Command Palette
Search for a command to run...
面向流式视频理解的简单基线
面向流式视频理解的简单基线
Yujiao Shen Shulin Tian Jingkang Yang Ziwei Liu
摘要
近期,视频流理解方法日益依赖复杂的记忆机制来处理长视频流。我们对此趋势提出质疑,并指出一个简洁的发现:仅将最近的 N 帧输入现成视觉语言模型(VLM)的滑动窗口基线方法,其性能已足以媲美甚至超越已发表的流式视频模型。我们将该基线形式化为 SimpleStream,并在 OVO-Bench 和 StreamingBench 上将其与 13 个主流的离线及在线视频 LLM 基线进行对比评估。尽管结构简洁,SimpleStream 仍表现出持续强劲的性能:仅使用最近 4 帧,其在 OVO-Bench 上的平均准确率达到 67.7%,在 StreamingBench 上达到 80.59%。受控消融实验进一步表明,更长上下文的价值依赖于骨干网络(backbone),而非随模型规模均匀提升;同时揭示了一种一致的“感知–记忆”权衡:增加历史上下文虽可提升召回能力,但往往会削弱实时感知性能。因此,除非在相同协议下明确优于 SimpleStream,否则不应将更强的记忆、检索或压缩模块视为实质性进展。我们主张,未来的流式视频基准测试应将近期场景感知与长程记忆能力分离,以便更清晰地评估由额外复杂性带来的性能提升。
一句话总结
南洋理工大学的研究人员推出了 SIMPLESTREAM,这是一个极简基线,仅向现成的视觉语言模型(VLM)输入最近帧,在 OVO-Bench 和 StreamingBench 上超越了以复杂记忆为中心的模型,同时揭示了关键的感知 - 记忆权衡。
主要贡献
- 本文介绍了 SIMPLESTREAM,这是一个极简的流式基线,仅使用现成的 VLM 处理最近的 N 帧,无需复杂的记忆库、检索系统或压缩模块。
- 在 OVO-Bench 和 StreamingBench 上的全面评估表明,这种简单的近期上下文方法在保持更低峰值 GPU 内存占用和具有竞争力的延迟的同时,实现了最先进的性能,优于以往的流式方法。
- 受控消融研究表明,更长上下文的收益取决于骨干网络,而非在所有模型规模上均匀分布;增加历史上下文往往以提高记忆回忆为代价,损害实时感知能力。
引言
流式视频理解对于实时应用至关重要,在这些应用中,模型必须在严格的因果和内存约束下处理连续的视频流。先前的研究越来越依赖复杂的记忆机制,如外部记忆库、检索系统或压缩模块,其假设是管理长期历史需要复杂的架构设计。然而,这些复杂的方法往往只能带来适度的提升,同时引入了显著的计算开销,并导致一种权衡:增强的记忆回忆可能会损害实时场景感知。作者推出了 SIMPLESTREAM,这是一个极简基线,直接将最近的 N 帧输入到现成的 VLM 中,无需额外的记忆或训练。他们证明,这种基于简单近期性的方法在 OVO-Bench 和 StreamingBench 等主要基准测试中,能够匹配甚至超越复杂的流式模型,揭示了更长上下文的收益取决于骨干网络而非普遍适用,并主张建立一种将感知性能与记忆性能分开评估的新标准。
方法
作者推出了 SimpleStream,这是一个刻意设计的极简基线,旨在仅利用近期视觉上下文来隔离当前现成视觉语言模型(VLM)的能力。与以往采用管理长程历史机制的流式系统不同,SimpleStream 依赖于滑动窗口方法。参考下方的框架图,该图展示了系统如何通过选择以当前帧为中心的“最近 N 帧窗口”来处理连续视频流,并将其输入视觉语言模型。
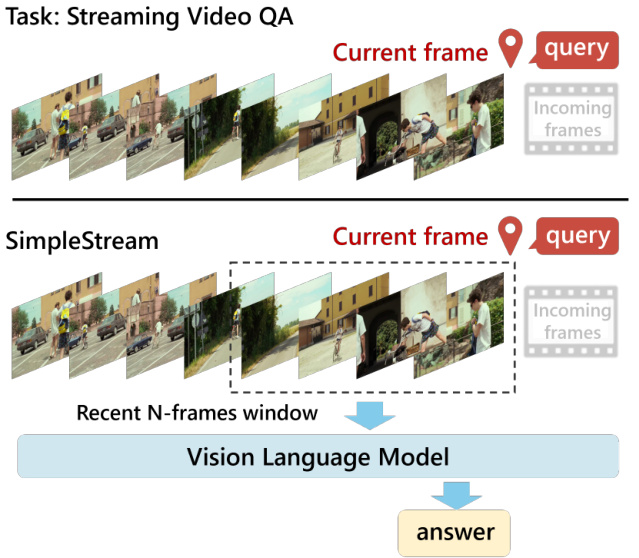
设视频流表示为帧序列,其中 fi 表示时间步 i 的视觉帧。给定时间 t 的问题 qt,该方法仅向基础 VLM 输入最近的 N 帧和文本查询。该过程形式化如下:
SIMPLESTREAM(t)=VLM({ft−N+1,…,ft},qt)
根据设计,SimpleStream 省略了额外的记忆机制,意味着滑动窗口之外的帧会被丢弃。因此,每个查询的内存和计算量受 N 限制,不会随流长度增长。该方法不引入任何架构修改、记忆模块或额外训练;它严格作为应用于现成 VLM 的推理时输入策略运行。
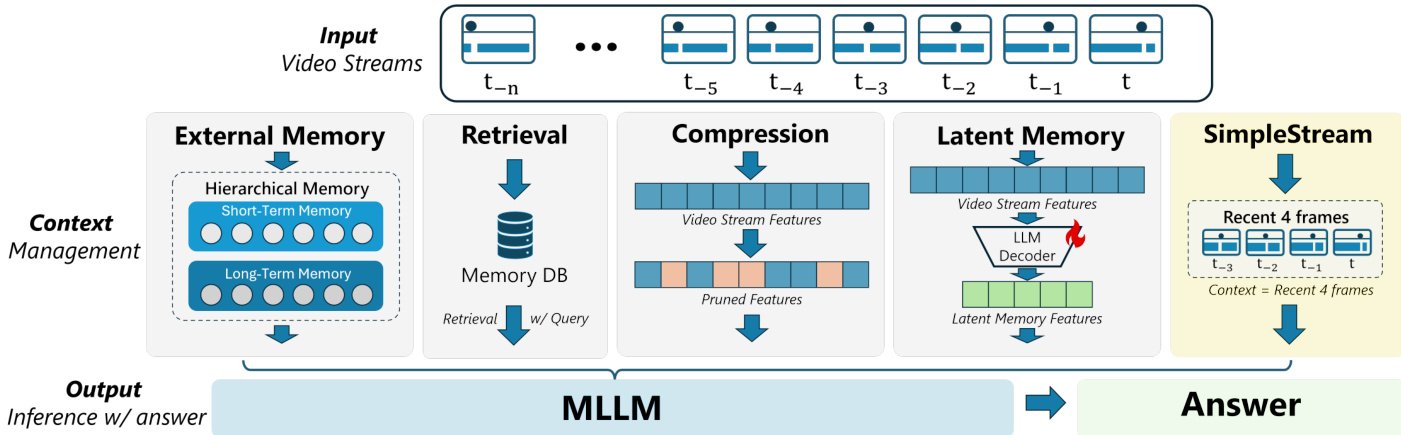
下方的架构对比突出了 SimpleStream 与其他上下文管理策略的区别。虽然替代方法利用外部记忆、检索、压缩或潜在记忆来处理长期依赖,但 SimpleStream 完全绕过了这些组件。它作为一个受控的参考基线,用于确定仅凭近期视觉上下文能在多大程度上获得流式性能,同时最大限度地减少额外训练或系统级工程带来的混淆效应。
实验
- 在 OVO-Bench 和 StreamingBench 上的实验验证了 SIMPLESTREAM(一种仅使用固定近期帧窗口的极简方法)优于具有专用记忆库或检索模块的复杂流式系统,特别是在实时视觉感知任务中。
- 关于近期窗口大小和模型规模的消融研究表明,性能并不会随上下文变长而单调提升;虽然适度的窗口扩展有帮助,但进一步增加往往导致收益递减或性能下降,表明更多的历史上下文并非普遍有益。
- Visual-RAG 分析揭示了一种独特的感知 - 记忆权衡:检索历史片段提高了情景记忆回忆,但一致地损害了实时感知,这表明当前的记忆注入技术往往会破坏模型对当前场景的理解。
- 效率评估证实,无论流长度如何,SIMPLESTREAM 都能保持低延迟和稳定的 GPU 内存占用,证明竞争性流式推理并不需要持久的历史状态。
- 总体结论表明,当前的基准测试严重偏向近期感知能力,未来的进步需要能够利用历史证据而不牺牲当前场景理解清晰度的方法。