Command Palette
Search for a command to run...
Token Warping 助力多模态大语言模型(MLLMs)从邻近视角进行观测
Token Warping 助力多模态大语言模型(MLLMs)从邻近视角进行观测
Phillip Y. Lee Chanho Park Mingue Park Seungwoo Yoo Juil Koo Minhyuk Sung
摘要
通过扭曲(warping)图像 token 而非像素,是否有助于多模态大语言模型(MLLMs)理解场景在近邻视点下的呈现?尽管 MLLMs 在视觉推理任务上表现优异,但其对视点变化仍较为敏感。这是因为基于像素的扭曲对微小的深度误差高度敏感,且常引入几何畸变。基于心理意象理论中“部分级结构表征是人类视角转换基础”的观点,我们探讨了基于 ViT 的 MLLMs 中的图像 token 是否能作为视角变换的有效载体。我们对比了前向与后向扭曲方法,发现后向 token 扭曲(即在目标视图上定义密集网格,并为每个网格点检索对应的源视图 token)在视点变化下具有更高的稳定性,并能更好地保持语义一致性。在我们提出的 ViewBench 基准测试上的实验表明,token 级扭曲使 MLLMs 能够可靠地进行近邻视点推理,其性能持续优于所有基线方法,包括像素级扭曲方法、经过空间微调的 MLLMs 以及基于生成的扭曲方法。
一句话总结
KAIST 的研究人员提出了“后向令牌扭曲”(backward token warping)技术,该技术通过检索源令牌而非扭曲像素,使多模态大语言模型能够推理邻近视角。这种方法避免了几何失真,并在新的 ViewBench 基准测试中优于现有的基线模型。
主要贡献
- 本文介绍了“后向令牌扭曲”作为一种变换图像令牌以应对视角变化的方法,该方法在目标视图上定义密集网格,并检索相应的源视图令牌,以保持稳定性和语义连贯性。
- 本研究提出了 ViewBench,这是一个专为评估多模态大语言模型在涉及视角偏移的空间推理任务上的表现而设计的新基准,为该领域的性能评估提供了标准化框架。
- 实验表明,所提出的令牌级扭曲方法在仅需最小推理计算量的情况下,始终优于逐像素扭曲、空间微调模型和生成式扭曲方法。
引言
多模态大语言模型(MLLMs)对于自主代理的空间推理至关重要,但它们难以理解场景在邻近视角下的呈现方式。以往依赖逐像素扭曲的方法对深度估计误差高度敏感,往往会引入严重的几何失真,从而破坏语义连贯性;而以物体为中心的方法则无法捕捉细粒度的空间细节。为了解决这些挑战,作者提出了令牌扭曲技术,该技术通过变换图像令牌而非像素来模拟视角偏移。他们证明,后向令牌扭曲(即为密集的目标网格检索源视图令牌)提供了一种稳健且计算高效的视角变换基础,其表现优于现有的微调模型和生成式扭曲基线。
数据集
-
数据集构成与来源:作者利用 ScanNet 中的真实世界室内扫描数据构建了 ViewBench,该数据提供了密集的 RGB-D 帧、真实深度、相机位姿和内参。他们利用 MultiSPA 数据引擎,从相邻视角中采样图像对,并控制重叠视场。
-
各子集的关键细节:该基准根据任务类型和标注风格分为三个子集,所有数据均经过过滤,确保问题仅依赖于源视图和目标视图中均可见的区域:
- ViewBench-Text:包含 571 个样本,其中两个共可见点被标注了字母标签(A/B),用于测试二元左右空间推理。
- ViewBench-Shape:包含 744 个样本,使用简单的几何符号(如三角形、星形)进行类似的空间推理任务。
- ViewBench-Object:包含 300 个样本,其中红色圆形标记指示特定位置,用于开放式物体描述任务。
-
数据使用与处理:作者利用这些子集评估 MLLM 在两项主要任务上的表现:视图条件空间推理和目标视图物体描述。他们过滤图像对以保持 5% 到 35% 之间的重叠率,确保视图既不完全相同也不完全分离,并专门选择那些在源视图和目标视图之间左右空间关系发生翻转的点对。
-
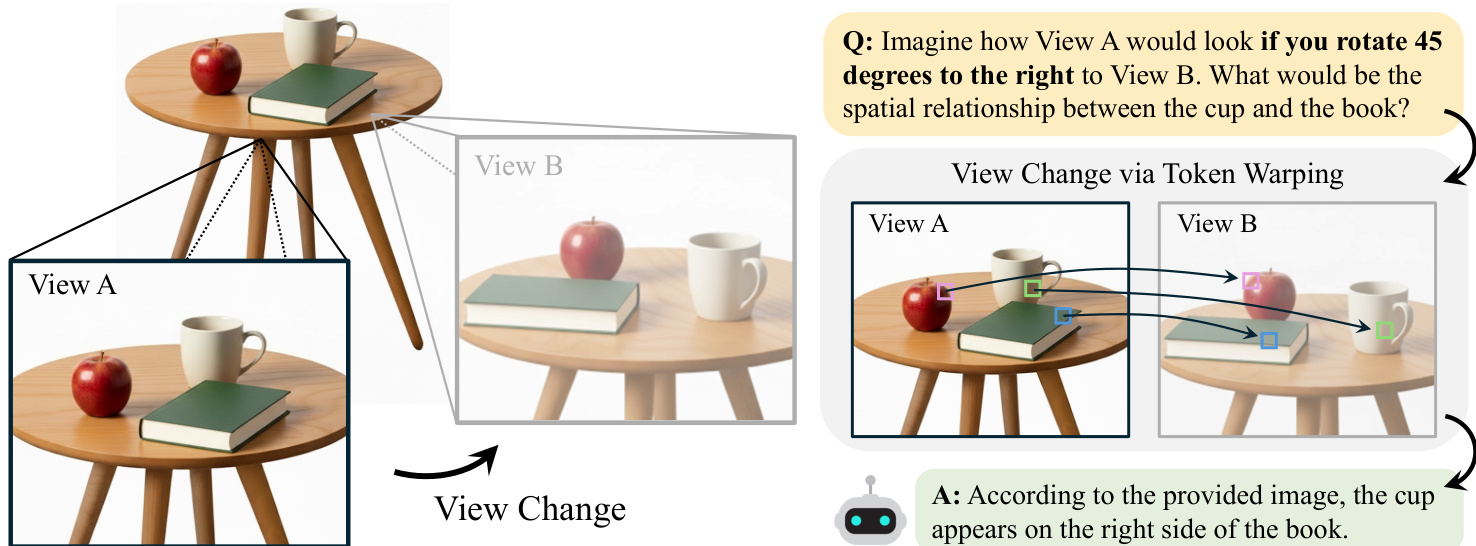
裁剪、元数据与构建策略:构建流程涉及计算可见 3D 点集的交并比(IoU)以确定重叠率,并对图像对进行分箱处理以减轻长尾分布偏差。对于点标注,作者将 3D 世界点投影到两个相机帧中以验证共可见性,并确保在目标视图中有足够的像素间隔(至少 50 像素)。他们在源图像上渲染特定的视觉标记(文本、形状或红色圆圈),并生成描述相对位姿变化的指令,要求模型模拟目标视角以正确回答问题。
方法
作者引入了一个框架,使多模态大语言模型(MLLMs)能够利用图像令牌作为几何变换的主要单元,在视角变化下进行空间推理。这种方法称为“令牌扭曲”(Token Warping),允许模型通过将视觉表示从源视角变换到目标视角来模拟心理意象。
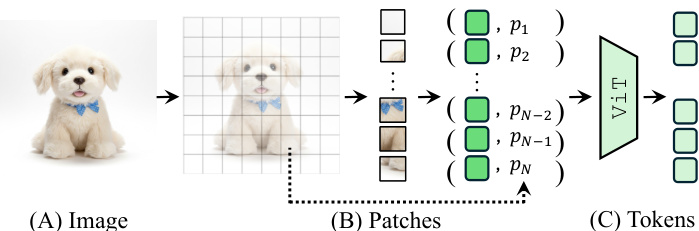
图像令牌化 该方法的基础在于基于 ViT 的 MLLM 如何表示图像。输入图像 I 被划分为固定网格的非重叠图块。每个图块由浅层编码器和视觉编码器(如 ViT)处理,生成一系列图像令牌。这些令牌充当感知原子,在图块级别编码语义内容和位置信息。
作者认为,这些令牌为视角变换提供了最佳的粒度。物体级表示过于粗糙且牺牲了空间细节,而像素级表示则对几何噪声过于敏感。图像令牌在保留丰富视觉细节的同时,对扭曲过程中引入的局部扰动具有鲁棒性。
扭曲策略 为了将场景变换到新视角,系统必须将源图像的令牌映射到目标视图。作者比较了逐像素扭曲与令牌扭曲。逐像素扭曲检索目标坐标的单个像素,但随后对扭曲图像进行图块化往往会引入混淆 MLLM 的局部失真。相比之下,令牌扭曲从源视图检索完整的令牌,保持了语义一致性。
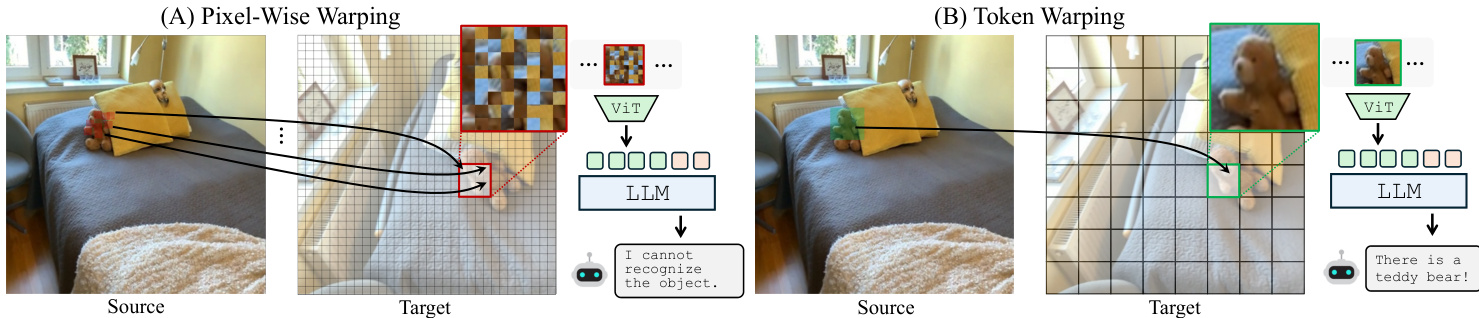
实现主要采用后向扭曲。系统不是在目标视图中定义密集、规则的网格,而是通过目标到源映射 fT→S 从源图像获取相应的令牌(这可以避免稀疏、不规则的分布)。这确保了 MLLM 的输入保持为密集、规则的网格,与其训练分布一致。
令牌获取机制 一个关键的设计选择是如何在映射坐标处从源图像获取令牌,因为这些坐标通常落在原始网格中心之间。作者探索了两种策略:最近邻获取(Nearest Fetching)和自适应获取(Adaptive Fetching)。
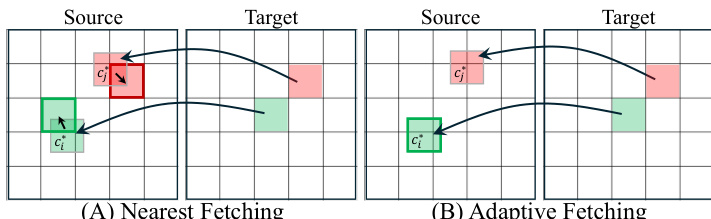
在最近邻获取中,系统选择欧几里得距离上中心最接近映射坐标的现有源图块。这种方法效率很高,因为它重用了原始的固定网格图块化。自适应获取涉及重新对源图像进行图块化,以裁剪出精确以映射坐标为中心的图块。虽然自适应获取更精确,但实验表明最近邻获取的表现相当,使其成为实用且高效的选择。
视图条件推理 该方法应用于需要模型推断空间关系或从新视角描述物体的任务。模型接收源图像以及关于场景在目标视角下呈现方式的问题。

该设置评估了模型稳健处理视图变化的能力,例如从不同角度确定一个物体是在另一个物体的左侧还是右侧,或者描述在扭曲后的目标视图中可见的物体属性。通过利用令牌扭曲,系统有效地在不同视角间转移感知信息,避免了与像素级操作相关的退化。
实验
- 位置噪声敏感性测试表明,MLLM 令牌表示对位置扰动具有高度鲁棒性,显著优于基于像素的基线,验证了令牌作为模拟视角变化稳定单元的有效性。
- 在 ViewBench 上进行的视图条件空间推理和目标视图物体描述实验表明,后向令牌扭曲始终优于前向令牌扭曲、逐像素扭曲以及为空间任务微调的专用 MLLM。
- 定性分析显示,逐像素扭曲会引入严重的视觉伪影和幻觉,而令牌扭曲则保留了局部语义和连贯结构,即使在极端视角偏移和遮挡下也能实现准确推理。
- 鲁棒性评估证实,当使用现成的深度和位姿模型估计的几何数据而非真实数据时,令牌扭曲的性能优势依然存在。
- 基于几何的 Oracle 分析验证了底层扭曲流程的高度准确性,表明剩余的性能差距源于 MLLM 的感知限制而非几何误差。