Command Palette
Search for a command to run...
SKILL0:用于技能内化的上下文智能体强化学习
SKILL0:用于技能内化的上下文智能体强化学习
Zhengxi Lu Zhiyuan Yao Jinyang Wu Chengcheng Han Qi Gu Xunliang Cai Weiming Lu Jun Xiao Yueting Zhuang Yongliang Shen
摘要
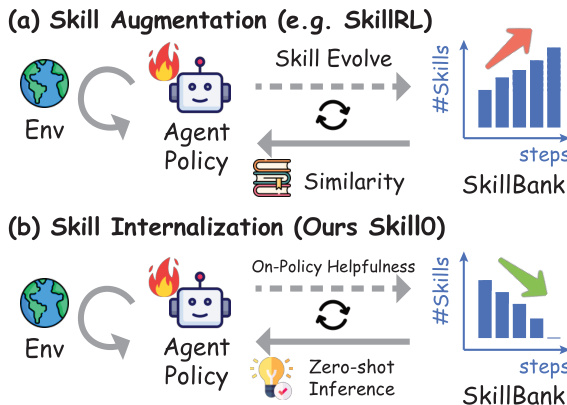
Agent 技能(Agent skills)——即代理在推理阶段动态加载的、包含程序化知识与可执行资源的结构化包——已成为增强 LLM Agent 能力的可靠机制。然而,基于推理时的技能增强存在根本性局限:检索噪声会引入无关引导,注入的技能内容带来显著的 token 开销,且模型并未真正习得其所遵循的知识,而仅是被动执行。我们提出:能否将技能内化至模型参数中,从而在无需任何运行时技能检索的情况下实现零样本(zero-shot)自主行为?为此,我们提出 SKILL0,一种专为技能内化设计的上下文强化学习(in-context reinforcement learning)框架。SKILL0 引入了一种训练阶段的课程学习机制:初始阶段提供完整的技能上下文,随后逐步撤除。技能按类别离线分组,并结合交互历史渲染为紧凑的视觉上下文,以教导模型进行工具调用与多轮任务完成。随后,动态课程(Dynamic Curriculum)评估每个技能文件的在线策略(on-policy)有效性,仅保留在当前策略仍能从线性衰减预算中获益的技能,直至 Agent 在完全零样本设定下运行。大量代理实验表明,SKILL0 相较于标准强化学习(RL)基线实现了显著提升(ALFWorld 提升 +9.7%,Search-QA 提升 +6.6%),同时保持每步少于 0.5k tokens 的高效上下文占用。我们的代码已开源:https://github.com/ZJU-REAL/SkillZero。
一句话总结
来自浙江大学、美团和清华大学的 researchers 提出了 SKILL0,这是一种通过动态课程将智能体技能内化为模型参数的上下文强化学习框架。该方法消除了运行时检索噪声和 token 开销,实现了高效的零样本自主行为,并在智能体基准测试中取得了显著的性能提升。
主要贡献
- 本文介绍了 SKILL0,一种上下文强化学习框架,将技能内化形式化为明确的训练目标,推动智能体从依赖上下文的执行模式转变为完全自主的零样本行为。
- 提出了一种动态课程机制,用于评估每个技能文件的策略内(on-policy)有用性,自适应地仅在当前策略不再受益时撤回指导,直到智能体能够在没有任何外部技能上下文的情况下运行。
- 在 ALFWorld 和 Search-QA 上的大量实验表明,该方法在保持每步少于 0.5k token 的高效上下文的同时,相比标准强化学习基线实现了显著的性能提升。
引言
大型语言模型智能体目前依赖于推理时的技能增强,即检索结构化的行为原语并将其注入提示中以指导复杂任务。虽然这种方法有效,但它存在检索噪声污染上下文、显著的 token 开销限制可扩展性,以及能力依赖于提示而非模型本身的根本性依赖问题。作者提出了 SKILL0,这是首个旨在将这些技能直接内化到模型参数中的强化学习框架,使智能体在推理时无需外部指导即可自主运行。他们通过上下文强化学习实现这一目标,在训练 rollout 期间提供技能脚手架,并通过动态课程系统地移除它,该课程仅在策略不再从中受益时撤回支持。
数据集
-
数据集构成与来源:作者在两个主要基准上评估了他们的方法:ALFWorld,一个包含 6 个家庭活动类别共 3,827 个任务实例的文本游戏;以及基于搜索的问答(Search-based QA),它聚合了单跳数据集(NQ, TriviaQA, PopQA)和多跳数据集(HotpotQA, 2Wiki, MuSiQue, Bamboogle)。
-
训练数据选择与划分:对于 ALFWorld,训练数据遵循 GiGPO 的划分;而 Search-QA 训练专门从 NQ 和 HotpotQA 中抽取作为域内数据,其余问答数据集则用于域外评估。
-
训练配置与混合:Qwen2.5-VL 系列模型使用 4 张 H800 GPU 训练最多 180 步。ALFWorld 设置每个提示采样 16 个任务,每个任务 8 次 rollout,最大长度为 3,072 token;而 Search-QA 设置每批采样 128 个任务,最大长度为 4,096 token。
-
视觉上下文与渲染策略:作者通过以特定尺寸和宽度约束(ALFWorld 为 10pt/392px,Search-QA 为 12pt/560px)的等宽字体渲染文本来构建视觉上下文。他们应用了一种语义颜色编码方案,其中任务指令显示为黑色,观察结果为蓝色,动作或搜索查询为红色,以帮助视觉编码器区分状态、动作和检索内容。
-
课程与技能初始化:实施了包含三个阶段和 1,000 个示例验证子集的课程学习计划。SkillBank 使用来自 SkillRL 的技能进行初始化,为两个环境提供结构化的过程知识。
方法
作者介绍了 SKILL0,这是一个旨在将智能体技能内化为模型参数的框架,实现了无需运行时技能检索的零样本自主行为。与积累技能并产生 token 开销的传统技能增强不同,SKILL0 逐步撤回外部指导。请参阅框架图以比较标准技能增强与提出的技能内化方法。
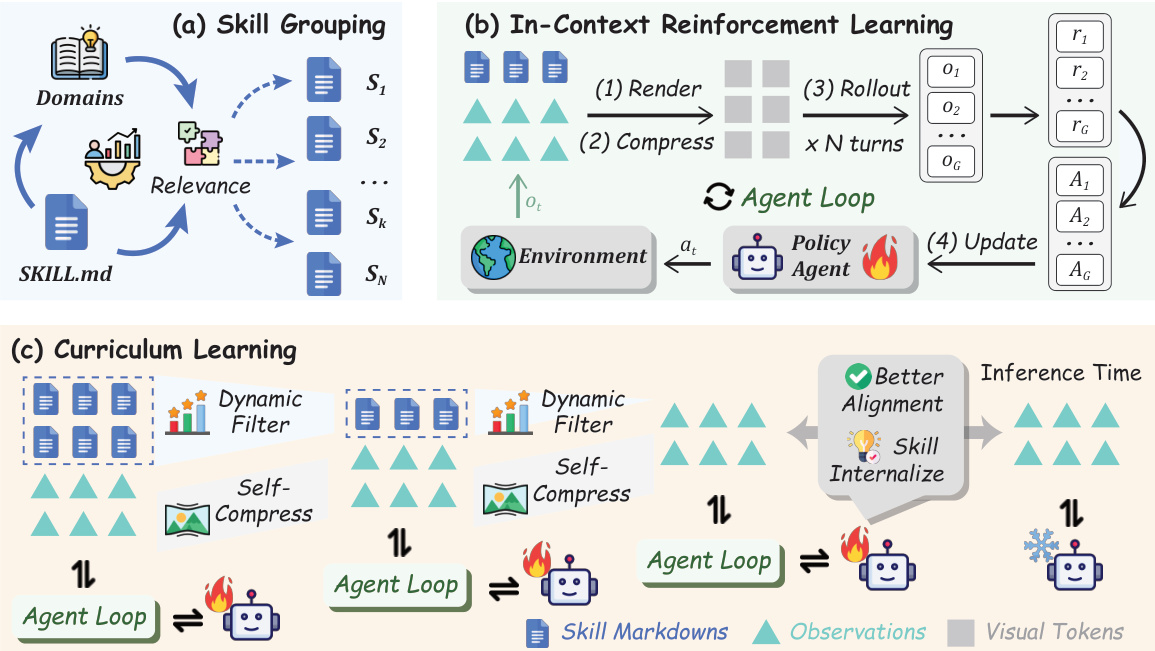
整体架构集成了技能分组、上下文强化学习和自适应课程学习。如下图所示,该过程始于离线技能分组,将领域映射到相关的技能文件。在智能体循环期间,文本交互历史和技能被渲染为紧凑的视觉上下文。课程学习组件根据策略内有用性动态过滤技能,随时间减少技能预算,直到智能体在完全零样本设置下运行。
为了促进这一过程,智能体通过定义任务、历史和所需输出格式的特定提示进行指令引导。下面提供了用于基于搜索的问答任务的提示结构示例。
 该提示要求智能体进行推理,选择诸如调用搜索引擎或提供答案等操作,并指定下一个图像压缩因子。
该提示要求智能体进行推理,选择诸如调用搜索引擎或提供答案等操作,并指定下一个图像压缩因子。
训练过程利用上下文强化学习(ICRL),采用复合奖励函数联合优化任务成功率和压缩效率。奖励定义为:
rtcomp={ln(ct),0,if Isucc(τ)=1,otherwise,r~t=rt+λ⋅rtcomp其中 ct 是压缩比,λ 控制权衡。训练目标遵循 PPO 风格的损失函数:
LSKILL0(θ)=τi∼πθold(q),q∼DE∑i=1G∣τi∣1i=1∑Gt=1∑∣τi∣clip(ri,t(θ),Ai,ϵ)−β⋅DKL[πθ∣∣πref]自适应课程学习通过在每个阶段 s 线性衰减技能预算 M(s) 来管理技能上下文:
∣S(s)∣≤M(s)=⌈N⋅NS−1NS−s⌉这确保了随着智能体从依赖外部技能过渡到独立运行,策略的分布偏移保持平滑。
实验
- 主要性能实验验证了 SKILL0 在 ALFWorld 和 Search-QA 上显著优于零样本、技能增强和记忆增强基线,证明了复杂的推理和工具使用行为已成功内化到模型参数中,无需在推理期间依赖外部提示。
- 训练动态分析证实了明显的技能内化趋势,即模型最初受益于技能脚手架,但随着课程减少外部支持,逐渐在无技能设置下实现更优越的性能,证明该方法学习的是稳健的内部知识而非表面的提示依赖。
- 关于技能预算和动态课程设计的消融研究表明,具有有用性驱动过滤的渐进退火策略对于稳定学习至关重要,因为静态或未过滤的技能集会导致性能崩溃或过度依赖提示,而所提出的方法确保了有效的知识迁移。
- Token 效率评估显示,SKILL0 实现了最先进的结果,与基于文本或技能增强的方法相比,上下文 token 成本大幅降低,突显了视觉上下文建模和技能内化带来的效率提升。
- 在域外多跳数据集上的泛化测试表明,该方法在未见过的推理任务上保持了强大的性能,无需特定领域的适应,证实了其在不同基准测试中的鲁棒性和适应性。