Command Palette
Search for a command to run...
LongCat-Next:将模态词汇化为离散 tokens
LongCat-Next:将模态词汇化为离散 tokens
Meituan LongCat Team
摘要
主流的 Next-Token Prediction (NTP) 范式通过离散自回归建模(discrete autoregressive modeling)推动了大语言模型的成功。然而,当代的多模态系统仍以语言为中心,通常将非语言模态视为外部附件,这导致了架构的碎片化以及模态集成效果欠佳。为了突破这一限制,我们提出了 Discrete Native Autoregressive (DiNA),这是一个统一的框架,它将多模态信息表示在共享的离散空间内,从而实现了跨模态的一致且规范的自回归建模。其中的一项核心创新是 Discrete Native Any-resolution Visual Transformer (dNaViT),它能够以任意分辨率进行 tokenization 和 de-tokenization,将连续的视觉信号转化为层级化的离散 tokens。在此基础上,我们开发了 LongCat-Next,这是一个原生多模态模型,它在极少模态特定设计的情况下,通过单一的自回归目标来处理文本、视觉和音频。作为一个工业级的基座模型(foundation model),它能够在单一框架内实现卓越的视觉感知、图像绘制与语音交互能力,并在广泛的多模态 benchmark 上取得了强劲的表现。特别地,LongCat-Next 解决了离散视觉建模在理解任务中长期存在的性能瓶颈,并提供了一种统一的方法来有效调和“理解”与“生成”之间的冲突。广泛的实验表明,离散 tokens 可以普遍地表示多模态信号,并能被深度内化于单一的 embedding 空间中,这为这种统一训练范式提供了深刻的见解。作为迈向原生多模态的一次尝试,我们开源了 LongCat-Next 及其 tokenizer,希望能促进社区进一步的研究与开发。
一句话总结
美团 LongCat 团队推出了 LongCat-Next,这是一个原生多模态模型,利用离散原生自回归 (DiNA) 框架和离散原生任意分辨率视觉 Transformer (dNaViT),将文本、视觉和音频表示为任意分辨率的离散 tokens,超越以语言为中心的限制,调和理解与生成之间的冲突,并在广泛的多模态基准测试中取得强劲表现。
核心贡献
- 该工作引入了离散原生自回归 (DiNA),这是一个统一框架,在共享离散空间内表示多模态信息,以实现跨模态的一致自回归建模。通过将非语言模态集成到单一原则架构中,这种方法超越了以语言为中心的限制。
- 一项关键创新是离散原生任意分辨率视觉 Transformer (dNaViT),它在任意分辨率下执行 tokenization 和 de-tokenization,将连续视觉信号转换为分层离散 tokens。在此基础上,LongCat-Next 在单一自回归目标下处理文本、视觉和音频,仅需最少的模态特定设计。
- 大量实验表明,离散 tokens 可以通用表示多模态信号,并在广泛的多模态基准测试中取得强劲表现。该工作解决了离散视觉建模在理解任务上的性能上限问题,并提供了 LongCat-Next 模型及其 tokenizers 的开源访问。
引言
大型语言模型依赖于离散 next-token 预测,但当前的多模态系统通常将视觉和音频视为外部附件而非原生组件。这种语言加辅助的方法导致架构碎片化和次优集成,阻碍了性能。此外,传统上离散化连续视觉信号会导致信息丢失,限制理解和生成能力。为了解决这些挑战,作者引入了离散原生自回归 (DiNA) 框架,将文本、视觉和音频统一在共享的离散 token 空间内。他们开发了离散原生任意分辨率视觉 Transformer (dNaViT),使用语义编码器和残差量化在任意分辨率下对视觉输入进行 tokenization。这使得 LongCat-Next 能够在单一自回归目标下处理多种模态,同时克服离散视觉建模的性能上限。
数据集

- 视觉理解语料库:作者策划了一个多样化的多模态语料库,包含图像描述、交错图像 - 文本、OCR、定位、STEM 和 GUI 数据,以确保广泛的覆盖和高质量。
- 图像描述数据:三阶段清洗管道应用启发式过滤、LVLM 基于的重新描述和基于 SigLIP 的相似性修剪,仅保留高度准确的匹配。
- 交错数据:此子集结合了通过 CLIP 分数过滤的网页对和通过 ASR 和 OCR 处理的视频片段,以支持细粒度的时间和跨模态学习。
- OCR 数据:数据集由 75% 内部合成数据和 25% 来自 90 多个开源数据集的过滤现实世界数据组成,以确保跨场景鲁棒性。
- STEM 数据:构建涉及 60% 开源数据集和 40% 专有或合成数据,问题陈述被重写以增强多步推理链。
- 定位与计数:团队聚合了十多个公共来源,使用标准化坐标系统创建了约 6000 万个定位样本和 800 万个计数样本。
- 视觉生成策略:内部数据集包含约 3 亿个图像 - 文本对,组织成三个渐进训练阶段,以最大化语义覆盖。
- 第一阶段预训练:多阶段过滤移除近重复和低质量样本,同时 Qwen3-VL-8B 生成具有集成 OCR 信号的结构化描述。
- 第二阶段中期训练:SigLIP2 嵌入和 K-Means 聚类对数据集进行划分,通过对稀疏集群的幂律重加权来重新平衡语义分布。
- 第三阶段监督微调:从语义集群中选择高质量示例,以及高审美和文本丰富的子集,以与复杂的人类指令对齐。
- 音频预训练来源:管道处理 1990 万小时原始网络音频,减少到 320 万小时,同时补充 120 万小时合成语音 - 文本数据。
- 特定任务音频:额外的 40 万小时策划数据集支持专门能力,如副语言感知和音频事件理解。
- 音频处理与格式:技术包括 VAD、强制对齐、说话人嵌入聚类和重新分段,以管理噪声并确保平衡的说话人分布。
- 损失计算:模型在 ASR 和交错任务中省略纯音频模态的损失计算,同时在 TTS 和 INTLV-TA 中计算文本 - 音频模态的联合损失。
方法
所提出的框架采用离散建模方法,其中模态特定 tokenizers 将原始信号转换为离散 ID,允许模态无关的仅解码器骨干网络作为统一多任务学习者。参考框架图。
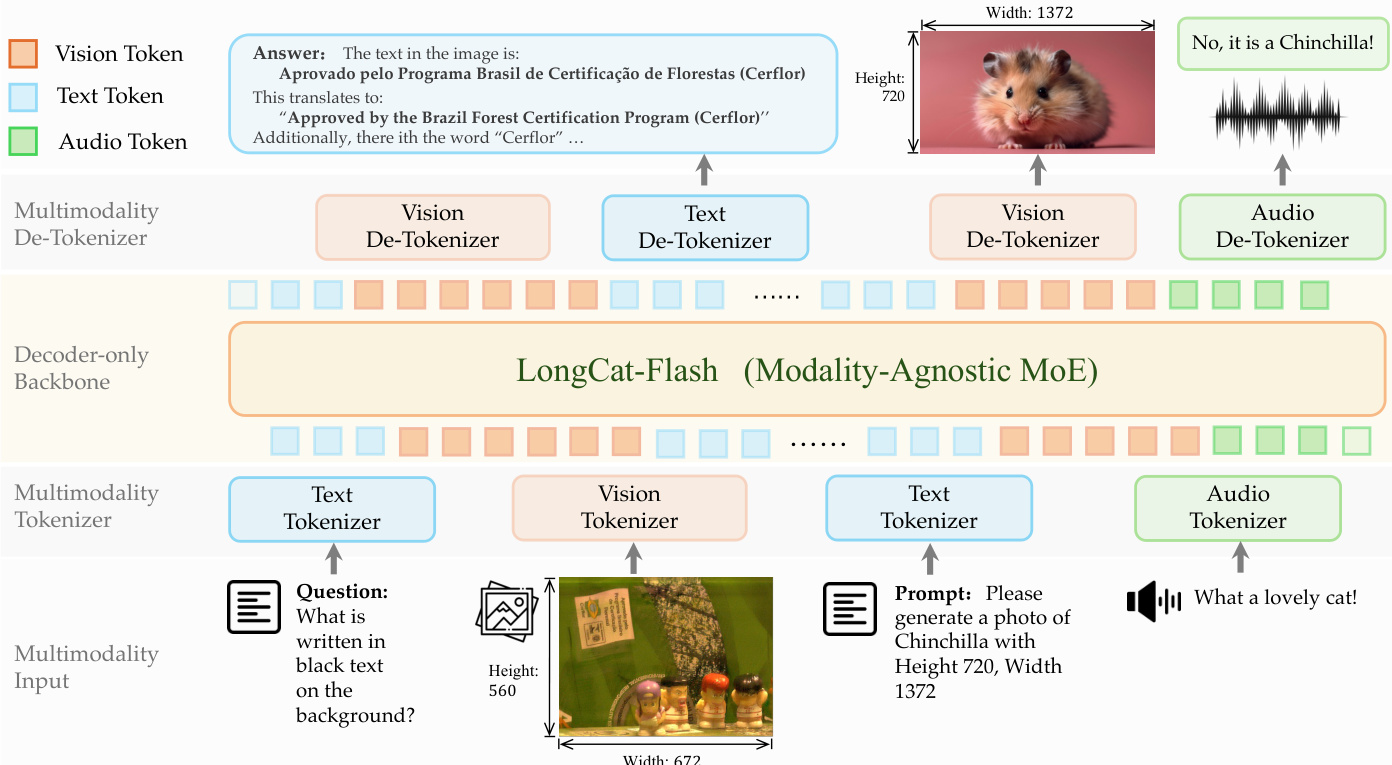
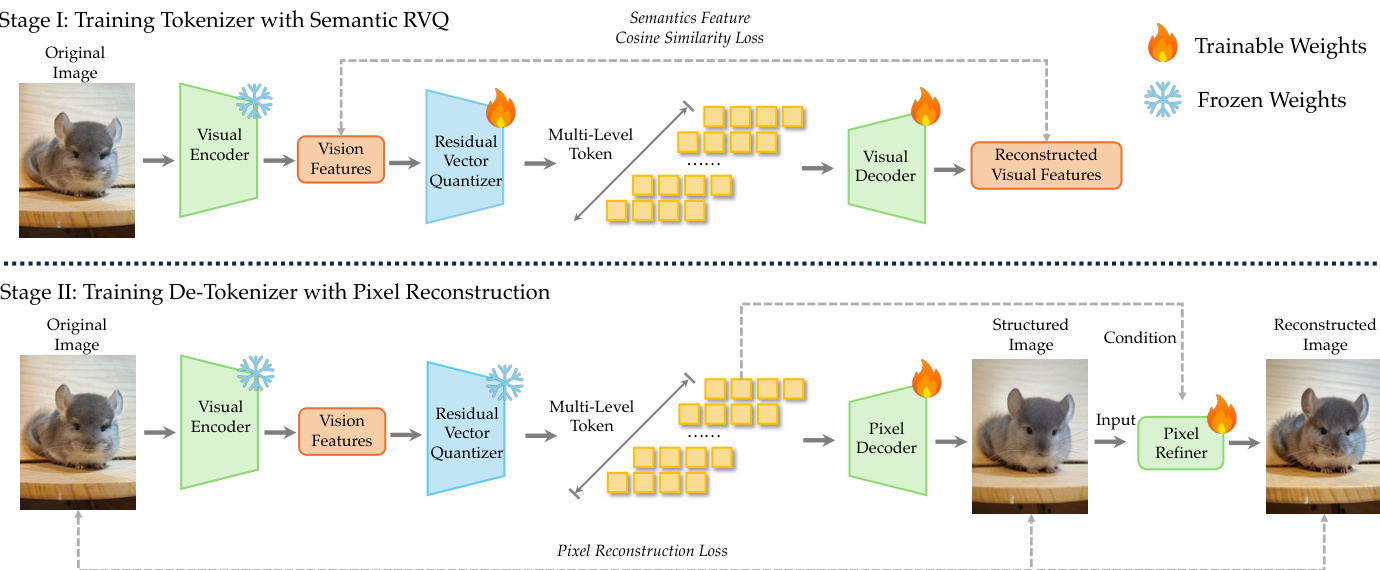
对于视觉处理,系统采用 dNaViT,一种离散原生分辨率视觉 Transformer。与依赖固定分辨率的传统编码器不同,dNaViT 在图像的本地分辨率上操作,以保留空间细节并避免信息丢失。tokenization 管道涉及语义与对齐编码器 (SAE),后跟残差矢量量化 (RVQ)。参考 tokenizer 和 de-tokenizer 训练管道。
SAE 将图像 I 投影到预量化表示 zp,保留多样化图像中心查询所需的信息。离散化过程使用 RVQ 将 SAE 特征的量化分解为 L 级级联码本级别。过程定义如下:
r0=fproj(z),q^l=VQ(rl−1),rl=rl−1−q^l,z^=l=1∑Lq^l视觉 tokenizer 的训练分两个阶段进行。在第一阶段,模型学习使用语义对齐和 RVQ 将连续特征映射到离散 tokens。在第二阶段,训练像素解码器从这些离散 tokens 重建图像,确保表示保留足够的信息用于生成。参考视觉重建管道。
对于音频处理,专用 tokenizer 将连续语音转换为离散 tokens。架构利用 Whisper 编码器进行特征提取,后跟 8 层 RVQ 进行量化。参考音频 tokenizer 框架。
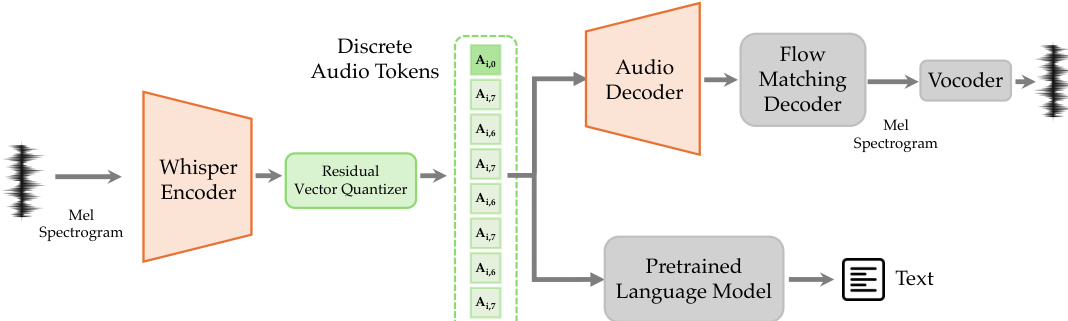
生成的 tokens 由两个分支处理:用于理解的冻结预训练语言模型和用于合成的带有流匹配模块的音频解码器。训练目标包括 Mel 频谱重建损失、RVQ commit 损失和用于音频理解的 LLM 损失:
Laudio=λ1Lrecon+λ2Lcommit+λ3Lllm骨干模型 LongCat-Flash 是一种专家混合 (MoE) 架构,保持模态无关。它支持文本引导音频的并行和串行生成策略。参考语音生成策略。
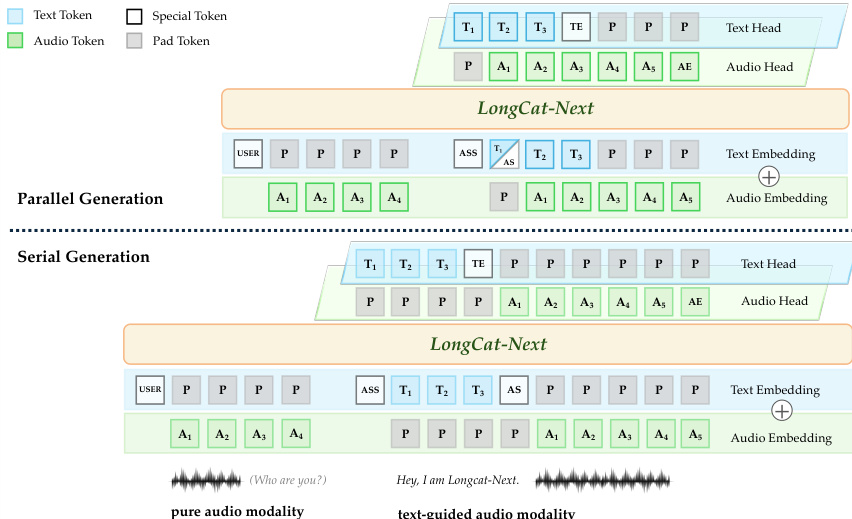
在并行生成中,文本和音频 tokens 同时生成,略有延迟以进行对齐,从而消除响应延迟。在串行生成中,模型首先生成文本片段,然后生成音频片段,这简化了过程并避免了模态表示之间的冲突。
实验
该研究评估了一个统一的全模态系统与领先的基线在视觉、音频、文本和生成任务上的表现,以验证其综合推理和感知能力。结果表明,该模型在数学推理和文本渲染方面实现了卓越的性能,同时在一般视觉问答和音频理解方面保持竞争力,且不损害基于文本的认知功能。进一步的消融研究表明,离散建模在数据充足的情况下可以与连续对应物相匹配,并且整合理解和生成任务创造了增强整体语义一致性的协同关系。
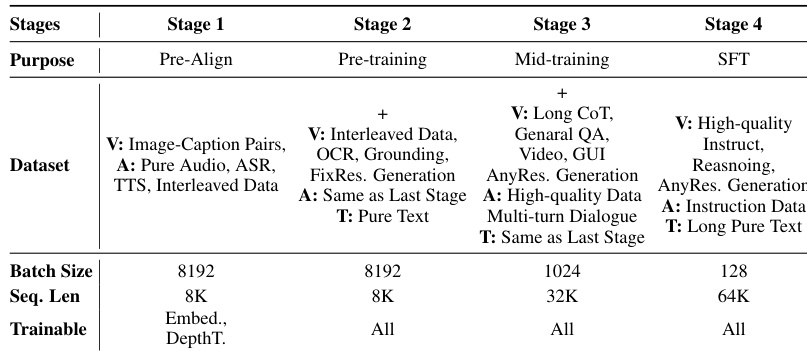
该表格概述了统一全模态系统的四阶段训练课程,从初始对齐进展到专门指令微调。该方法随着模型从预训练移动到监督微调,系统地增加序列长度和数据复杂度,同时减少批量大小。训练过程首先使用基本图像和音频数据进行预对齐,然后在预训练阶段扩展以包含 OCR、定位和交错文本。序列长度能力从初始阶段逐步扩展到最终微调阶段,以支持长上下文推理和生成。全参数训练在后期阶段激活,而初始对齐阶段专注于仅更新特定的嵌入和深度组件。
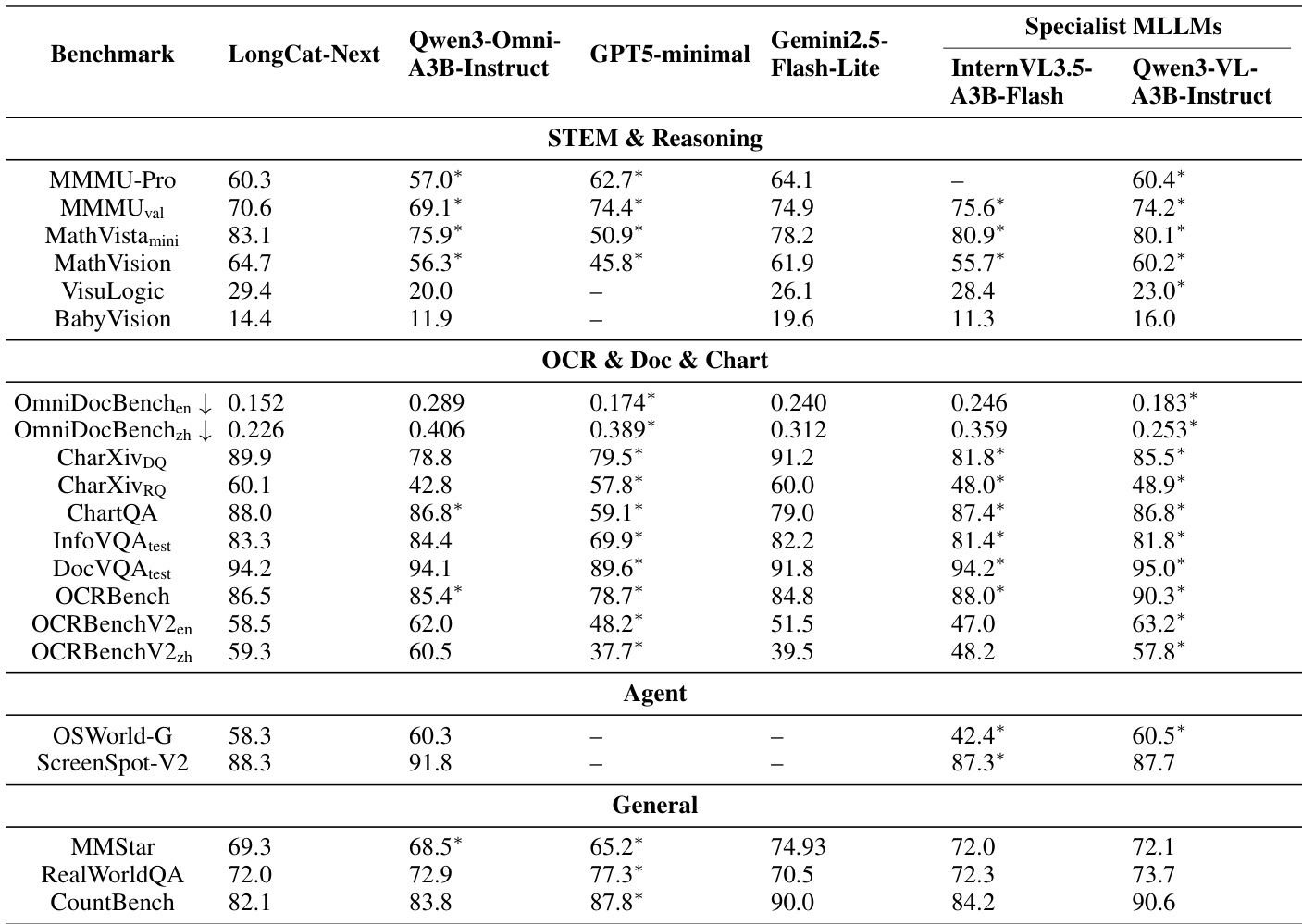
作者在包括 STEM、OCR 和一般视觉理解在内的多样化基准测试中评估 LongCat-Next 与最先进的统一和专家模型。结果表明,该模型在数学推理和文档分析方面实现了领先性能,通常优于专用的视觉 - 语言模型和其他全模态系统。此外,该模型在 agent 任务和一般视觉问答方面保持竞争力,验证了其在多种模态上的鲁棒性。该模型在数学推理基准测试中名列前茅,在涉及复杂逻辑和数学的任务上超越了专用视觉 - 语言模型。文档理解和 OCR 基准测试的表现优于基线,表明具有强大的细粒度文本感知能力。一般视觉理解得分极具竞争力,该模型在 MMStar 和 RealWorldQA 等特定基准测试中领先。
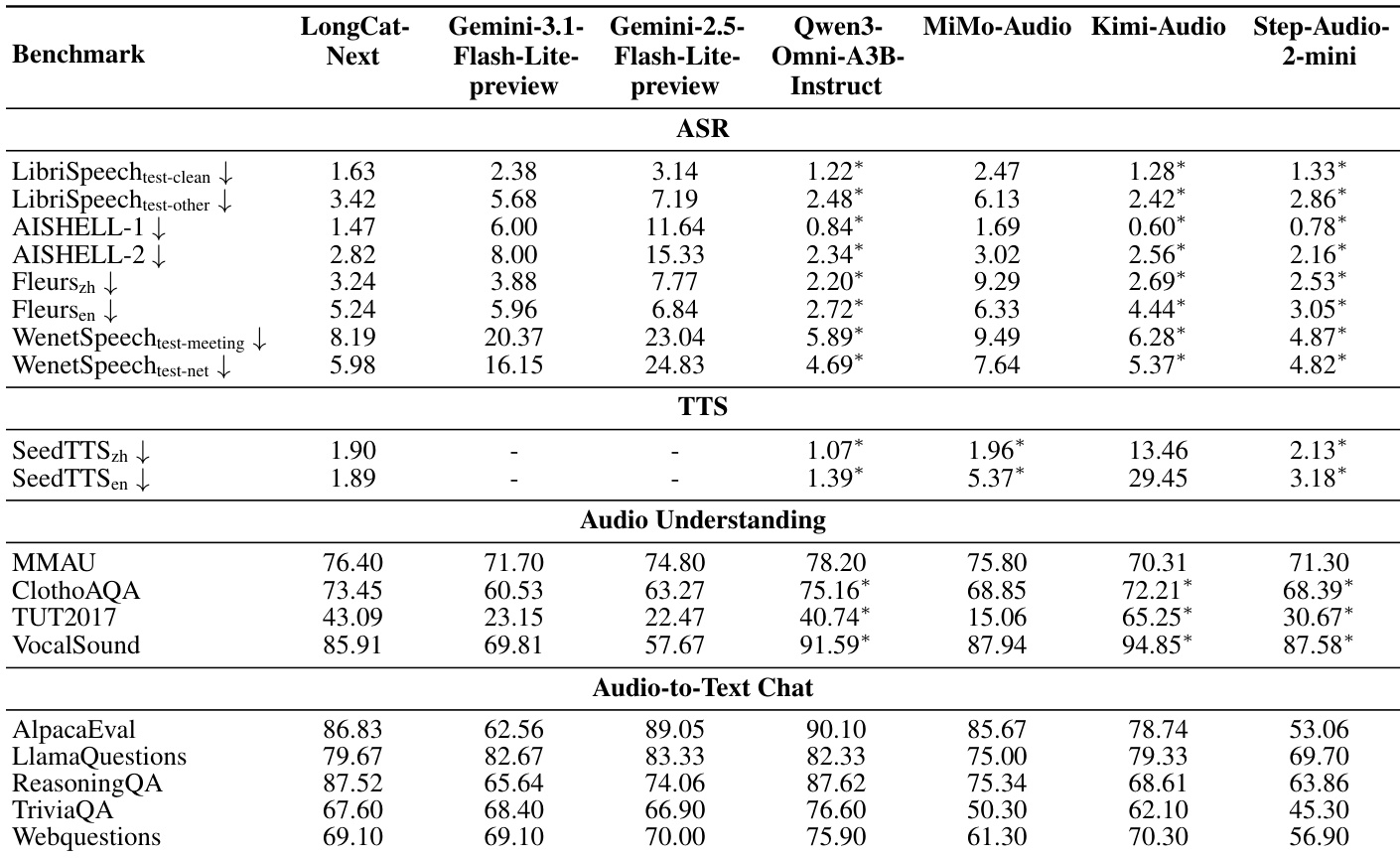
该表格全面评估了 LongCat-Next 的音频能力,与领先的多模态和专用模型在语音识别、合成、理解和聊天任务上进行对比。LongCat-Next 在语音识别和合成任务中显示出对 Gemini 系列的显著优势,始终实现更低的错误率。虽然在推理和聊天能力方面与顶级基线保持竞争,但与 Kimi-Audio 和 Qwen3-Omni 等专用模型相比,其在 ASR 中的错误率通常较高,在音频理解方面的得分较低。LongCat-Next 在所有测试数据集的自动语音识别中实现了比 Gemini 模型低得多的错误率。在文本到语音合成中,该模型优于 MiMo-Audio 和 Step-Audio-2-mini,特别是在英语基准测试上。该模型在音频到文本聊天中表现出强大的推理能力,在 ReasoningQA 基准测试上与 Qwen3-Omni 的表现 closely 匹配。
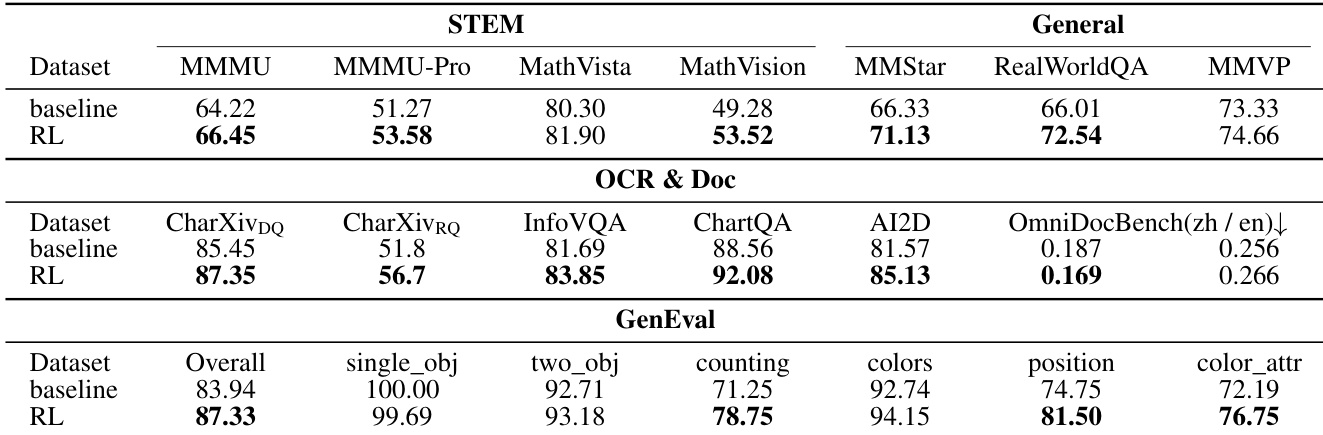
作者在 STEM、OCR 和视觉生成基准测试上评估了模型在有无强化学习 (RL) 情况下的性能。结果表明,与基线相比,结合 RL 始终提高了模型在推理、文档理解和图像生成任务上的能力。强化学习增强了 STEM 基准测试的性能,在数学和多学科推理方面显示出增益。RL 变体在 OCR 和文档任务中取得了优越的结果,特别是在图表问答和信息提取方面。视觉生成能力整体提升,RL 模型在一般对齐和复杂属性任务上优于基线。
该实验评估了各种视觉编码器(包括 ResNet50、ViT 变体和 QwenViT)的重建能力,使用保真度和感知指标。结果表明,随机初始化的 ViT 实现了最高的像素级准确率,而 ResNet50 模型展示了最佳的感知质量。相比之下,没有 merger 模块的 QwenViT 编码器在所有测量维度上表现最低。随机初始化的 ViT-B/16 与预训练或语义编码器相比,实现了更优越的像素级重建保真度。ResNet50 保持了最强的感知质量,在分布相似性方面优于其他架构。没有 merger 模块的 QwenViT 编码器在测试模型中显示出最弱的重建能力。

一个渐进的四阶段训练课程扩展序列长度和数据复杂度,以支持统一全模态系统中的长上下文推理。评估显示,该模型在数学推理和文档分析方面领先,同时在一般视觉和音频推理基准测试中保持竞争力。此外,实验证实强化学习改善了推理和生成,而编码器消融突出了像素保真度和感知质量之间的权衡。