Command Palette
Search for a command to run...
用于 Large Language Model 推理的快速 NF4 量化反量化 Kernel
用于 Large Language Model 推理的快速 NF4 量化反量化 Kernel
Xiangbo Qi Chaoyi Jiang Murali Annavaram
摘要
大语言模型(LLMs)的规模已超越了单张 GPU 设备的显存容量,因此必须采用量化技术以实现实际部署。虽然 NF4(4-bit NormalFloat)量化技术能够实现 4 倍的显存压缩,但在当前的 NVIDIA GPU(如 Ampere 架构的 A100)上进行推理时,仍需将其反量化(dequantization)回 FP16 格式,这造成了严重的性能瓶颈。本文提出了一种轻量级的共享内存(shared memory)优化方案,通过对存储层级结构(memory hierarchy)进行原则性的利用,在保持与现有生态系统完全兼容的同时,解决了这一难题。我们将该技术与开源的 BitsAndBytes 实现进行了对比。实验结果显示,在三个模型(Gemma 27B、Qwen3 32B 和 Llama3.3 70B)上,该技术实现了 2.0–2.2 倍的算子(kernel)加速;通过利用共享内存相比全局内存(global memory)访问所具有的 12–15 倍延迟优势,端到端性能提升高达 1.54 倍。我们的优化方案通过简化索引逻辑减少了指令计数,且每个线程块(thread block)仅使用 64 字节的共享内存。这表明,轻量级的优化手段即使在工程投入极小的情况下,也能带来显著的性能增益。这项工作为 HuggingFace 生态系统提供了一种“即插即用”的解决方案,使得在现有的 GPU 基础设施上运行先进模型变得更加普及。
一句话总结
通过利用轻量级 shared memory 优化来替代昂贵的 global memory 访问,该方法在保持与 HuggingFace 生态系统完全兼容的同时,在 Gemma 27B、Qwen3 32B 和 Llama3.3 70B 模型上实现了高达 2.2 倍的 kernel 加速和 1.54 倍的端到端性能提升。
核心贡献
- 本文引入了一种轻量级 shared memory 优化方案,利用 Ampere 架构的存储层级结构来解决 NF4 量化模型中的反量化瓶颈。
- 该方法将冗余的每线程 global memory 访问转换为高效的每 block 加载,使每个 thread block 的查找表流量减少了 64 倍,并简化了索引逻辑,从而将指令计数减少了 71%。
- 在 Gemma 27B、Qwen3 32B 和 Llama3.3 70B 上的实验评估表明,在保持与 HuggingFace 和 BitsAndBytes 生态系统完全兼容的情况下,实现了 2.0 到 2.2 倍的 kernel 加速以及高达 1.54 倍的端到端性能提升。
引言
随着大型语言模型的规模超过单个 GPU 的显存容量,NF4 量化已成为将显存占用降低 4 倍的关键技术。然而,由于当前的 NVIDIA Ampere 架构缺乏原生的 4-bit 计算支持,权重在每次矩阵乘法期间必须被反量化为 FP16。这一过程造成了严重的性能瓶颈,由于冗余且昂贵的 global memory 访问,反量化过程占据了端到端延迟的高达 40%。通过将每线程的 global memory 加载转换为高效的每 block 加载,该研究利用轻量级 shared memory 优化解决了这一效率低下问题。这种方法利用片上存储显著的延迟优势,在保持与 HuggingFace 和 BitsAndBytes 生态系统完全兼容的同时,实现了 2.0 到 2.2 倍的 kernel 加速。
实验
评估过程使用单个 NVIDIA A100 GPU,在 Gemma 27B、Qwen3 32B 和 Llama3.3 70B 三个模型上,将优化的 NF4 反量化 kernel 与基准实现进行了对比测试。实验证实,由于高显存开销以及复杂基于树结构的解码导致的 warp divergence,原始反量化过程产生了显著的瓶颈。结果表明,shared memory 优化能够持续加速 kernel 执行,从而带来显著的端到端延迟和吞吐量提升,这种提升在大型模型中尤为明显。
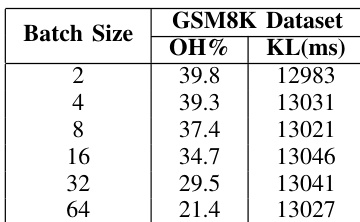
通过使用 GSM8K 数据集,对 Qwen3-32B 模型的反量化开销和 kernel 延迟进行了分析。结果显示,在各种 batch size 下,反量化始终占据总推理时间的重要部分。随着 batch size 的增加,反量化开销百分比有所下降。无论 batch size 如何,kernel 延迟保持相对一致。反量化过程构成了端到端推理中的实质性瓶颈。
针对不同的模型架构和 batch size,评估了优化后的 NF4 反量化实现的 kernel 级加速效果。结果表明,无论具体的模型或工作负载规模如何,该优化都能提供一致的性能增益。该优化在所有测试的模型和 batch size 下均实现了稳定的加速。较大的模型和不同的 batch 配置均获得了相似水平的 kernel 级改进。在从小型到大型工作负载的不同 batch size 变化中,性能增益保持稳定。
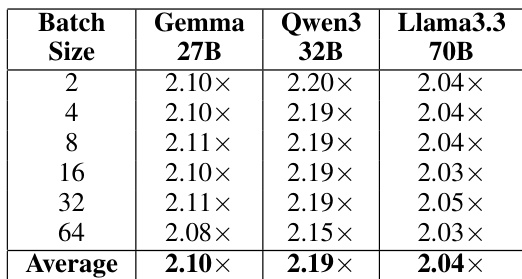
通过使用 Qwen3-32B 模型和多种架构,评估了反量化开销以及优化后的 NF4 实现的有效性。虽然反量化被确定为端到端推理中的重要瓶颈,但优化后的 kernel 在不同模型和 batch size 下均提供了持续的性能增益。这些结果证明,无论具体的工作负载规模或模型架构如何,该优化都能保持稳定的加速效果。