Command Palette
Search for a command to run...
OmniVoice: 迈向基于 Diffusion Language Models 的全语种 Zero-Shot Text-to-Speech 研究
OmniVoice: 迈向基于 Diffusion Language Models 的全语种 Zero-Shot Text-to-Speech 研究
Han Zhu Lingxuan Ye Wei Kang Zengwei Yao Liyong Guo Fangjun Kuang Zhifeng Han Weiji Zhuang Long Lin Daniel Povey
摘要
我们推出了 OmniVoice,这是一个规模宏大的多语言零样本(zero-shot)文本转语音(TTS)模型,其覆盖语言规模超过 600 种。该模型的核心是一种新颖的、基于 Diffusion 语言模型风格的离散非自回归(NAR)架构。与传统的离散 NAR 模型不同,传统模型在复杂的两阶段(文本 → 语义 → 声学)pipeline 中往往面临性能瓶颈;而 OmniVoice 则实现了从文本到多 codebook 声学 token 的直接映射。这一简化方案得益于两项关键技术创新:(1) 一种用于高效训练的全 codebook 随机掩码(random masking)策略;(2) 通过预训练 LLM 进行初始化,以确保卓越的语音清晰度(intelligibility)。通过利用完全由开源数据构建的 58.1 万小时多语言数据集,OmniVoice 实现了迄今为止最广泛的语言覆盖范围,并在中文、英文以及各类多语言 benchmark 上均达到了 state-of-the-art 的性能。我们的代码和预训练模型已向公众开放。
一句话总结
OmniVoice 是一个大规模多语言 zero-shot 文本转语音模型,可扩展至 600 多种语言。该模型利用一种新颖的扩散语言模型风格的离散非自回归架构,通过全 codebook 随机掩码和 LLM 初始化,将文本直接映射到多 codebook 声学 tokens,在中文、英文及多种多语言基准测试中实现了最先进的性能。
核心贡献
- 本文介绍了 OmniVoice,一个大规模多语言 zero-shot 文本转语音模型,利用新颖的单阶段离散非自回归架构将文本直接映射到多 codebook 声学 tokens。
- 该工作实现了两项关键技术创新,包括用于提高训练效率的全 codebook 随机掩码策略,以及使用预训练大语言模型初始化模型主干以增强语音可懂度。
- 实验表明,在 58.1 万小时的多语言数据集上进行训练,使模型能够支持超过 600 种语言,并在中文、英文及多种多语言基准测试的可懂度、说话人相似度和自然度方面达到最先进的性能。
引言
Zero-shot 文本转语音 (TTS) 技术对于从极少量音频样本中创建高质量合成语音至关重要,然而目前大多数模型仅限于少数语言。虽然现有的离散非自回归 (NAR) 模型提供了快速推理,但它们通常依赖于复杂的两阶段流水线,容易受到误差传播和信息瓶颈的影响。本文介绍了 OmniVoice,这是一个大规模多语言 zero-shot TTS 模型,通过精简的单阶段架构支持超过 600 种语言。通过利用全 codebook 随机掩码策略并使用预训练大语言模型 (LLM) 权重初始化主干,模型能够以卓越的可懂度和训练效率将文本直接映射到声学 tokens。
数据集
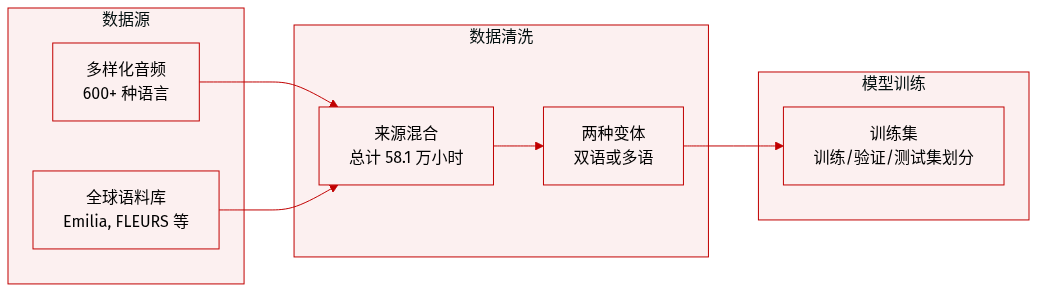
OmniVoice 使用了以下数据配置和基准测试:
- 数据集组成与来源: 训练数据由大规模自建的多语言语料库组成,涵盖 600 多种语言,总计 581,000 小时。该集合集成了多种来源,包括 Emilia、LibriTTS、Common Voice、VoxBox、Meta Omnilingual ASR Corpus、FLEURS、GigaSpeech 2、YODAS-Granary 以及众多的区域性数据集,如 IndicVoices-R、Wenetspeech 以及各种阿拉伯语和藏语语料库。
- 训练配置: 使用了两种不同的训练策略:
- 双语变体: 该版本专门在 Emilia 数据集的中文和英文子集上进行训练。其设计目的是为了与现有的最先进 zero-shot TTS 模型进行公平比较。在此配置中,省略了 prompt 去噪以隔离架构优势。
- 多语言变体: 该版本利用完整的 58.1 万小时多语言数据集,以支持广泛的语言覆盖范围。
- 评估基准: 为了评估性能,使用了四个特定的基准测试:
- LibriSpeech-PC: 英文 zero-shot TTS 的标准基准。
- Seed-TTS: 涵盖中文和英文的双语基准。
- MiniMax-Multilingual-24: 跨越 24 种语言的多语言基准。
- FLEURS-Multilingual-102: 使用 FLEURS 数据集的开发集和测试集来评估 102 种语言的基准,代表了 zero-shot TTS 中语言覆盖范围最广的基准之一。
方法
本文提出了 OmniVoice,一种采用扩散语言模型风格架构设计的单阶段非自回归 (NAR) 文本转语音 (TTS) 模型。与经常受到误差传播和信息瓶颈影响的传统两阶段级联流水线不同,OmniVoice 以端到端的方式将文本直接映射到多 codebook 声学 tokens。
OmniVoice 的架构旨在处理多个输入流以生成高保真语音。输入由一个文本 token 序列 Y(由提供语言和任务导向指导的 instruct 和 transcript tokens 拼接而成)以及一个声学 token 矩阵 X∈RT×C 组成,其中 T 代表时间步数,C 代表 codebook 的数量。该声学矩阵沿时间维度被划分为一个包含前缀声学上下文的 prompt 段 Xprompt,以及一个 token 被替换为特殊掩码 token [M] 的目标掩码段 Xtarget。
参考框架图:
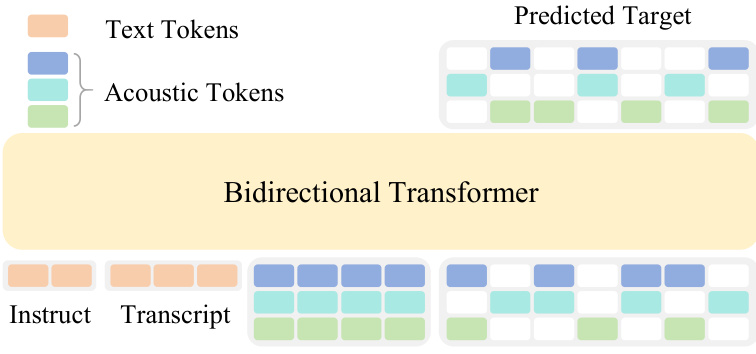
模型使用由预训练 LLM 权重初始化的双向 Transformer 主干。文本 tokens 通过文本嵌入层进行处理,而声学 tokens 通过特定于 codebook 的嵌入层进行处理。为了整合多 codebook 信息,所有 C 个 codebook 在相同时间位置的嵌入在输入 Transformer 之前会被求和为一个统一的嵌入。在输出端,模型采用 C 个独立的、特定于 codebook 的预测头,将最终的隐藏状态投影到每个对应 codebook 的词表概率分布上。
训练过程由离散扩散目标驱动。通过利用文本条件 Y、prompt Xprompt 和未掩码的 tokens,模型被训练以恢复 Xtarget 中掩码位置的原始 tokens。令 M 表示目标段内对应掩码位置的索引集合 (t,c),其中 t∈{Tp+1,…,T} 且 c∈{1,…,C}。训练损失 L 公式如下:
L=−∑(t,c)∈MlogP(xt,c∣X,Y;θ)
其中 xt,c 是时间步 t 和 codebook 索引 c 处的真实声学 token,P(xt,c∣…;θ) 是由参数为 θ 的模型预测的概率分布。
为了提高训练效率,本文摒弃了传统的逐层掩码调度(这种调度在每次迭代中仅优化 token 矩阵的一个稀疏子集)。相反,OmniVoice 采用了全 codebook 随机掩码策略。在这种方法中,对于 T×C token 矩阵中的每一个条目,都会独立采样一个二值掩码 mi,j∼Bernoulli(pt),其中掩码比例 pt 在每次实例中从均匀分布 pt∼U(0,1) 中抽取。该策略确保平均而言有 50% 的 tokens 用于损失计算,从而显著加速收敛并提高生成质量。
实验
评估结合了用于说话人相似度、可懂度和自然度的客观指标以及主观人类评估,以验证 OmniVoice 模型。在英文、中文及广泛多语言基准上的实验表明,该模型达到了商业级性能,即使在低资源语言场景下也表现出强大的泛化能力。消融研究进一步证实,全 codebook 随机掩码、LLM 初始化和 prompt 去噪等关键架构选择对于优化语音质量和语言准确性至关重要。此外,该模型表现出极高的推理效率,在实时生成速度方面优于现有的基线模型。
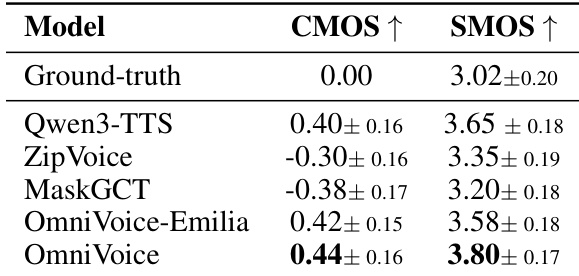
通过使用 CMOS 和 SMOS 指标,将 OmniVoice 及其变体与几种最先进的 TTS 模型进行了主观评估。结果表明,OmniVoice 在相对语音质量和绝对说话人相似度方面均取得了卓越的性能。在所有测试模型中,OmniVoice 在 CMOS 和 SMOS 方面均获得了最高分。OmniVoice-Emilia 在主观质量和相似度方面优于现有的 NAR 基线。多语言 OmniVoice 模型在说话人相似度方面比其他基线模型具有竞争优势。
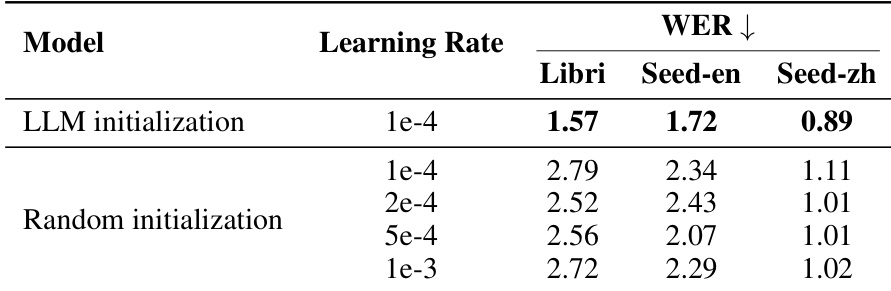
通过将 LLM 初始化与各种随机初始化配置进行对比,评估了 LLM 初始化对模型可懂度的影响。结果显示,与随机初始化相比,使用 LLM 初始化的模型在所有测试数据集上均实现了更低的字错率。无论使用何种学习率,LLM 初始化始终比随机初始化产生更好的可懂度。即使对随机初始化模型进行广泛的学习率微调,LLM 初始化的性能优势依然存在。从预训练 LLM 继承语言知识的好处在英文和中文基准测试中显而易见。
在 FLEURS-Multilingual-102 基准上评估了 OmniVoice 的多语言能力。结果显示,与真实参考音频相比,该模型实现了极高的可懂度和说话人相似度。OmniVoice 的平均字符错误率低于真实音频。该模型展示了极高的可懂度,大量语言满足严格的错误率阈值。在字符错误率低于 5% 和 10% 限制的语言比例方面,OmniVoice 优于真实音频。

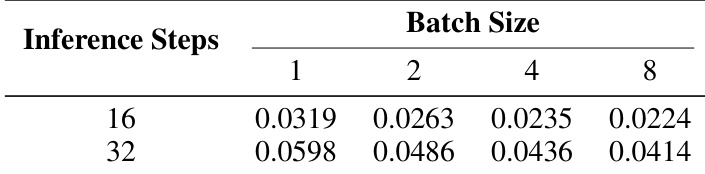
通过测量不同推理步数和 batch size 下的实时因子 (RTF) 来评估 OmniVoice 的推理速度。结果显示,增加 batch size 会降低实时因子,表明在批量推理期间效率更高。在所有测试的推理步数中,较大的 batch size 都会导致较低的实时因子。增加推理步数会导致较高的实时因子。该模型在同时处理多个样本时表现出更高的推理效率。
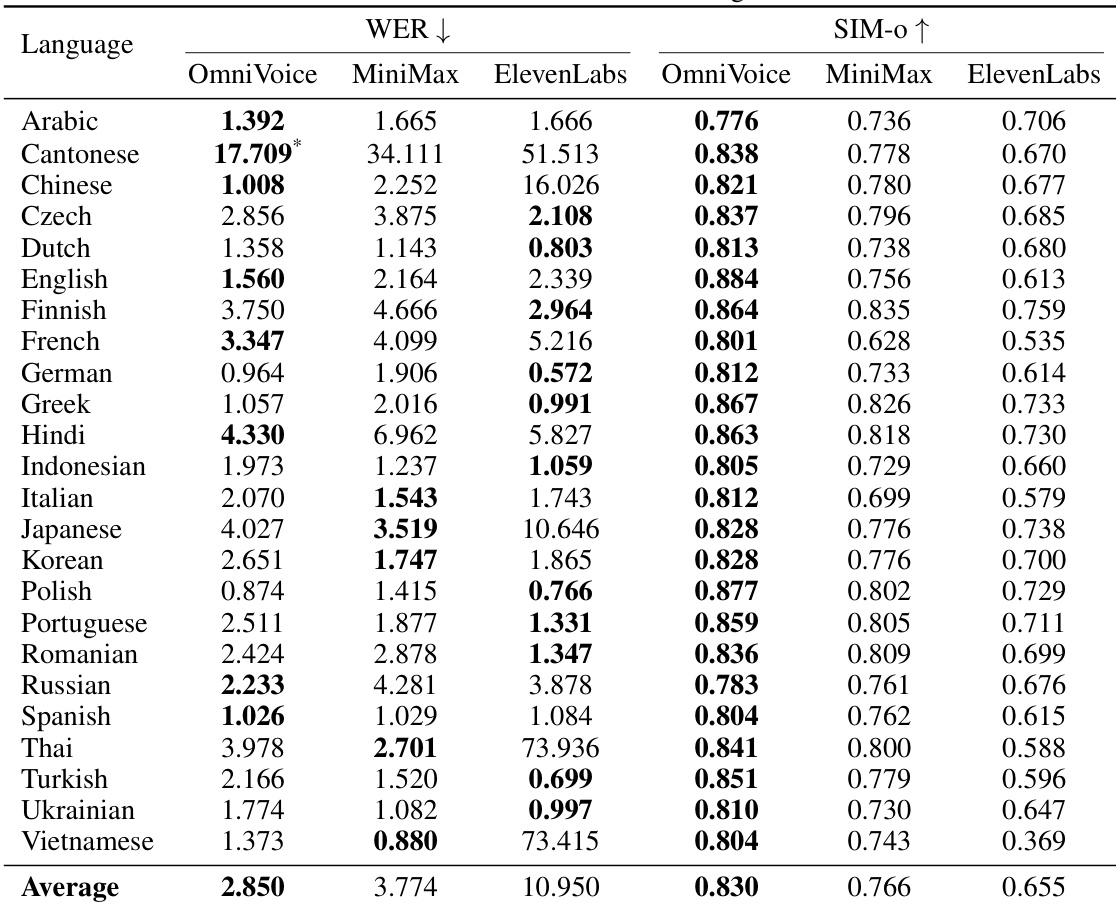
使用字错率 (WER) 和说话人相似度 (SIM-o) 指标,在多种语言下将 OmniVoice 与 ElevenLabs 进行了对比。结果表明,OmniVoice 在广泛的语言范围内,在可懂度和说话人相似度方面均达到了具有竞争力的或更优的性能。在评估的语言中,OmniVoice 的平均 WER 低于 ElevenLabs。该模型表现出比 ElevenLabs 基线更高的平均说话人相似度。OmniVoice 在不同的语言组中均保持了强大的可懂度和相似度性能。
通过一系列主观和客观评估,验证了 OmniVoice 的语音质量、说话人相似度、多语言能力和推理效率。通过与最先进模型和基线的对比,结果证明 OmniVoice 在多种语言中提供了卓越的可懂度和相似度,尤其是在利用 LLM 初始化来继承语言知识时。此外,该模型在批量推理期间表现出高效率,并保持了相对于商业基准的竞争性能。