Command Palette
Search for a command to run...
Vision2Web:面向智能体验证的视觉网站开发分层基准测试
Vision2Web:面向智能体验证的视觉网站开发分层基准测试
Zehai He Wenyi Hong Zhen Yang Ziyang Pan Mingdao Liu Xiaotao Gu Jie Tang
摘要
近年来,大型语言模型(LLM)的进步显著提升了编码智能体(Agent)的能力,然而针对复杂端到端网站开发任务的系统性评估仍显不足。为填补这一空白,我们提出了 Vision2Web——一个面向可视化网站开发的分层基准测试(Benchmark)。该基准涵盖了从静态“界面到代码”(UI-to-code)生成、交互式多页前端复现,到长周期全栈网站开发等多个层次。Vision2Web 基于真实世界网站构建,共包含 16 个类别下的 193 项任务,涉及 918 张原型图像和 1,255 个测试用例。为实现灵活、全面且可靠的评估,我们提出了一种基于工作流的智能体验证范式,该范式由两个互补组件构成:图形用户界面(GUI)智能体验证器与基于视觉语言模型(VLM)的评判器。我们对多种在不同编码智能体框架下实例化的视觉语言模型进行了评估,结果显示各任务层级均存在显著的性能差距,即便是当前最先进的模型在全栈开发任务上仍面临严峻挑战。
一句话总结
清华大学与另一研究机构的研究人员推出了 Vision2Web,这是一个用于视觉网站开发的分层基准,旨在评估大语言模型(LLM)在静态 UI 到代码转换及全栈任务中的表现。该研究采用一种新颖的基于工作流的智能体验证范式,揭示了当前模型在复杂端到端网页创建任务中存在显著的性能差距。
主要贡献
- 本文提出了 Vision2Web,这是一个分层基准,涵盖静态 UI 到代码生成、交互式多页面前端复现以及长周期全栈开发,共包含 193 个真实世界任务和 918 张原型图像。
- 提出了一种基于工作流的智能体验证范式,通过将测试构建为具有明确定义节点的有向依赖图,在约束智能体执行的同时保持灵活性,从而确保评估的可复现性。
- 该工作实现了两个互补的验证组件:用于功能正确性的 GUI 智能体验证器和用于视觉保真度的基于 VLM 的评判器。实验表明,这两个组件揭示了最先进模型在全栈开发任务中存在巨大的性能差距。
引言
随着自主智能体系统从简单的代码生成迈向完整的端到端软件开发,开发和评估用于视觉网站创建的自主智能体变得至关重要。以往的评估方法面临诸多困难:传统单元测试难以处理多样化的实现方式,而现有的基于智能体的评估器由于目标定义松散,往往表现不可预测。此外,视觉测试依赖于脆弱的基于规则的脚本或像素级比较,无法捕捉人类的感知判断。为了解决这些差距,作者推出了 Vision2Web,这是一个采用基于工作流的智能体验证范式的分层基准。该方法通过结构化的测试工作流和明确的验证节点来约束智能体执行,从而在统一框架内实现对功能正确性和视觉保真度的可复现且与实现无关的评估。
数据集
-
数据集构成与来源
- 作者从 C4 验证集中独家获取真实网站来构建 Vision2Web,以防止数据泄露。
- 该基准涵盖四大类别(内容、交易、SaaS 平台、公共服务)和 16 个子类别,以确保多样性。
- 包含一个多媒体资源库,内含图片、图标、视频和字体,以模拟真实的开发环境。
-
各子集的关键细节
- 数据集包含 193 个任务,分为三个复杂度递增的层级:
- 静态网页(100 个任务): 利用原型图像,专注于跨桌面、平板和移动分辨率的视觉保真度。
- 交互式前端(66 个任务): 要求基于多个原型和文本描述,生成具有连贯导航流程的多页面前端。
- 全栈网站(27 个任务): 模拟真实的工程场景,包含需求文档、复杂的状态管理和后端集成。
- 该集合包含 918 张原型图像和 1,255 个测试用例,总计 21,516 个输入文件。
- 数据集包含 193 个任务,分为三个复杂度递增的层级:
-
数据处理与过滤流程
- 采用三阶段过滤流程对初始网络语料库进行优化:
- 结构评估: 分析 DOM 属性(如标签分布和树深度),排除简单或格式错误的页面,将候选数量减少至 63,515 个。
- 内容筛选: 利用基于 VLM 的评分,仅保留 7,391 个具有功能丰富性和视觉连贯性的页面。
- 人工审查: 人工标注员验证页面一致性、实现难度和类别平衡,以最终确定任务集。
- 测试用例标注采用“专家在环”策略,由博士研究人员起草高层工作流,并由 Claude Code 将其细化为可执行序列。
- 采用三阶段过滤流程对初始网络语料库进行优化:
-
在模型评估中的应用
- 作者利用该数据集,通过基于工作流的智能体验证范式来评估多模态编码智能体。
- 评估依赖于 GUI 智能体验证器来执行测试工作流,并依靠基于 VLM 的评判器对照原型定量评估视觉保真度。
- 该基准在不依赖外部编排层的情况下,同时衡量功能正确性和视觉保真度,确保智能体仅依赖其自身的推理和编码能力。
方法
所提出的自动化网站评估框架分为三个连续阶段:分层任务构建、编码智能体生成和基于工作流的智能体验证。该流程确保了生成和验证全栈 Web 应用程序的系统化方法。
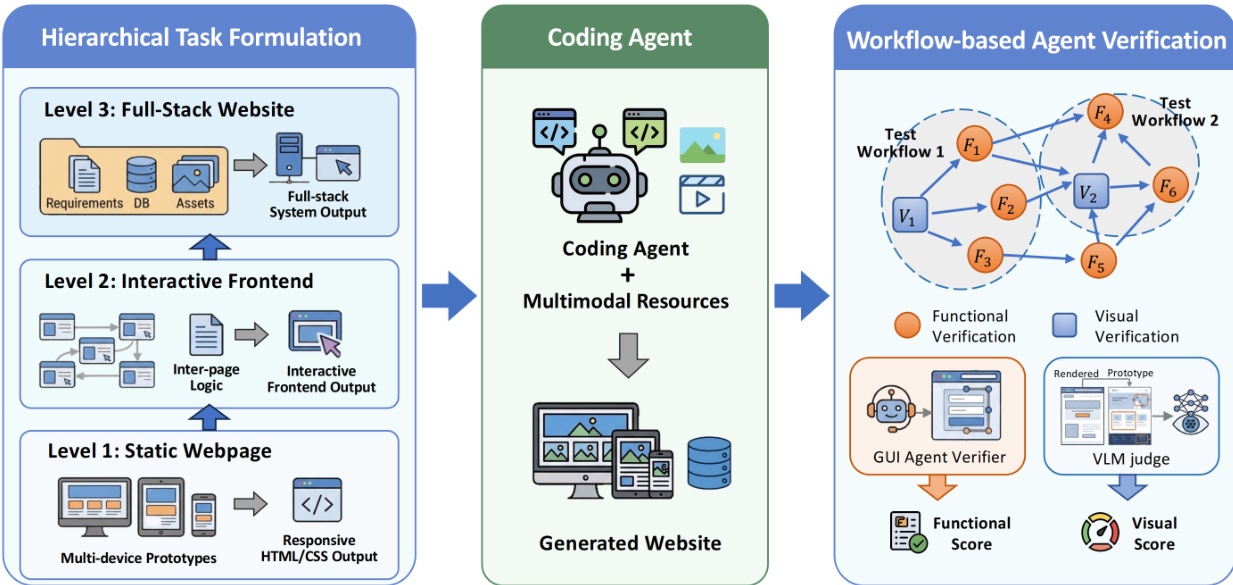
该过程始于分层任务构建,将开发目标分解为三个不同复杂度的层级。第 1 级针对静态网页的创建,专注于跨多种设备的响应式 HTML/CSS 输出。第 2 级进阶到交互式前端,结合页面间逻辑以生成交互式前端输出。最后,第 3 级解决全栈网站问题,整合需求、数据库和资产以生成完整的系统输出。
在任务定义之后,编码智能体模块利用多模态资源来合成网站。这一核心组件处理构建阶段提供的规范,以生成目标系统所需的实际代码和资产。
最后阶段采用基于工作流的智能体验证来评估生成的输出。该阶段将端到端测试形式化为有向依赖图,其中节点代表自包含的验证子过程,边编码顺序依赖关系。为了平衡评估稳定性和覆盖效率,系统通过解耦依赖测试节点以防止错误传播,并在同一应用上下文中整合相关测试节点来构建测试工作流。
验证节点分为两种互补类型。功能验证节点评估交互保真度,形式化为三元组 ni=⟨Oi,Ai,Vi⟩,其中 Oi 指定测试目标,Ai 定义引导动作,Vi 编码验证标准。GUI 智能体验证器执行这些节点,维护包含历史目标和动作的上下文 Ci={H<i,Oi,Ai,Vi},以确保状态转换的可复现性。功能分数(FS)计算为通过的功能验证节点的比例。
视觉验证节点通过将渲染页面与参考原型进行比较来评估视觉保真度。每个节点形式化为 ni=⟨Pi⟩,其中 Pi 表示目标原型。调用专用的 VLM 评判器执行组件级比较,并根据预定义的视觉标准分配保真度分数。视觉分数(VS)计算为所有原型上所有块级分数的平均值。这种双重验证器方法允许对生成网站的功能逻辑和视觉一致性进行细粒度和系统化的评估。
实验
- Vision2Web 评估了八种最先进的多模态模型在两个编码智能体框架中的表现,以评估其在视觉网站开发方面的能力,结果显示随着任务复杂度从静态页面增加到全栈应用,性能持续下降。
- 智能体在较小设备形态和视觉密集的原型方面表现显著困难,表明其在复杂视觉推理和响应式布局适应方面的能力有限。
- 与其他模型相比,Claude-Opus-4.5 在跨框架和任务层级上表现出更优越的性能,而多个智能体在涉及多页面集成的复杂全栈任务中完全失败。
- 观察到状态相关操作(如状态管理和 CRUD 操作)存在系统性弱点,而导航和认证任务的处理则更为可靠。
- 失败分析揭示了细粒度视觉对齐、跨模块一致性和长周期系统规划方面的明显差距,这些差距随着开发范围的扩大而加剧。
- 该研究验证了其评估流程的可靠性,显示自动 GUI 智能体验证器与人工标注之间具有高度一致性,且基于 VLM 的评判器与人类偏好之间具有强排名一致性。