度设置为 8192,其中提示和响应各占 4096 个 token,平均分配。
-
处理与特权信息:与需要验证的推理轨迹或成功的 rollout 作为特权上下文的其他方法不同,该方法仅需最终的真实答案。教师模型参数每 10 个训练步与student模型同步一次,以维持稳定的自蒸馏信号。评估阶段利用五个不同的基准测试,包括 MMMU、MathVista、MathVision、ZeroBench 和 WeMath,以评估模型在多样数学和通用推理能力上的表现。
方法
作者提出了带有自蒸馏的强化学习(RLSD),以解决标准分布匹配方法(如在线策略自蒸馏 OPSD)的局限性。RLSD 不再将教师模型视为行为克隆的生成目标,而是重新利用教师与学生分布之间的差异,作为策略梯度框架内的 token 级信用分配信号。这种方法允许模型利用特权信息(如参考解)来细化更新幅度,同时不损害优化方向,后者仍锚定于环境的可验证奖励。
RLSD 的核心机制通过三步过程从序列级优势 A 构建 token 级优势 A^t。首先,该方法计算每个 token 位置 t 的特权信息增益 Δt。这被定义为在教师上下文(以问题 x 和特权信息 r 为条件)下该 token 的对数概率与在仅以 x 为条件的学生上下文下的对数概率之间的停止梯度差:
Δt=sg(logPT(yt)−logPS(yt)).该指标隔离了特权信息对学生生成的特定 token 预测的边际贡献。正的 Δt 表示特权信息支持该 token,而负值则表示其不支持。
其次,该方法执行方向感知的证据重加权。作者通过指数化特权信息增益,并结合序列级优势 A 的符号,构建每个 token 的权重 wt:
wt=exp(sign(A)⋅Δt)=(PS(yt)PT(yt))sign(A).该公式确保环境奖励对更新方向(强化与惩罚)拥有独家决定权,而教师的评估则调节轨迹内各 token 之间的相对信用幅度。当 A>0 时,受特权信息支持的 token 获得更高权重;当 A<0 时,受特权信息排斥的 token 承担更多责任。
参考下方的框架图,以直观了解序列级优势与 token 级权重如何结合生成最终的 token 级优势。
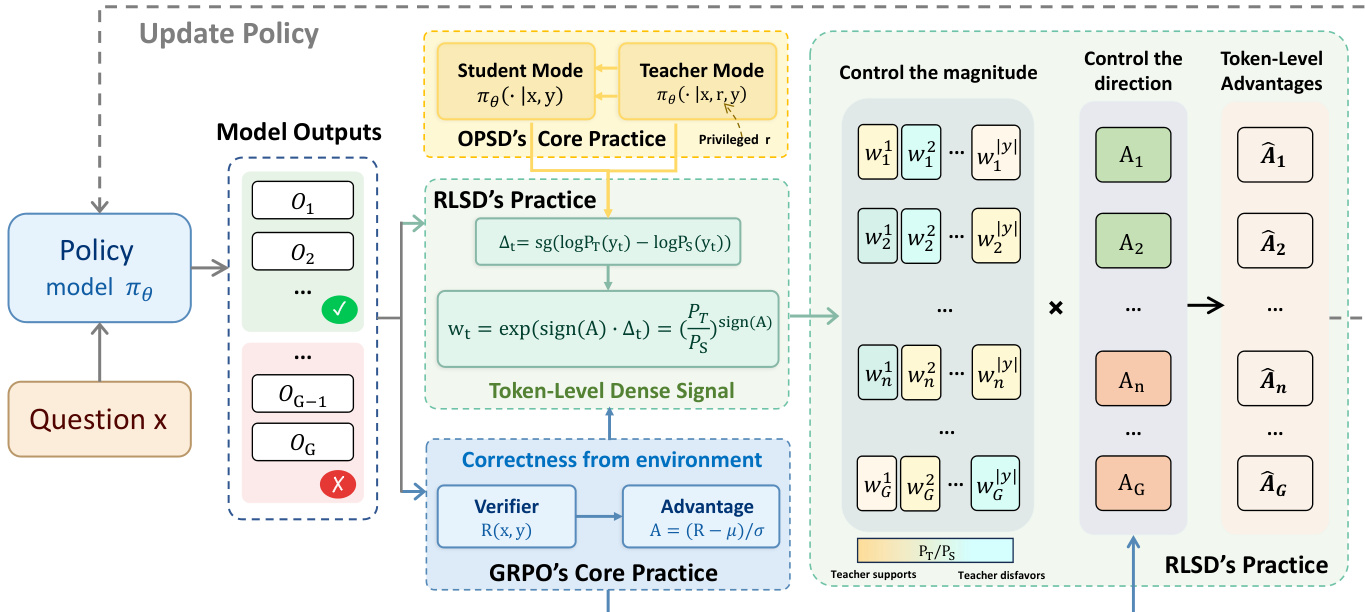
最后,为确保训练稳定性,证据权重被裁剪以限制单个 token 的最大影响,类似于 PPO 和 GRPO 中的信任区域约束。最终的 token 级优势 A^t 计算如下:
A^t=A⋅clip(wt, 1−ϵw, 1+ϵw).训练过程遵循标准的组相对策略优化(GRPO)流程,但使用此修改后的优势。对于每个问题 x,策略模型采样一组 G 个响应。验证器为每个响应提供二元奖励,据此计算组相对序列级优势 A。随后,模型使用特权信息 r 进行额外的前向传播,以计算教师 logits 并推导出 token 级权重 wt。策略参数 θ 通过最大化使用重加权优势 A^t 的目标函数进行更新:
LRLSD(θ)=E⎩⎨⎧G1i=1∑G∣y(i)∣1t=1∑∣y(i)∣min[wtA(i),clip(wt,1−ϵw,1+ϵw)A(i)]⎭⎬⎫.该设计使 RLSD 能够作为 GRPO 中均匀优势的即插即用替代品,提供密集的 token 级指导,而无需引入辅助蒸馏损失或依赖外部教师模型。
实验
- 实证观察表明,OPSD 训练的模型逐渐泄露推理阶段不可用的特权信息,导致性能下降,且 KL 散度停滞不前,这表明存在一个不可约的间隙,阻碍了有意义的收敛。
- 主要结果表明,RLSD 通过利用密集的 token 级信用分配,在多模态推理基准测试中优于包括 GRPO、OPSD 和 SDPO 在内的基线方法,在复杂的数学任务上实现了更高的准确率。
- 训练动态分析显示,RLSD 避免了 OPSD 中出现的后期性能崩溃,并通过选择性加强关键推理 token 以维持更高的熵,从而防止了 GRPO 的快速熵崩溃。
- 案例研究证实,RLSD 有效地将序列级奖励重新分配到 token 级,为决定性推理步骤分配更高的信用,为特定错误分配更强的责任,同时降低通用叙述的权重。