Command Palette
Search for a command to run...
视频对象与交互删除
视频对象与交互删除
Saman Motamed William Harvey Benjamin Klein Luc Van Gool Zhuoning Yuan Ta-Ying Cheng
摘要
现有的视频物体移除(video object removal)方法在修复物体“后方”的内容以及修正阴影、反射等外观层面伪影方面表现出色。然而,当被移除的物体存在更显著的交互作用时(例如与其他物体发生碰撞),现有模型无法对其进行修正,从而产生不合理的视觉结果。我们提出了 VOID,这是一个旨在这些复杂场景下实现物理合理性(physically-plausible)修复的视频物体移除框架。为了训练该模型,我们利用 Kubric 和 HUMOTO 生成了一个全新的、配对的“反事实物体移除”(counterfactual object removals)数据集;在该数据集中,移除一个物体需要同时改变后续的物理交互过程。在推理阶段,通过 vision-language model 识别场景中受移除物体影响的区域,并利用这些区域来引导 video diffusion model,从而生成物理一致的反事实结果。在合成数据和真实数据上的实验表明,与之前的视频物体移除方法相比,我们的方法在物体移除后能更好地保持一致的场景动力学(scene dynamics)。我们希望该框架能为如何通过高层级因果推理(high-level causal reasoning)使视频编辑模型成为更出色的“世界模拟器”提供启示。
一句话总结
VOID 视频物体移除框架通过使用 vision-language model 来识别受影响区域,并利用 video diffusion model 生成物理上合理的反事实结果,解决了复杂的物理交互问题,在合成数据和真实数据上均表现出优于现有方法的一致场景动态保持能力。
核心贡献
- 本文引入了 VOID,这是一个视频物体移除框架,旨在当移除的物体与场景存在复杂交互时,合成物理上合理的反事实视频。
- 本研究提出了两个新的配对反事实物体移除视频数据集,分别使用 Kubric 引擎和 HUMOTO 数据集生成,以促进复杂物理场景的训练。
- 该方法采用 VLM 引导的 quadmask 生成流水线来识别受影响区域,从而指导 video diffusion model 产生物理一致的结果。
- 在合成和真实世界数据上的实验表明,该方法在保持一致的场景动态和泛化到多样化场景方面优于先前的 inpainting 和 text-guided video models。
引言
视频物体移除对于高质量视频编辑至关重要,然而现有方法主要集中在对物体背后的像素进行 inpainting,或修正阴影和反射等光度效应。当移除的物体涉及复杂的物理交互(如碰撞或支撑其他物品)时,这些当前方法往往会失效,导致物理上不合理的场景。本文引入了 VOID,这是一个旨在通过合成反事实视频结果来实现物理合理 inpainting 的框架。该框架利用 vision-language model 来识别受影响区域,并使用 video diffusion model 生成一致的动态,同时辅以全新的反事实物体移除配对数据集。
数据集
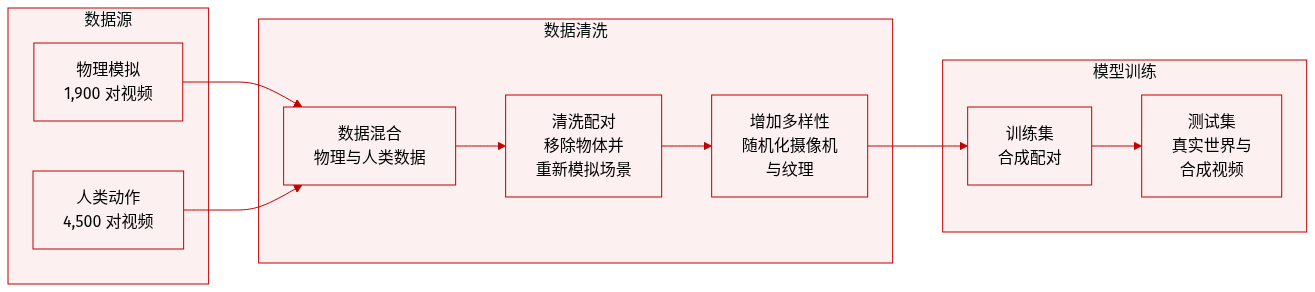
本文开发了一个专门的反事实数据集,旨在教导模型如何移除对周围环境产生物理影响的物体。数据集的组成和处理细节如下:
-
数据集组成与来源
- 刚体动力学 (Kubric): 使用基于物理的模拟生成了约 1,900 对视频。这些视频通过对多个物体的各种初始位置和速度进行采样,模拟了碰撞、坠落和结构依赖。
- 关节交互 (HUMOTO): 使用 4D 人体动作捕捉数据生成了约 4,500 对视频。这些序列侧重于动态操作,其中待移除的物体是正在进行各种活动的人类。
-
数据处理与元数据构建
- 反事实对生成: 对于每一对视频,原始视频 (V) 包含目标物体 (O),而反事实视频 (V^) 通过移除物体并重新模拟场景来创建。这确保了即使交互发生变化,生成的视频在物理上也是一致的。
- 解耦策略: 为了帮助模型区分物体效应和摄像机运动,在渲染过程中对摄像机轨迹和焦距缩放进行了随机化处理。
- 纹理随机化: 在 HUMOTO 子集中,对人类、背景和所有场景物体进行了纹理随机化,以提高泛化能力。
-
模型使用与评估
- 训练: 合成的 Kubric 和 HUMOTO 配对数据作为主要的训练数据,以实现向真实世界领域的泛化。
- 测试: 使用两个不同的测试集评估模型:一个包含 75 个涵盖碰撞和阴影移除等各种任务的真实世界视频;另一个合成数据集,将 30 个 Kubric 和 HUMOTO 视频与现有的物体移除数据集相结合。
方法
本文提出了 VOID,这是一种旨在通过移除目标物体并模拟产生的物理交互来生成反事实视频的模型。给定输入视频 V={It}t=1T 和用于识别待移除物体的二值 mask 序列 Mo={mt}t=1T,目标是学习一个函数 f 使得:
V^=f(V,Mo)
为了实现这一目标,模型必须超越简单的空间补洞,转而构思场景在没有目标物体的情况下如何演变。这涉及消除目标、重新生成受复杂物理关系影响的区域,并保留未受影响的区域。
如下图所示,该过程从用户输入开始,通过基于 VLM 的推理阶段生成 quadmask,随后进行两阶段生成过程。
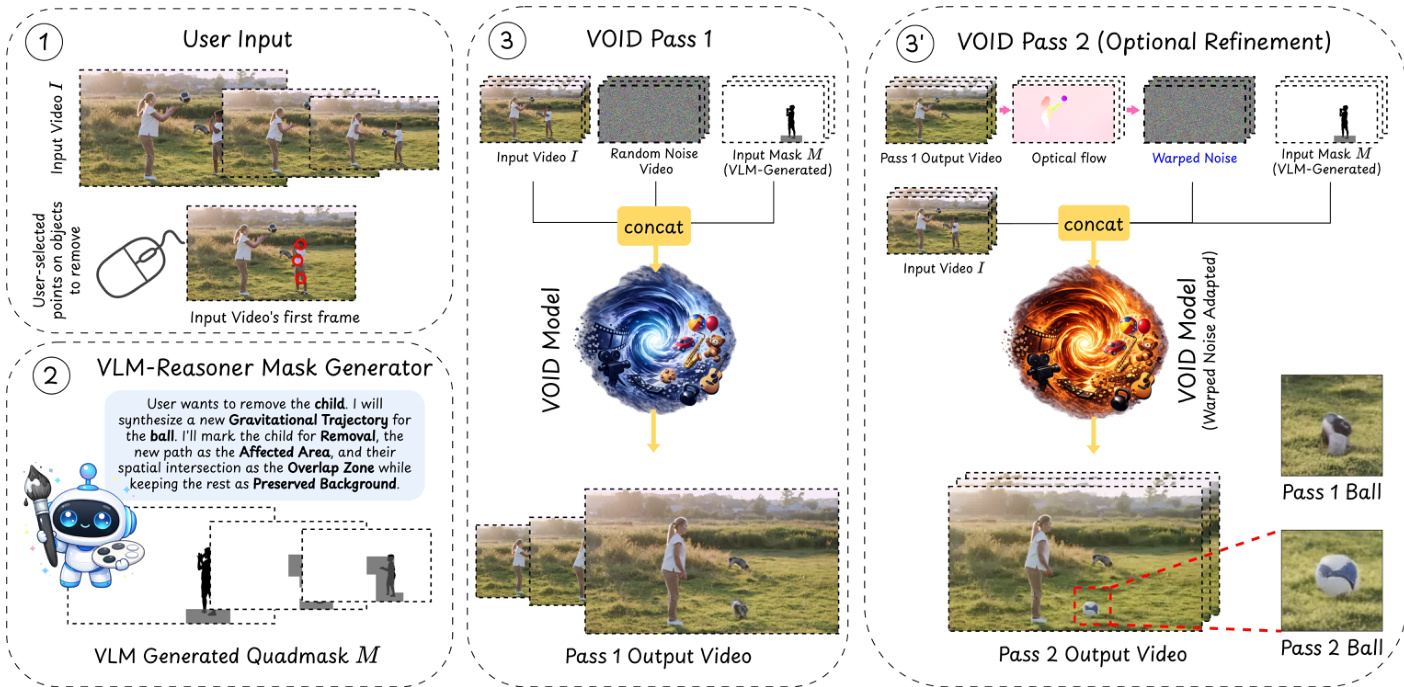
为了提供精确引导,本文引入了 Interaction-Aware Quadmask Conditioning。虽然之前的 trimask 方法区分了待移除物体、受影响区域和保留区域,但它们在受影响区域的尺度以及目标物体与动态效应之间的重叠方面经常存在歧义。本文通过将 trimask 扩展为 quadmask Mq 来解决此问题,该 quadmask 具有第四个类别:深灰色,专门用于描述待移除物体与其他受影响场景部分之间的重叠。
VOID 架构构建在 CogVideoX diffusion transformer 主干网络之上,并使用来自 Generative Omni-matte 的权重进行初始化,从而为分层物体效应解耦提供强大的先验。生成过程分两个不同的阶段进行。
在第一阶段,VOID 生成初始的反事实预测:
V^d1=VOID(z,V,Mq)
其中 z∼N(0,I) 是高斯 diffusion noise。这一阶段捕捉了广泛的运动假设,例如物体进入自由落体状态。然而,由于轻量级 diffusion models 在复杂运动期间可能难以维持时间一致性,第一阶段的物体可能会表现出结构变形或拉伸。
为了缓解这一问题,本文实现了一个可选的第二阶段,称为 Flow-Warped Noise Stabilization。只有当 Vision-Language Model (VLM) 检测到移除操作将引起显著的动态重构时,才会触发此阶段。第二阶段利用了模型的 warped noise 变体:
V^=VOIDwarp(zwarp,V,Mq)
其中 zwarp 衍生自第一阶段输出 V^p1 的光流场。通过使用与预测运动轨迹对齐的时间相关 noise,可以促使模型进行一致的去噪,从而保持物体的刚性和结构完整性。
在推理时,quadmask Mq 通过 VLM 引导的流水线构建。VLM 分析视频和初始 mask,以识别受影响的物体,并使用粗略的空间网格预测它们的反事实位置。这些预测与来自 Segment Anything 3 的 mask 相结合,以定义最终的受影响区域,然后将其映射到 quadmask 颜色方案中。
实验
评估采用了人类偏好研究、基于 VLM 的自动评判,以及在真实世界和合成基准测试上的性能指标,以评估模型执行物理感知视频物体移除的能力。这些实验验证了该框架不仅能够移除物体,还能模拟场景中产生的因果变化,例如改变的碰撞或释放后进入自由落体的物体。结果表明,所提出的方法通过实现卓越的物理合理性和对未知交互效应的泛化能力,显著优于传统的 inpainting 和 text-guided editing models。
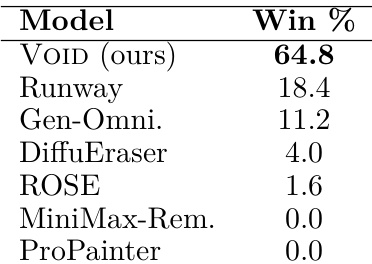
本文进行了一项人类偏好研究,以评估不同模型处理视频物体移除及其后续物理效应的真实程度。结果显示,参与者对所提出的 VOID 模型的偏好次数显著高于所有其他测试的基线模型。VOID 在真实场景的所有评估模型中获得了最高的胜率。所提出的方法优于商业 text-guided editing 系统。相比之下,传统的 inpainting 和移除模型获得的偏好极低。
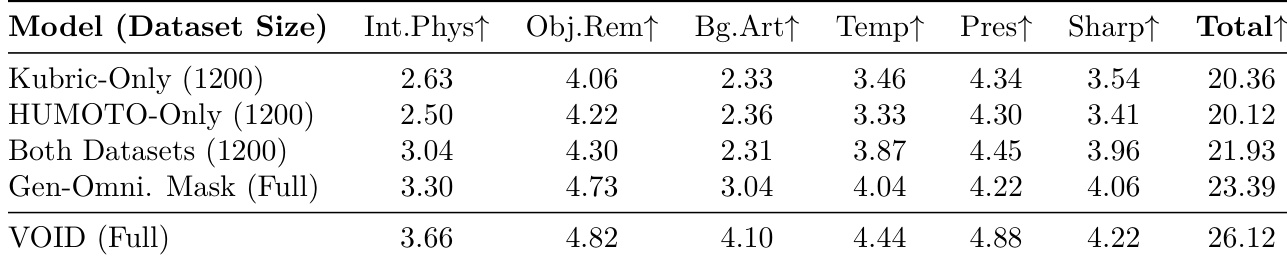
本文进行了一项消融实验,以评估两阶段视频外观优化器的影响。结果表明,应用第二阶段可以提高大多数评估指标的性能,包括交互与物理、物体移除以及时间一致性。与第一阶段相比,第二阶段带来了更高的总分。在处理交互与物理的能力方面观察到了改进。第二阶段增强了物体移除和时间一致性。

本文进行了一项消融实验,以评估数据集组成和 masking 策略对模型性能的影响。结果表明,结合多个数据集并利用详细的 quadmask 策略可以显著提高所有评估类别的得分。同时在 Kubric 和 HUMOTO 数据集上进行训练比单独使用其中一个数据集效果更好。在所有评分标准中,quadmask 策略均优于使用细节较少的 trimasks。完整的 VOID 框架在所有测试配置中获得了最高总分。
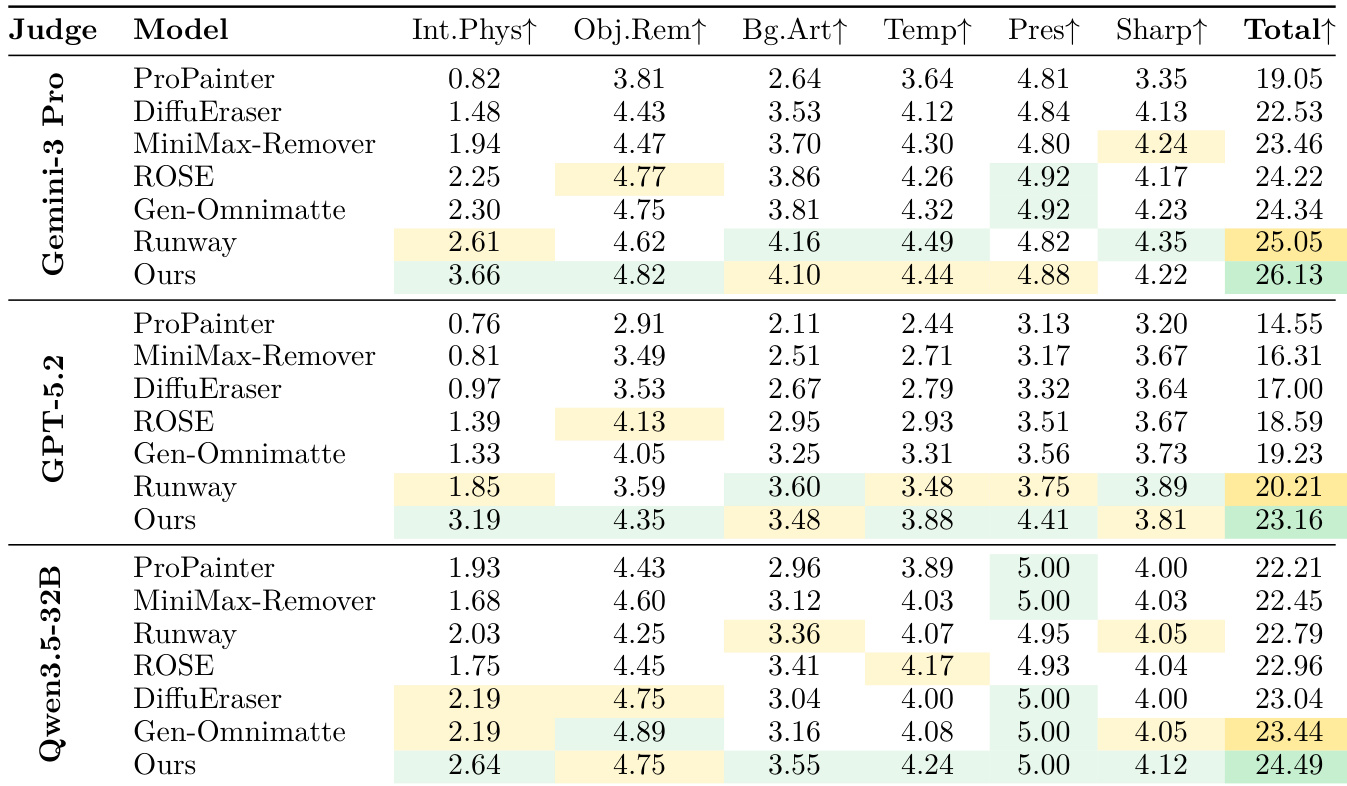
本文在包含阴影、反射和动态交互移除的合成基准测试上,将模型与多个基线进行了对比评估。结果显示,所提出的方法在大多数指标上均实现了卓越的性能,特别是在视频级和语义评估方面。与所有基线方法相比,所提出的模型在 FVD 和 VLM-Judge 得分方面表现出显著提升。在对比的方法中,该模型在 DINOv2 和 PSNR 方面获得了最高分。虽然模型在大多数类别中表现出色,但并未获得最低的 LPIPS 分数,这归因于该指标对局部空间平移的敏感性。
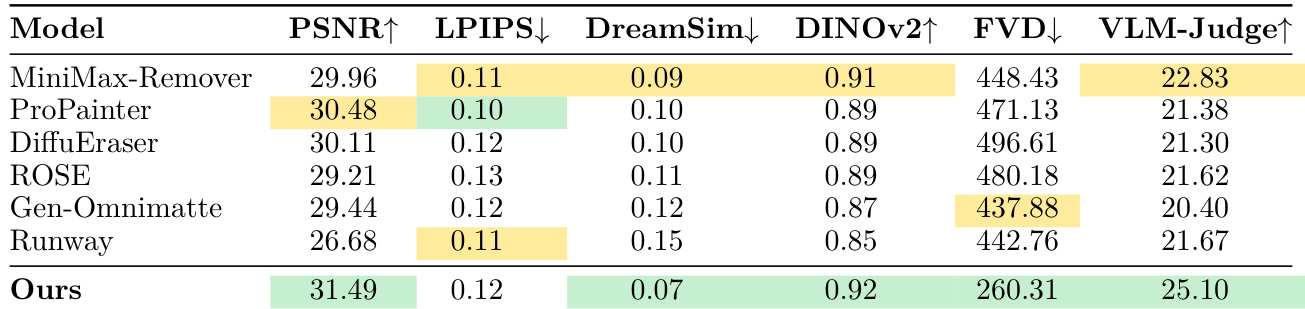
本文在真实世界视频编辑任务上,使用三种不同的 vision-language model 评判器将模型与多个基线进行了对比评估。结果显示,所提出的方法在所有评判器中均获得了最高的总分,展示了在处理物理交互和物体移除方面的卓越性能。在所有三个 vision-language 评判器的总分类别中,所提出的模型均优于所有基线。与现有方法相比,该模型在建模物理交互和物体移除方面显示出显著优势。性能增益在不同的自动评判器(包括 Gemini Pro, GPT-5.2 和 Qwen-3.5-32B)中保持一致。
通过人类偏好研究、消融实验和自动基准测试,本文评估了 VOID 模型在处理视频物体移除和物理交互方面的有效性。结果表明,所提出的框架通过保持卓越的时间一致性和真实的物理效应,显著优于现有的基线模型和商业系统。关键的架构组件,如两阶段外观优化器、多样化的数据集组成以及详细的 quadmask 策略,被证明对于实现高质量、语义准确的视频编辑至关重要。