Command Palette
Search for a command to run...
MiroEval:多模态深度研究 Agent 的过程与结果基准测试
MiroEval:多模态深度研究 Agent 的过程与结果基准测试
摘要
深度研究系统的近期进展令人瞩目,但评估体系仍滞后于实际用户需求。现有基准测试主要依赖固定评分标准对最终报告进行评估,未能有效考察底层的科研过程。此外,大多数基准测试在模态覆盖方面较为有限,依赖无法反映真实世界查询复杂度的合成任务,且难以随知识演进进行更新。为弥补上述不足,我们提出了 MiroEval——一个面向深度研究系统的基准测试与评估框架。该基准包含 100 项任务(70 项纯文本任务,30 项多模态任务),均基于真实用户需求构建,并通过支持周期性更新的双路径 pipeline 实现动态演进的评估环境。我们提出的评估套件从三个互补维度对深度研究系统进行评估:一是基于任务特定 rubrics 的自适应合成质量评估;二是通过主动检索与推理(涵盖网络来源及多模态附件)实现的智能体事实性验证;三是以过程为中心的评估,审计系统在调查全过程中的搜索、推理与优化行为。对 13 个系统的评估得出了三项主要发现:首先,这三个评估维度能够捕捉系统能力的互补方面,各自揭示了不同系统独特的优势与短板;其次,过程质量是整体结果的可靠预测指标,同时能暴露输出级指标无法察觉的缺陷;最后,多模态任务带来了显著更大的挑战,大多数系统在此类任务上的得分下降 3 至 10 分。MiroThinker 系列表现出最为均衡的性能,其中 MiroThinker-H1 在两种设置下均取得整体最高排名。人工验证与鲁棒性测试结果进一步证实了该基准测试与评估框架的可靠性。MiroEval 为下一代深度研究智能体提供了一种全面的诊断工具。
一句话总结
MiroMind 团队推出了 MiroEval,这是一个面向深度研究智能体的动态基准测试,它独特地评估了文本和多模态任务中的自适应综合能力、智能体事实性以及研究过程,揭示了过程质量能够预测结果,同时也暴露了多模态推理中的重大挑战。
主要贡献
- 本文介绍了 MiroEval,这是一个包含 100 个任务的基准测试,这些任务基于真实的用户需求构建,通过精心策划的真实查询和基于实时网络趋势的自动化流程生成,以确保时效性。
- 提出了一种多层评估框架,通过自适应综合质量标准、针对实时来源的智能体事实性验证,以及跨五个内在维度的以过程为中心的研究轨迹审计,对深度研究智能体进行评估。
- 在 13 个领先系统上的实验表明,过程质量是整体结果的可靠预测指标,同时揭示了输出级指标无法察觉的弱点,如分析深度不足和可追溯性存在显著差距。
引言
从被动文本生成向能够自主进行深度研究的智能体系统的快速转变,在金融和医疗等高利害领域产生了对可靠评估的迫切需求。当前的基准测试存在不足,因为它们主要评估最终报告而缺乏对底层研究过程的审计,缺乏强大的多模态支持,并且依赖无法捕捉现实世界复杂性的合成查询。为了弥补这些差距,作者推出了 MiroEval,这是一个包含 100 个现实世界任务的动态基准测试,从三个层面评估系统:自适应综合质量、针对实时来源的智能体事实性验证,以及以过程为中心的研究轨迹审计。
数据集
-
数据集构成与来源 作者推出了 MiroEval,这是一个包含 100 个深度研究任务的基准测试,基于真实的用户需求。该数据集通过双路径流程构建,以确保多样性和时效性,包含 70 个纯文本查询和 30 个多模态查询,涵盖 12 个领域和 10 种任务类型。
-
每个子集的关键细节
- 用户衍生子集(65 个查询): 该集合包含 35 个纯文本任务和 30 个多模态任务,灵感来源于内部系统测试的模式。它涵盖了所有 8 个评估特征,具有平衡的难度层级(简单、中等、困难),并要求处理图像、PDF 和电子表格等附件。
- 自动化子集(35 个查询): 该集合完全由基于趋势的管道利用实时网络数据生成的纯文本任务组成。它针对 12 个主题和 36 个子主题,以确保查询反映当前事件,并需要超出参数知识的外部调查。
-
数据使用与处理 该基准测试作为一个整体评估框架而非训练集使用,从三个维度评估 13 个系统:自适应综合质量、智能体事实性验证和以过程为中心的审计。作者对自动化子集采用了三阶段过滤流程,包括搜索验证、深度研究必要性检查以及逆向质量评估,以确保查询无法仅由模型回答。
-
隐私、元数据与构建策略
- 隐私保护重写: 不直接使用原始用户查询。作者应用严格的匿名化处理,将所有命名实体替换为逼真的替代项,并在重写前过滤掉敏感内容。
- 元数据构建: 每个查询都标注了领域标签、任务类型以及特定于来源的元数据,如特征向量、难度层级和基线质量分数。
- 时效性刷新: 双路径设计允许定期重新执行,使基准测试能够纳入新的用户模式和最新的网络趋势,防止过时。
方法
MiroEval 框架建立了一个多层、智能体的评估流程,以提供对深度研究系统的严格诊断。该方法将研究产物与底层调查程序解耦,从而能够在三个关键维度上进行整体评估。该框架动态构建针对每个任务的具体约束和模态量身定制的评估标准。
评估流程分为三个主要部分,如下图所示:
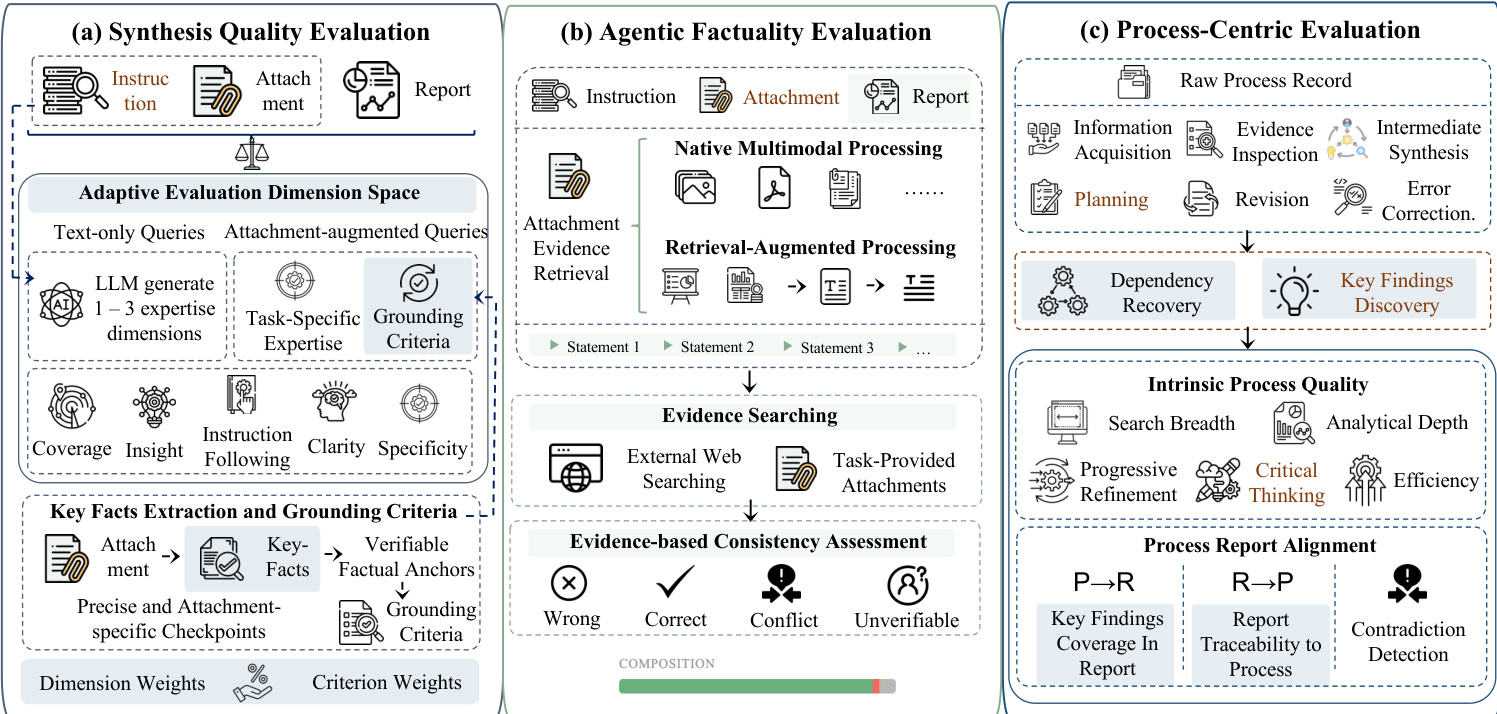
全面的自适应综合质量评估 深度研究系统通过多步检索和推理生成长篇报告。为了捕捉不同领域和模态下的综合质量,该框架采用自适应评估维度空间 D=Dfixed∪Ddynamic(Q)。固定部分包括覆盖范围、洞察力和清晰度等通用方面。动态部分则根据查询类型进行调整。对于纯文本查询,大语言模型(LLM)生成 1–3 个特定于任务的专家维度。对于增强附件的查询,则增加一个“落地性(Grounding)”维度,以评估报告是否忠实地利用了提供的材料。上游模块从附件中提取关键事实,形成可验证的事实锚点,从而指导精确落地标准的生成。评估器推导出维度级权重 Wd 和标准级权重 wd,c 以计算最终质量分数: Squality=∑d∈DWd∑cwd,csd,c 其中 sd,c 是 LLM 为特定标准分配的分数。
智能体事实性评估 该组件评估生成报告中的主张是否得到来自异构来源的可靠证据支持。系统将报告分解为一组可验证的陈述 S(Q,R)。对于每个陈述,评估智能体从外部网络资源和任务提供的附件中检索支持或反驳的证据。该框架通过原生多模态处理支持可直接解释格式的附件查询,并通过检索增强处理支持需要分割的格式。智能体评估每个陈述与其证据集之间的一致性,并分配事实性标签 ψ(s)∈{RIGHT,WRONG,CONFLICT,UNKNOWN}。CONFLICT 标签明确捕捉了来自不同来源的证据导致不一致结论的情况。
以过程为中心的评估 除了最终产物外,该框架还评估底层研究过程的质量。原始过程记录被转换为原子单元的结构化表示,例如信息获取和规划。内在过程质量在搜索广度、分析深度、渐进式细化、批判性思维和效率等维度上进行评估。此外,该框架还评估过程级关键发现与报告级关键发现之间的一致性。这包括过程→报告(P→R)检查,以确保发现已在报告中实现;报告→过程(R→P)检查,以验证报告结论是否得到过程支持;以及矛盾检测,以评估冲突如何处理。总体过程分数定义为: Sprocess=αSintrinsic(P)+(1−α)Salign(P,R) 其中 Sintrinsic 表示内在过程质量分数,Salign 表示一致性分数。
实验
- 在纯文本和多模态设置下评估了 13 个深度研究系统,验证了过程质量能够可靠地预测整体结果,揭示了强大的研究过程与更好的综合能力和事实性之间存在相关性。
- 证明了综合质量和事实性是两种不同的能力,表明润色过的报告并不能保证事实准确性,且系统往往会在分析深度和事实精确度之间进行权衡,反之亦然。
- 发现多模态任务会显著降低性能,特别是在综合和过程维度上,而事实精确度则保持相对稳定,突显了视觉理解是主要的瓶颈。
- 揭示了当前系统在分析深度和效率方面存在困难,通常检索范围广泛但未能深入调查,并表现出可追溯性差距,即报告内容经常无法追溯回研究过程。
- 确认 MiroThinker 系列通过平衡高主张量与低错误率,并在纯文本和多模态环境中保持稳健性能,在所有维度上实现了持续的竞争力。
- 通过鲁棒性检查和人类研究验证了评估框架,确认自动化排名与专家判断一致,并且在不同的评估模型和提示配置下保持稳定。