Command Palette
Search for a command to run...
DataFlex:面向大语言模型数据中心动态训练的统一框架
DataFlex:面向大语言模型数据中心动态训练的统一框架
摘要
以数据为中心的训练已成为提升大语言模型(LLM)性能的重要方向,其核心在于在优化过程中不仅调整模型参数,还同步优化训练数据的选择、组合与加权策略。然而,现有的数据选择、数据混合优化及数据重加权方法往往基于孤立的代码库开发,接口标准不一,严重阻碍了结果的可复现性、公平比较以及实际集成应用。为此,本文提出 DataFlex——一个基于 LLaMA-Factory 构建的统一数据为中心动态训练框架。DataFlex 支持三大动态数据优化范式:样本选择、领域混合比例调整以及样本重加权,同时完全兼容原始训练工作流。该框架提供可扩展的 Trainer 抽象接口与模块化组件,可无缝替换标准 LLM 训练流程;并统一了嵌入(embedding)提取、推理(inference)及梯度计算等关键依赖模型的操作,支持包括 DeepSpeed ZeRO-3 在内的大规模训练场景。我们在多种以数据为中心的方法上开展了系统性实验。结果表明,在 MMLU 基准上,动态数据选择策略在 Mistral-7B 与 Llama-3.2-3B 模型上均持续优于静态全量数据训练。在数据混合方面,当在 SlimPajama 数据集上以 6B 和 30B tokens 规模预训练 Qwen2.5-1.5B 模型时,DoReMi 与 ODM 方法相较于默认比例,在 MMLU 准确率与语料库级困惑度(perplexity)上均取得显著提升。此外,DataFlex 在运行时效率上亦持续优于各方法的原始实现。上述结果证明,DataFlex 为 LLM 的以数据为中心的动态训练提供了一套高效、可靠且可复现的基础设施。
一句话总结
北京大学与上海人工智能实验室的研究人员提出了 DATAFLEX,这是一个基于 LLaMA-Factory 构建的统一框架,将数据选择、混合优化和重加权整合到单一动态训练范式中,实现了可扩展、可复现的大语言模型优化,其性能优于静态基线。
主要贡献
- 本文介绍了 DATAFLEX,这是一个基于 LLaMA-Factory 构建的统一框架,通过可扩展的训练器抽象和模块化算法组件,支持动态样本选择、领域混合调整以及样本重加权。
- 该工作统一了常见的模型相关操作,如嵌入提取、模型推理和梯度计算,同时保持与 DeepSpeed ZeRO-3 等大规模训练设置的完全兼容性。
- 实验表明,该框架在多种骨干网络和数据集上,相比静态训练和默认数据比例均取得了持续的性能提升,同时在运行时效率上也优于原始特定方法的实现。
引言
大语言模型训练正日益转向以数据为中心的方法,通过优化数据选择、混合和加权,与模型参数协同提升效率和性能。然而, prior 工作存在严重的碎片化问题,现有方法往往分散在不同的代码库中,接口不一致,阻碍了可复现性、公平比较以及集成到可扩展流水线中。作者利用广泛采用的 LLaMA-Factory 引入了 DATAFLEX,这是一个统一框架,通过模块化训练器抽象支持选择、混合调整和重加权,从而标准化以数据为中心的动态训练。该系统统一了共享的模型相关操作(如嵌入提取和梯度计算),同时保持与 DeepSpeed ZeRO-3 等大规模训练设置的兼容性,既支持系统的研究评估,也便于实际部署。
数据集
-
数据集构成与来源:作者使用了 SlimPajama,这是一个源自 RedPajama 的大规模去重英文预训练语料库。该数据集聚合了七个文本领域:CommonCrawl (CC)、C4、GitHub、Book、ArXiv、Wikipedia 和 StackExchange (SE)。
-
子集详情与过滤:使用了两个子集来评估不同 token 规模下的训练预算:SlimPajama-6B 和 SlimPajama-30B。这两个子集均经过随机采样,严格保留了原始语料库的自然 token 级领域比例,分别为:CommonCrawl (54.1%)、C4 (28.7%)、GitHub (4.2%)、Book (3.7%)、ArXiv (3.4%)、Wikipedia (3.1%) 和 StackExchange (2.8%)。这些自然比例作为默认基线混合比例以及动态优化方法的初始权重。
-
训练用途与混合比例:作者从头开始训练 Qwen2.5 模型(随机初始化),以隔离数据混合策略的影响。基线使用具有默认 SlimPajama 比例的静态混合器。DoReMi 方法遵循三步流程,其中训练参考模型和代理模型以计算每个领域的超额损失,从而为目标模型生成优化的静态权重,显著增加了 Book 和 Wikipedia 等高质量领域的比例,同时降低了 CommonCrawl 的主导地位。在线数据混合(ODM)方法则利用 Exp3 多臂老虎机算法,在单次训练过程中动态调整领域权重,无需单独的参考模型。
-
处理与配置详情:所有实验均训练一个完整 epoch,采用线性学习率衰减和 5% 的预热比例。所有模型均应用 Qwen 分词器,并使用固定的随机种子 42。训练运行采用 BFloat16 混合精度,使用 DeepSpeed ZeRO Stage-3 以提高内存效率,并使用 FlashAttention-2 进行注意力计算。6B-token 实验在单个节点(8 张 GPU)上运行,而 30B-token 实验扩展到 4 个节点,总计 32 张 H20 GPU。
方法
作者提出了 DATAFLEX,这是一个统一的以数据为中心的动态训练框架,旨在将数据视为一等优化变量。该系统构建于 LLaMA-Factory 之上,分为三个主要层级,以支持对数据选择、混合和加权的动态控制。
请参阅框架图以了解高层架构。基础层(标记为 (a))直接继承自 LLaMA-Factory,提供模型管理、数据处理和优化器的标准基础设施。它还集成了 DeepSpeed 和 FSDP 等并行优化策略以确保可扩展性。
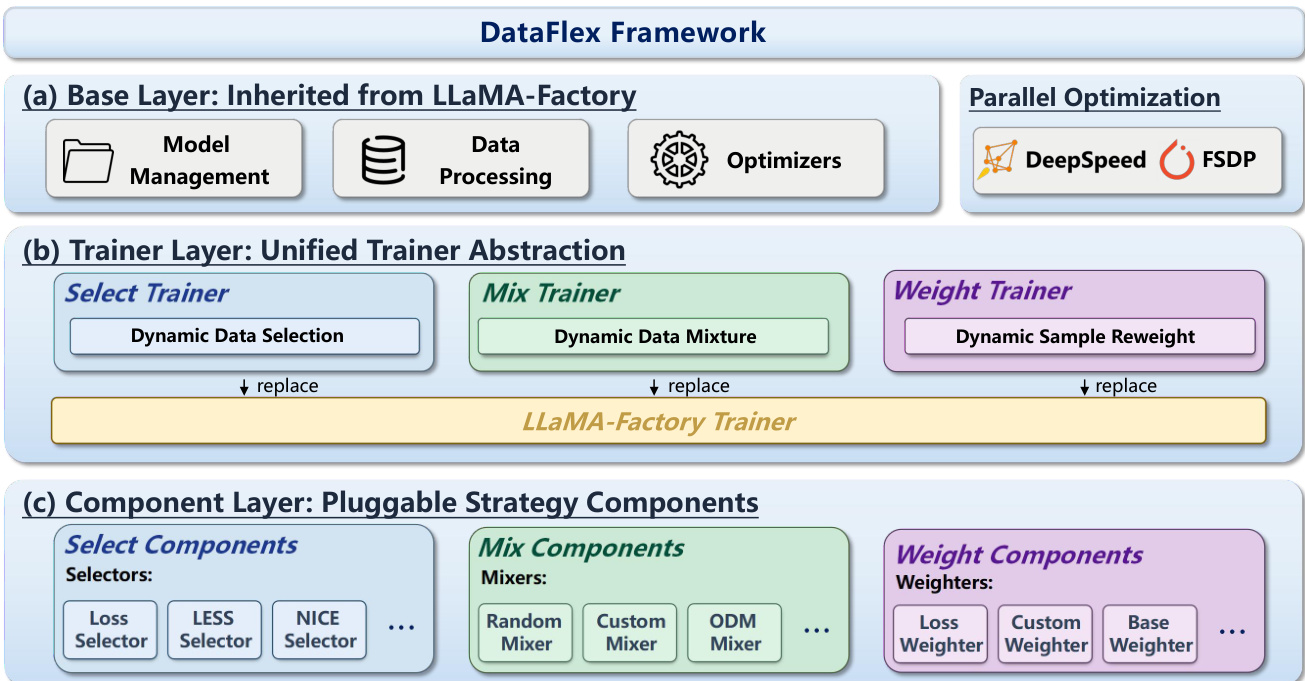
系统的核心是训练器层(标记为 (b)),它实现了统一的训练器抽象。该层用三种专门的动态训练模式替换了原始的 LLaMA-Factory 训练器:用于动态数据选择的 Select Trainer、用于动态数据混合的 Mix Trainer,以及用于动态样本重加权的 Weight Trainer。每种模式对应一种特定的以数据为中心的优化范式。
训练器层之下是组件层(标记为 (c)),由可插拔的策略组件组成。Select Trainer 利用选择器(例如 Loss Selector、LESS Selector),Mix Trainer 采用混合器(例如 Random Mixer、ODM Mixer),Weight Trainer 使用加权器(例如 Loss Weighter)。这些组件封装了特定于算法的逻辑,同时共享通用接口。在训练过程中,训练器调用其关联的组件以生成控制信号,如样本子集、领域混合比例或每个样本的权重,这些信号随后被反馈到优化过程中。这种模块化设计允许研究人员以最小的工程开销实现和比较新的以数据为中心的算法,同时保持与现有大规模训练工作流的兼容性。
实验
- 关于数据选择和重加权的实验验证了,动态且感知模型的方法(如 LESS 和 Reweight)在 Mistral-7B 和 Llama-3.2-3B 上均持续优于静态全数据训练基线,且对于动态选择至关重要的较小模型,性能差距更为显著。
- 离线选择方法由于预计算了高价值样本,表现出更快的早期收敛速度;而在线方法通过适应不断变化的模型梯度,实现了更高的最终准确率。
- 数据混合实验证实,与静态基线相比,动态优化策略(DoReMi 和 ODM)提高了 MMLU 准确率和困惑度,其中 DoReMi 在资源丰富领域表现优异,而 ODM 有效地提升了专业且代表性不足的领域的权重。
- 效率评估显示,DATAFLEX 框架相比原始实现,减少了在线(LESS)和离线(TSDS)选择算法的运行时间,同时独特地实现了在线选择的多 GPU 并行可扩展性,以处理大规模数据集。