Command Palette
Search for a command to run...
Adam's Law:Large Language Models 上的文本频率定律
Adam's Law:Large Language Models 上的文本频率定律
Hongyuan Adam Lu Z.L. Victor Wei Zefan Zhang Zhao Hong Qiqi Xiang Bowen Cao Wai Lam
摘要
虽然文本频率(textual frequency)在人类阅读速度相关的认知研究中已得到验证,但其与 Large Language Models (LLMs) 的相关性却鲜有研究。据我们所知,本文针对文本数据频率这一研究尚不充分的领域,提出了一个全新的研究方向。我们的框架由三个单元组成。首先,本文提出了文本频率定律(Textual Frequency Law, TFL),该定律指出:在 prompting 和 fine-tuning 过程中,应当优先使用高频的文本数据。由于许多 LLMs 的训练数据是不开源的,我们建议利用在线资源来估算句子层面的频率。随后,我们利用输入改写器(input paraphraser)将输入改写为频率更高的文本表达方式。其次,我们提出了文本频率蒸馏(Textual Frequency Distillation, TFD),通过查询 LLMs 来进行故事补全,从而进一步扩展数据集中的句子,并将生成的语料用于修正初始的频率估算。最后,我们提出了课程文本频率训练(Curriculum Textual Frequency Training, CTFT),按照句子频率递增的顺序对 LLMs 进行 fine-tuning。我们在自主构建的文本频率配对数据集(Textual Frequency Paired Dataset, TFPD)上,针对数学推理、机器翻译、常识推理以及 agentic tool calling 任务进行了实验。结果证明了我们框架的有效性。
一句话总结
FaceMind 公司和香港中文大学的研究人员提出了文本频率定律框架,该框架通过文本频率蒸馏和课程文本频率训练优先处理高频文本数据,从而优化大语言模型的提示和微调,并在精心策划的文本频率配对数据集上证明了其在数学推理、机器翻译、常识推理和 agent 工具调用任务中的有效性。
核心贡献
- 这项工作引入了文本频率定律,该定律指出在大语言模型的提示和微调过程中应优先处理高频文本数据。这一见解指导了数据的选择,以在计算预算约束下优化模型性能。
- 开发了一个综合框架,包括输入改写器以生成高频表达,以及文本频率蒸馏以通过故事补全细化频率估计。该方法还结合了课程文本频率训练,利用句子级频率的递增顺序来微调模型。
- 使用精心策划的文本频率配对数据集在数学推理、机器翻译和 agent 工具调用等任务上提供了实证验证。这些实验的结果证实了优先处理高频改写语料以提高模型性能的有效性。
引言
大语言模型在各种任务上表现出色,但在有限的计算资源下选择最佳训练数据仍然具有挑战性。虽然先前的研究强调了数据质量和数量,但往往忽视了文本频率如何影响语义等价重述之间的性能。作者提出了文本频率定律,建议应优先选择高频文本数据用于提示和微调,因为这些模式在预训练期间出现得更频繁。为了解决无法访问专有训练语料库的问题,他们引入了频率文本蒸馏,通过模型生成来估计句子级频率。最后,团队提出了课程文本频率训练,通过按频率递增的顺序处理数据来微调模型,以获得更好的结果。
数据集
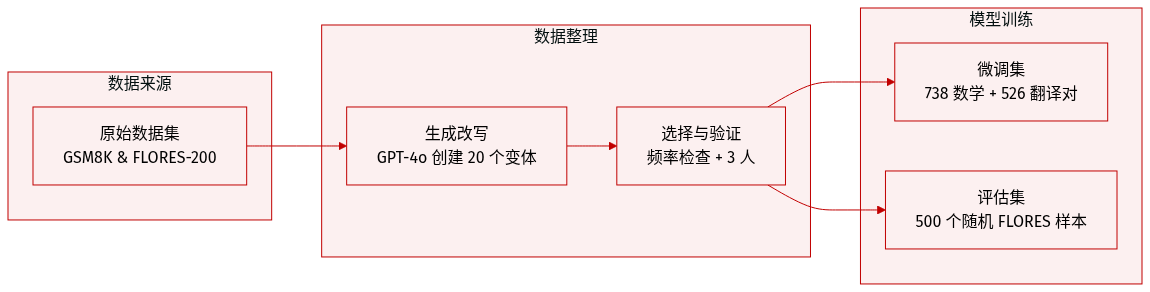
作者开发了文本频率配对数据集 (TFPD) 以解决其研究目标缺乏现有资源的问题。
-
数据集构成和来源
- 该集合来自 GSM8K 用于数学推理,FLORES-200 用于机器翻译,以及 CommonsenseQA 用于常识推理。
- 原始数据集的真实答案被采用且未作修改。
- 每个高频句子与一个低频句子配对。
-
处理和过滤
- GPT-4o-mini 使用创建常见和较少见表达而不省略单词的指令,为每个句子生成了 20 个改写版本。
- 系统根据 Zipf 频率估计选择了频率最低和最高的两个句子。
- 三位拥有英语语言学学位的人工标注员验证了原始句子和改写句子之间的语义等价性。
- 除非所有标注员同意句子含义相同,否则实例将被丢弃。
- 最终数据集包括来自 GSM8K 测试实例的 738 对和来自 FLORES-200 开发测试实例的 526 对。
-
模型使用和评估
- TFPD 用作微调实验的训练数据,以评估文本频率的影响。
- 对于评估,作者从 FLORES-200 开发集中随机选择了 500 个样本。
- 现成的 Zipf 频率资源被用于频率估计任务。
-
语言选择和伦理
- 提示实验利用了从 FLORES-200 中随机选择的 100 种语言,其中一半以上被归类为低资源语言。
- CTFT 实验专注于 Kabuverdianu, Kikuyu, Pangasinan 和 Standard Latvian。
- 该工作遵守 ACL ARR 行为准则,使用知名数据集且未使用外部文本资源进行预处理。
方法
所提出的框架通过三个相互关联的组件运行:文本频率定律 (TFL)、文本频率蒸馏 (TFD) 和课程文本频率训练 (CTFT)。这些组件共同旨在利用句子级文本频率来改进大语言模型 (LLM) 的提示和微调。整体架构旨在识别并优先处理高频文本表达,据假设这些表达与大语言模型的预训练分布更一致,从而增强模型性能。
第一个组件,文本频率定律 (TFL),建立了一个基于句子级频率选择改写语料的原则。作者将句子级频率定义为句子内词级频率的几何平均值,这提供了句子在给定语料库中常见程度的度量。该频率指标用于选择给定输入的最频繁改写语料,无论是用于提示还是微调。对于提示,使用频率最高的输入来从大语言模型生成输出。对于微调,高频输入与期望的真实输出配对,以调整模型参数。这种方法基于论文中提出的理论分析,该分析表明在某些假设下,例如 token 频率的齐夫定律和模型近似真实边缘概率的能力,高频句子往往会产生更低的负对数似然 (NLL) 损失。这一理论基础表明,具有更高文本频率的输入更有可能带来更好的任务性能,因为它们与模型的预训练分布一致。
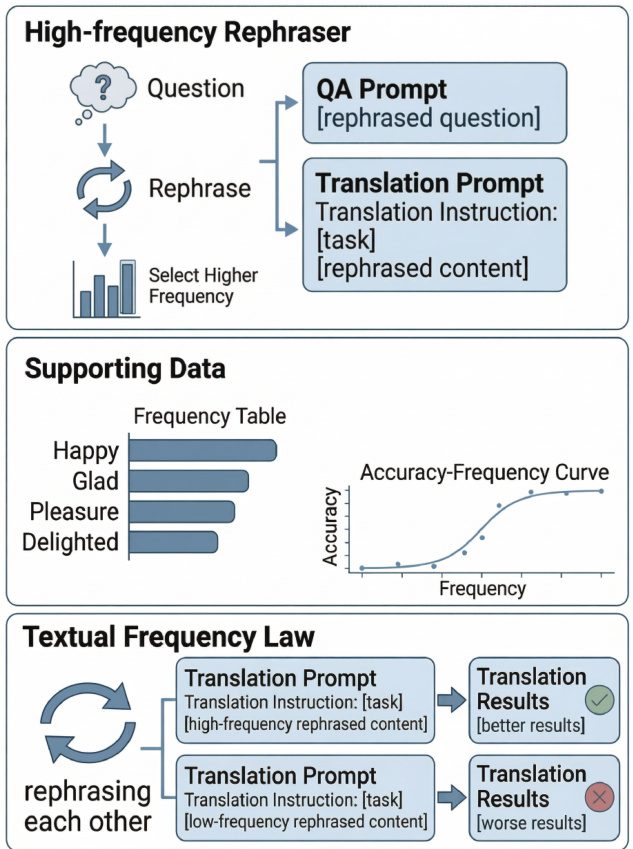
如下图所示,框架从一个高频改写器模块开始。该模块接收初始问题或输入并生成多个改写版本。然后系统使用频率表评估这些改写版本,按句子级频率对其进行排名。选择频率最高的改写版本用于后续步骤。此过程对于确保用于提示和微调的输入数据在文本频率方面具有高质量至关重要。该图还说明了文本频率与模型准确率之间的关系,显示出正相关性,即频率越高性能越好。该曲线支持框架的核心假设,即高频输入会带来更好的结果。
第二个组件,文本频率蒸馏 (TFD),解决了从在线资源获得的频率估计可能无法完美反映大语言模型实际训练数据的局限性,因为后者通常是闭源的。为了细化频率估计,TFD 使用大语言模型本身通过故事补全任务生成额外数据。此过程涉及向大语言模型提供句子并指示其完成故事。生成的数据随后用于创建新的、更精细的频率估计。框架中使用的最终频率是原始估计和蒸馏估计的加权组合,从而允许更准确和稳健的频率度量。这一步计算成本高昂但是可选的,因为即使仅使用初始估计,框架仍然有效。
最后一个组件,课程文本频率训练 (CTFT),将文本频率的使用扩展到改写选择之外,延伸至微调过程。受低频表达可能更多样化的观察启发,CTFT 按句子级频率递增的顺序排列训练数据。这意味着在微调的每个 epoch 期间,模型首先接触低频表达,并逐渐过渡到高频表达。这种课程学习方法旨在帮助模型首先学习更复杂和多样的模式,然后再强化更常见的模式。该方法建立在 TFL 和 TFD 之上,创建了一个更复杂的微调场景,以结构化的方式利用频率信息。
总之,该框架集成了 TFL、TFD 和 CTFT,以通过战略性地使用文本频率来创建改进大语言模型性能的系统方法。这些组件协同工作以选择高频输入、细化频率估计,并以基于课程的方式组织训练数据。理论分析为该方法的有效性提供了基础,而实证结果证明了其在各种任务中的实际好处。
实验
评估设置涉及使用多种闭源和开源大语言模型在数学推理、机器翻译和常识推理任务上进行提示和微调实验。结果一致表明,来自高频文本分区的输入比低频分区产生更优越的性能,从而验证了所提出的频率定律。此外,使用高频数据结合课程文本频率训练进行微调显著提高了模型能力,使这种方法区别于传统的基于复杂度的课程学习。
作者比较了使用高频和低频分区在多个模型和指标上的翻译结果。结果显示,高频数据 consistently 提高了性能,大多数语言对显示出改进,极少出现退化。高频数据在所有模型和指标上提高了翻译性能。大多数语言对显示出改进,极少出现退化实例。改进在 BLEU、chrF 和 COMET 分数上是一致的。
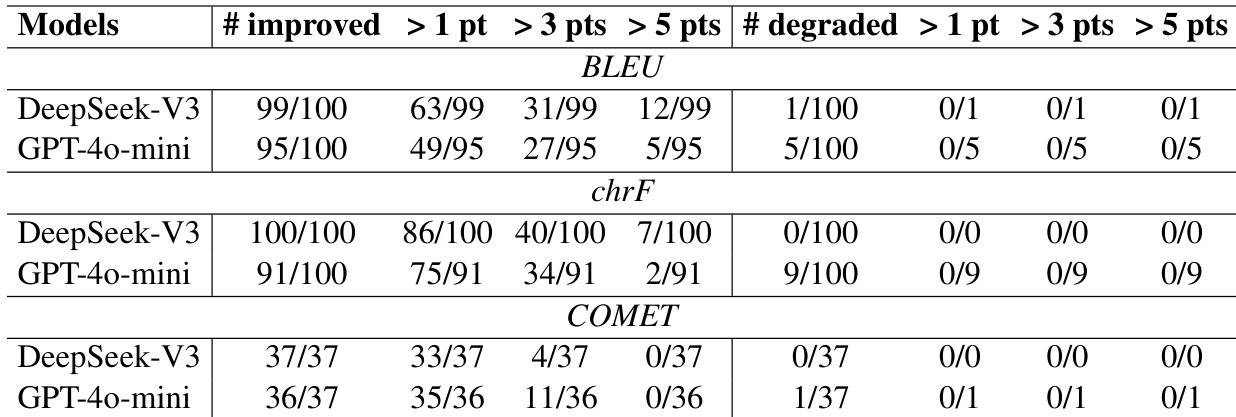
结果显示,高频语言样本在多种语言和指标上 consistently 优于低频样本。改进在提示和微调实验中都很明显,高频数据带来了更好的翻译质量。高频样本 consistently 比低频样本实现更好的翻译性能。来自高频数据的改进在不同模型和评估指标上被观察到。即使是少量的高频数据也有助于显著的性能提升。
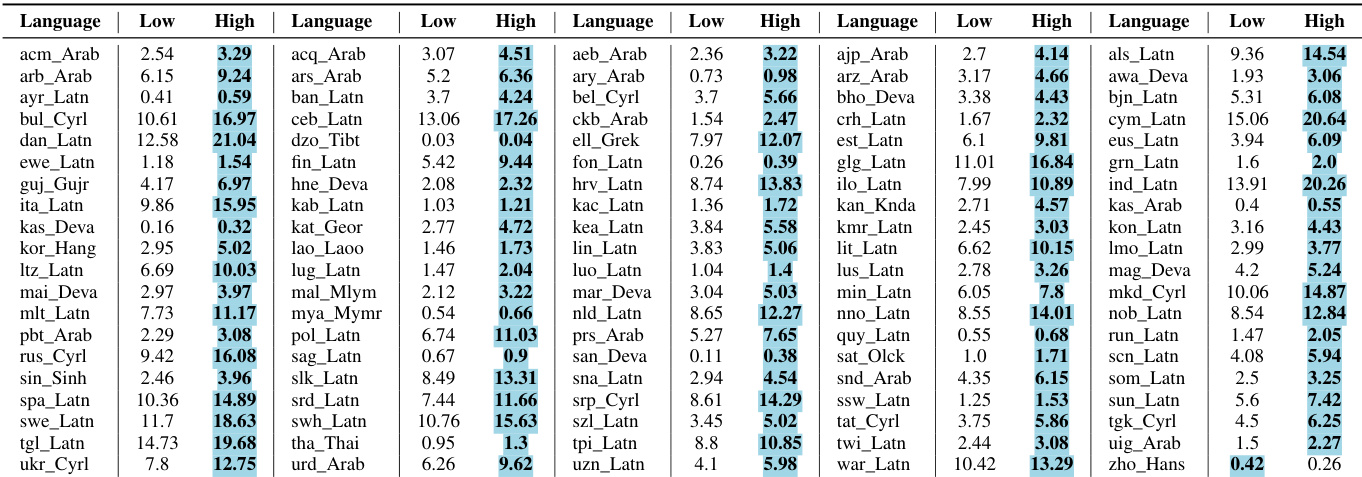
作者比较了使用低频和高频语言对的翻译性能。结果显示,高频输入在多种语言和指标上 consistently 带来更好的翻译结果。改进是显著且广泛的,在任何情况下观察到的退化都极小。高频输入在翻译任务上 consistently 优于低频输入。改进在语言和指标上广泛存在,观察到的退化极小。结果验证了使用高频数据进行翻译的有效性。
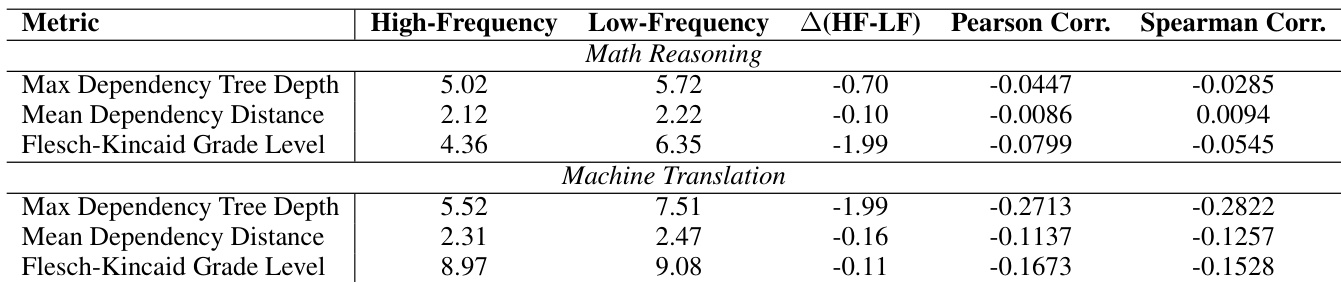
该表比较了数学推理和机器翻译任务中高频数据和低频数据之间的语言指标。结果显示两种数据类型在依赖度量和相关性方面存在一致差异。与低频数据相比,高频数据表现出更低的依赖树深度和距离度量。语言复杂度度量上的差异在机器翻译中比在数学推理中更明显。皮尔逊和斯皮尔曼相关性都表明频率与语言复杂度指标之间存在弱关系。
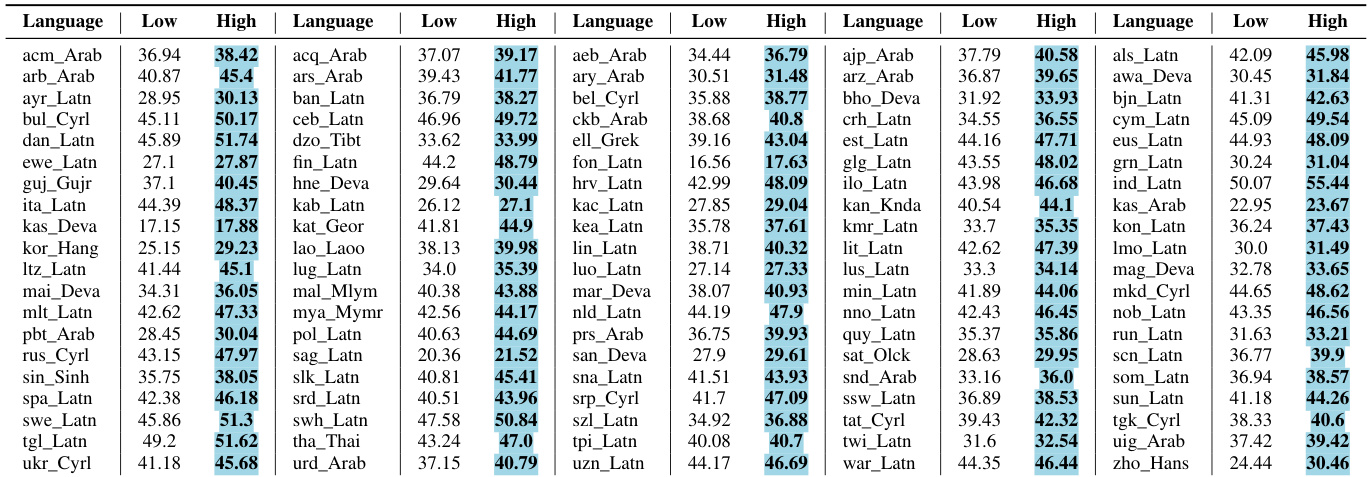
结果显示,高频翻译在多种语言和指标上 consistently 优于低频翻译。改进是显著且一致的,仅在罕见情况下观察到轻微退化。高频翻译在所有语言和指标上比低频翻译实现更好的性能。改进是一致的,大多数语言对在 BLEU、chrF 和 COMET 分数上显示出增强的结果。任何性能退化都是最小的,在大多数情况下限制在不到一个点。

作者通过使用提示和微调方法,在多个模型和指标上比较高频和低频数据分区来评估翻译性能。结果表明,高频数据 consistently 产生更优越的翻译质量,在各种语言对上显示出广泛的改进和极小的退化。语言分析进一步揭示,高频样本表现出更低的依赖复杂度,这一区别在翻译任务中比在数学推理中更明显。这些发现共同验证了利用高频数据增强机器翻译结果的有效性。