Command Palette
Search for a command to run...
生成式世界渲染器
生成式世界渲染器
Zheng-Hui Huang Zhixiang Wang Jiaming Tan Ruihan Yu Yidan Zhang Bo Zheng Yu-Lun Liu Yung-Yu Chuang Kaipeng Zhang
摘要
将生成式逆向渲染与前向渲染扩展至真实世界场景,受限于现有合成数据集在真实感与时域连贯性方面的不足。为弥合这一长期存在的领域差距,我们构建了一个源自视觉复杂度极高的 AAA 级游戏的大规模动态数据集。采用一种新颖的双屏拼接采集方法,我们在多样化的场景、视觉特效及环境(包括恶劣天气与运动模糊变体)中,提取了 400 万帧连续的同步 RGB 图像与五个 G-buffer 通道(分辨率为 720p,帧率为 30 FPS)。该数据集显著推动了双向渲染的发展:一方面实现了鲁棒的野外几何与材质分解,另一方面支持了高保真度的 G-buffer 引导视频生成。此外,针对缺乏真值(ground truth)时逆向渲染在真实场景中的性能评估问题,我们提出了一种基于视觉语言模型(VLM)的新型评估协议,用于衡量语义、空间及时域一致性。实验表明,基于本数据集微调的逆向渲染器在跨数据集泛化能力与可控生成方面表现优异;同时,我们的 VLM 评估结果与人类判断具有强相关性。结合我们提供的工具包,本前向渲染器支持用户利用 G-buffer 和文本 prompt 对 AAA 级游戏的风格进行编辑。
一句话总结
Alaya Studio 与多所高校的研究人员引入了一套源自 3A 级游戏的大规模数据集,以弥合双向渲染中的真实感差距。通过提供同步的 RGB 和 G-buffer 帧,这项工作实现了鲁棒的逆渲染和高保真 G-buffer 引导的视频生成,超越了以往受限于合成数据稀缺的方法。
主要贡献
- 本文提出了一种可扩展的 G-buffer 获取流程,通过硬件加速捕获将多通道数据渲染至统一画布,无需修改游戏引擎即可实现时间同步记录。
- 提出了一种微调后的视频逆渲染模型,利用游戏数据进行运动增强训练,在合成和真实世界基准测试中,于深度、法线、反照率及材质参数估计方面均达到了最先进水平。
- 该工作展示了一种实用的游戏编辑应用,通过调整文本到视频模型以接受 G-buffer 作为条件输入,允许用户在推理过程中通过文本提示操纵光照和环境效果。
引言
未提供原文摘要。请提供研究论文的摘要或正文片段,以便我生成包含所需技术背景、局限性和贡献的背景总结。
数据集
-
数据集构成与来源 作者从两款视觉复杂的 3A 游戏《赛博朋克 2077》(Cyberpunk 2077)和《黑神话:悟空》(Black Myth: Wukong)中精心策划了一个大规模动态数据集。该集合通过提供 400 万帧 720p 分辨率、30 FPS 的连续帧,弥合了合成数据与真实世界数据之间的领域差距。该数据集独特地将同步 RGB 视频与五个高保真 G-buffer 通道(深度、法线、反照率、金属度和粗糙度)配对,涵盖包括城市与自然场景在内的多样化环境,以及雨、雾、雪等不同天气条件。
-
各子集的关键细节
- 《赛博朋克 2077》子集: 采用半自动驾驶设置,利用长距离航点生成具有可变速度的连续轨迹,并辅以室内覆盖的步行序列。该子集具有更高比例金属表面和均衡的亮度,反映了其城市化和富含金属的主题。
- 《黑神话:悟空》子集: 源自已完成存档文件中的探索序列,刻意避免战斗以专注于多样化的环境穿越。该子集包含更多高粗糙度区域和较低的亮度值,与其自然、阴影笼罩的户外环境设定一致。
- 过滤规则: 作者排除了场景内容和相机在整个序列中均保持静止的片段。同时移除了亮度过低的帧以确保质量。
-
数据在模型中的使用 该数据集作为训练双向渲染模型的主要监督信号,专门用于微调基于扩散的架构,以进行逆渲染(材质分解)和正向渲染(G-buffer 引导的视频生成)。作者利用该数据提高跨数据集的泛化能力和时间一致性,使模型能够处理长尾复杂性,如体积效应和快速运动。采用了一种新颖的基于视觉语言模型(VLM)的评估协议,以评估传统指标难以衡量的语义、空间和时间一致性。
-
处理与构建策略
- 捕获流程: 团队使用非侵入式的双屏拼接捕获方法,通过 ReShade 在图形 API 级别拦截渲染管线,避免了反编译或资源提取。
- 法线重建: 由于仅可靠地提供世界空间法线,作者利用逆投影和有限差分从深度缓冲区重建相机空间法线。
- 通道解耦: 为防止压缩伪影,金属度和粗糙度等材质通道被解耦,并在捕获前渲染到空间上分离的屏幕区域。
- 运动模糊合成: 虽然引擎捕获的是清晰的规范 RGB 帧,但作者利用 RIFE 进行帧插值和线性域平均,离线合成运动模糊变体,以更好地匹配真实世界的成像条件。
- 元数据标注: 利用大语言模型(Qwen3-VL)分析采样帧,为每个片段生成关于纹理、天气、场景类型(室内/室外)和运动动态的分类标签。
方法
所提出的框架包含三个 distinct 阶段:策划(Curation)、分析(Analysis)和后处理(Post-Processing)。在初始的策划阶段,作者通过实施同步多屏录制策略,解决了直接导出多通道 G-buffer 成本高昂的问题。该系统不依赖昂贵的存储带宽或 GPU 到 CPU 的回读,而是将目标缓冲区着色到屏幕并通过硬件加速捕获进行录制。为了在所有六个通道之间保持严格的时间同步,采用了一种马赛克合成策略,将缓冲区渲染到统一画布上。
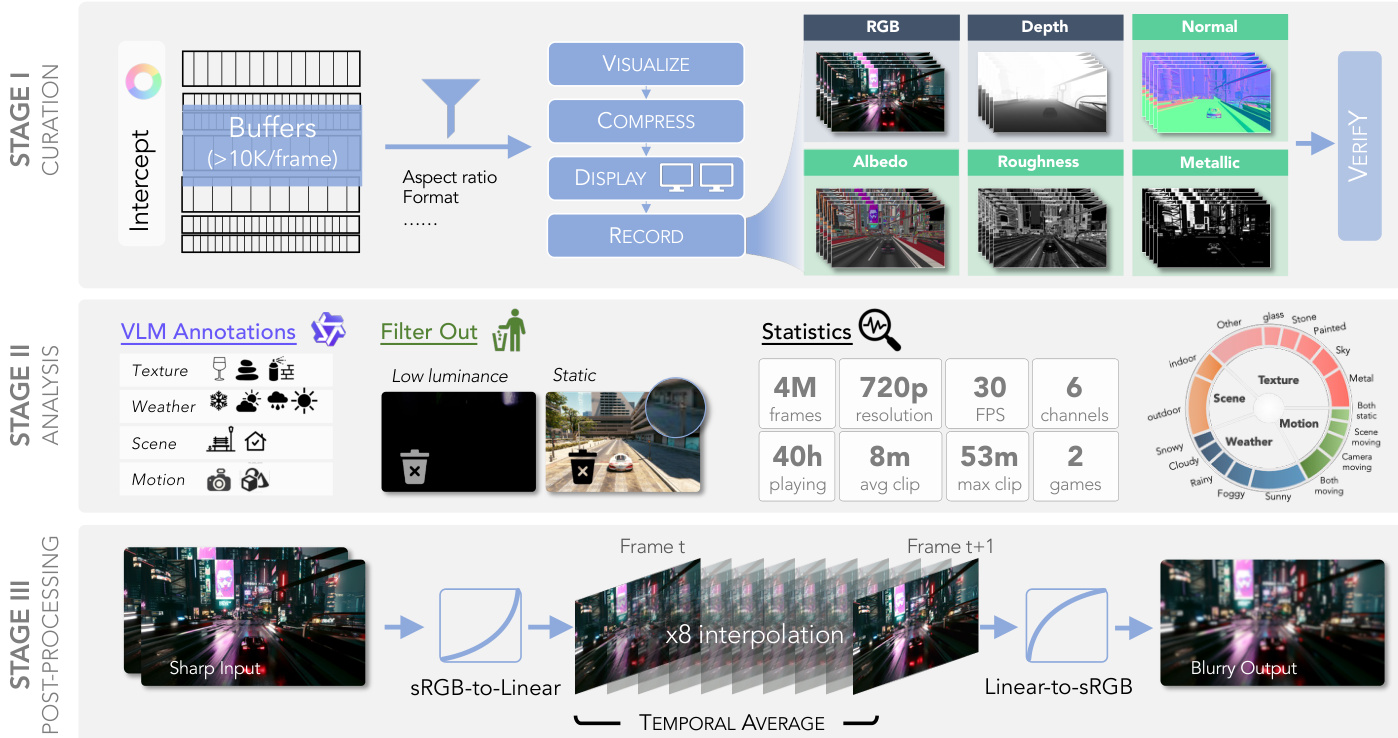
如框架图所示,此过程允许同时捕获 RGB、深度、法线、反照率、粗糙度和金属度通道。随后进行验证步骤,基于语义正确性、外观质量和时间一致性评估金属度图,以确保材质的合理性。为了克服显示分辨率限制,该设置拼接了两台 2K 显示器,使每个通道能以 720p 的有效分辨率进行录制,同时通过中心裁剪保持预期的宽高比。
随后,流程进入分析阶段,通过自动过滤和标注确保数据质量。利用 VLM 根据纹理、天气、场景和运动属性对帧进行标注。过滤掉亮度低或内容静止的帧,以维持数据集的多样性和质量。统计分析确认收集了 400 万帧 30 FPS 的数据,涵盖了各种环境条件和运动类型。
最后,后处理阶段生成运动模糊效果以模拟真实世界的相机捕获。该过程首先将清晰的输入帧从 sRGB 转换为线性空间。系统随后在连续帧(记为 Frame t 和 Frame t+1)之间执行 8 倍插值,接着进行时间平均操作。生成的数据再从线性空间转换回 sRGB 空间,以产生最终的模糊输出,从而在不需物理相机移动的情况下有效合成运动模糊。
实验
- 使用视觉语言模型(VLM)进行的真实场景评估证实,所提出的数据集通过利用全局上下文和时间推理,提高了复杂且无真值环境中的材质预测泛化能力。
- 在合成数据集(《黑神话:悟空》和 Sintel)上的定量基准测试表明,与新数据集进行微调后,在深度、法线和反照率估计方面,性能优于现有的 DiffusionRenderer 基线。
- 定性分析证实,该方法有效地解耦了场景的内在属性,生成了更清晰的反照率图和鲁棒的材质预测,能够抵抗烟雾和体积散射等大气干扰。
- 消融研究表明,训练期间的运动增强显著提高了时间稳定性,并减少了强运动模糊视频中的伪影。
- 重新打光实验显示,改进后的 G-buffer 使现成的正向渲染器能够生成光照一致的新视角,证明了以数据为中心方法的有效性。
- 游戏编辑评估表明,使用高质量 G-buffer 作为条件输入,在可编辑性和视觉保真度之间取得了比 RGB 衍生或随机编辑基线更好的平衡,实现了复杂大气效果的无缝集成。