Command Palette
Search for a command to run...
可操控视觉表示
可操控视觉表示
Jona Ruthardt Manu Gaur Deva Ramanan Makarand Tapaswi Yuki M. Asano
摘要
预训练视觉 Transformer(ViTs),如 DINOv2 和 MAE,能够提供通用的图像特征,适用于检索、分类和分割等多种下游任务。然而,此类表征往往聚焦于图像中最显著的视觉线索,而无法将其引导至关注度较低但重要的概念。相比之下,多模态大语言模型(Multimodal LLMs)虽可通过文本提示进行引导,但其生成的表征往往以语言为中心,导致在通用视觉任务中的有效性下降。为解决上述问题,我们提出了“可引导视觉表征”(Steerable Visual Representations),这是一类新型视觉表征,其全局与局部特征均可通过自然语言进行引导。与大多数视觉 - 语言模型(如 CLIP)在编码后融合文本与视觉特征(晚期融合)不同,我们采用轻量级交叉注意力机制,将文本直接注入视觉编码器的各层(早期融合)。我们构建了用于衡量表征可引导性的基准测试,并实验证明:我们的可引导视觉特征能够聚焦于图像中任意目标对象,同时保持底层表征的质量。此外,该方法在异常检测与个性化目标判别任务中,表现与专用方法相当或更优,并展现出对分布外任务的零样本泛化能力。
一句话总结
纽伦堡理工大学、卡内基梅隆大学和海德拉巴 IIIT 的研究人员提出了 SteerViT,这是一个通过早期融合交叉注意力机制将文本直接注入冻结 ViT 层的框架。与晚期融合模型不同,SteerViT 能够将视觉特征导向特定概念,同时保持表征质量,从而在异常检测和个人化物体区分等任务上实现零样本泛化。
主要贡献
- 本文提出了 SteerViT,这是一种通过轻量级交叉注意力将自然语言直接注入冻结 Vision Transformer 层的方法,旨在将全局和局部视觉特征导向特定概念。
- 建立了新的基准以衡量表征的可导向性,证明该方法能够在保持底层视觉表征高质量的同时,聚焦于图像中不太显著的物体。
- 实验表明,该方法在异常检测和个人化物体区分任务上达到或超越了专用方法的表现,展现出对分布外场景的零样本泛化能力,且可训练参数显著更少。
引言
预训练的 Vision Transformer(如 DINOv2)提供了强大的通用图像特征,但本质上倾向于关注最显著的物体,使得将注意力引导至不太显著的概念变得困难。虽然多模态大语言模型(MLLMs)允许文本引导,但它们往往产生以语言为中心的表征,牺牲了视觉保真度,且在通用视觉任务上表现不佳。现有方法通常依赖晚期融合,即文本仅在视觉编码后交互,无法影响特征提取过程本身。
作者提出了 SteerViT,这是一个通过轻量级交叉注意力将自然语言直接注入冻结视觉编码器层的框架。这种早期融合方法允许用户在不重新训练基础模型的情况下,将全局和局部视觉特征导向特定物体或属性。通过仅增加 2100 万个可训练参数,该方法实现了帕累托改进,在保持高质量视觉表征的同时,实现了精确的文本引导控制和面向多样化下游任务的零样本泛化。
数据集
- 作者构建了一个包含指代分割和定位数据集的训练混合集,以确保视觉领域和文本表达风格的多样性,总计包含 16.2 万张独特图像和 228 万个图像 - 文本对。
- 数据集构成包括四个主要来源,各具特定特征:
- RefCOCO、RefCOCO+ 和 RefCOCOg 提供了基于 COCO 图像的指代表达,其中 RefCOCO+ 排除了空间语言以迫使模型依赖外观线索,而 RefCOCOg 则提供更长、更具描述性的表达。
- LVIS 使用相同的 COCO 图像,但专注于细粒度和长尾物体类别。
- Visual Genome 贡献了密集标注场景中的区域描述及边界框,以增加词汇量和空间关系的复杂性,其边界框已使用 SAM2 转换为二值分割掩码。
- Mapillary Vistas 引入了具有细粒度全景标注的街景图像,以将视觉领域覆盖范围扩展至 COCO 之外,利用了来自 Describe Anything 的合成指代表达和掩码。
- 模型训练利用这些组合数据,使系统暴露于从单物体到密集城市全景的各种场景复杂度中,表达长度从两词标签到多句描述不等,视觉领域涵盖室内、室外及街景。
- 处理步骤包括将 Visual Genome 的边界框转换为分割掩码,并采用 Mapillary Vistas 的合成表达,以确保在整个数据谱系中实现鲁棒的导向表征。
方法
作者提出了 SteerViT,这是一个旨在赋予预训练 Vision Transformer (ViT) 利用自然语言提示引导视觉特征能力的框架。如不同视觉表征家族的对比图所示,其核心架构将轻量级交叉注意力机制直接集成到冻结的 ViT 骨干网络中。这种方法与多模态大语言模型和开放词汇定位模型形成对比,它在保持基础视觉模型效率和质量的同時,使视觉编码器以语言为条件。
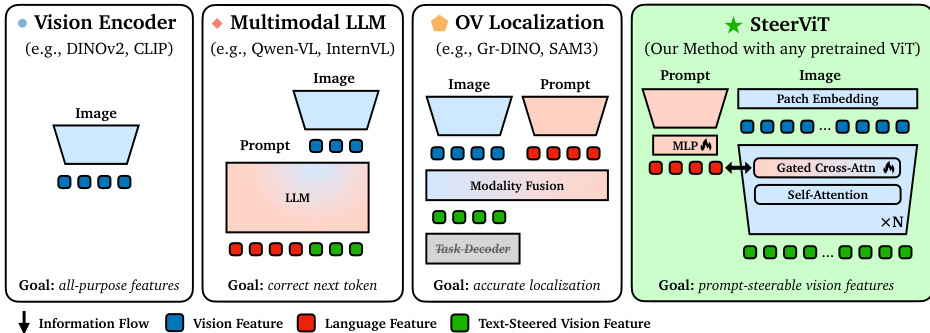
SteerViT 框架由四个主要组件组成。首先,冻结的视觉编码器(如 DINOv2)处理输入图像以生成一系列补丁令牌(patch tokens)。其次,冻结的文本编码器(具体为 RoBERTa-Large)为条件提示生成令牌级嵌入。第三,多模态适配器使用可训练的双层 MLP 将这些文本嵌入投影到视觉嵌入空间。最后,门控交叉注意力层交错插入 ViT 的每隔一个 Transformer 块中。在这些层中,视觉补丁令牌作为查询(queries),而适配后的文本令牌作为键(keys)和值(values)。
文本条件融合到视觉残差流中由一个 tanh 门控控制,该门控包含一个特定于层的可学习标量 αℓ,其初始化为零。这种初始化确保模型在训练开始时与冻结的 ViT 完全相同,从而保留预训练的表征质量。第 ℓ 层视觉令牌的更新规则定义为:
Zν(ℓ+1)=Zν(ℓ)+tanh(αℓ)⋅Z^ν(ℓ)
由于 tanh(0)=0,门控立即接收到学习信号,允许 αℓ 在优化过程中偏离零值,并逐渐激活条件通路。
为了训练模型,作者采用了指代分割作为预训练任务。如训练流程图所示,模型的任务是预测哪些图像补丁对应于文本提示中描述的目标物体。一个线性分类头将导向的补丁表征映射为分割概率,模型使用软交叉熵损失针对真实掩码分数进行优化。
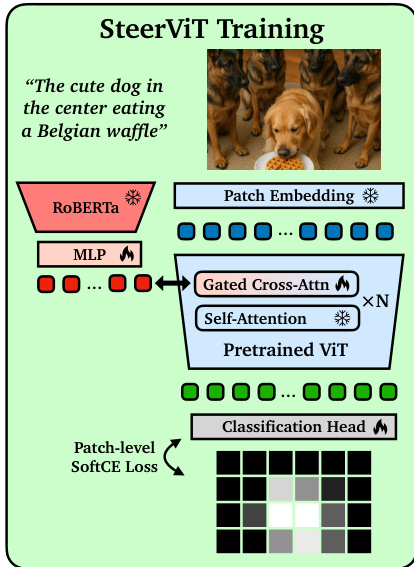
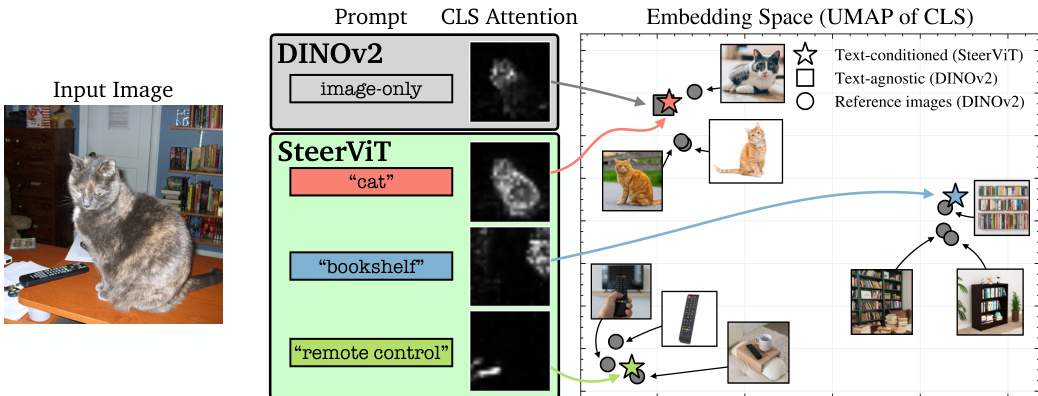
该训练目标鼓励交叉注意力层将文本信息专门路由到相关的视觉补丁令牌。这种导向的有效性在嵌入空间中显而易见,其中文本条件的特征形成了对应于提示物体的独特簇,这与仅图像编码器形成的通用簇不同。
实验
- 条件检索 (CORE):验证了 SteerViT 能够利用文本提示将全局特征导向特定的非显著物体,而标准视觉编码器会坍缩到主导场景概念,晚期融合方法则无法修改冻结的视觉特征。
- MOSAIC 定位:证明了文本条件能够将自注意力重定向到复杂场景中的查询物体,从而实现针对特定实体的聚焦,而非仅关注视觉上最显著的物体。
- 表征质量权衡:确认 SteerViT 在实现高可导向性的同时,未牺牲底层视觉编码器的可迁移性,这与开放词汇定位模型(丧失泛化能力)或 MLLMs(产生高昂计算成本)形成对比。
- 语义粒度控制:表明文本提示中的细节水平直接决定了视觉表征的粒度,允许模型在粗略类别聚类和细粒度实例区分之间切换。
- 嵌入空间重组:展示了文本条件可以重构嵌入拓扑,按语义层次或任意组合属性(如共享物体部件)对图像进行分组。
- 零样本领域迁移:证明了语言驱动的导向能够实现鲁棒的泛化,适用于工业异常分割等分布外任务,而无需针对特定任务进行训练。
- 架构消融实验:确立了 Transformer 层内的文本早期融合、门控交叉注意力机制以及基于分割的训练目标对于平衡可导向性与特征质量至关重要。