Command Palette
Search for a command to run...
QuitoBench:一个高质量开源时间序列预测基准
QuitoBench:一个高质量开源时间序列预测基准
Siqiao Xue Zhaoyang Zhu Wei Zhang Rongyao Cai Rui Wang Yixiang Mu Fan Zhou Jianguo Li Peng Di Hang Yu
摘要
时间序列预测在金融、医疗和云计算等领域至关重要,但其进展受限于一个根本性瓶颈:缺乏大规模、高质量的基准测试数据集。为填补这一空白,我们提出了 QuitoBench——一个面向时间序列预测的机制均衡基准,覆盖八种趋势×季节性×可预测性(TSF)机制,旨在捕捉与预测相关的属性,而非基于应用定义的领域标签。该基准构建于 Quito 之上,后者是一个包含支付宝应用流量数据的海量时间序列语料库,涵盖九个业务领域,规模达十亿级。我们在 232,200 个评估实例上对来自深度学习、基础模型和统计基线的 10 种模型进行了基准测试,得出四项关键发现:(i)存在上下文长度交叉现象,即深度学习模型在短上下文(L=96)下表现领先,而基础模型在长上下文(L≥576)下占据主导;(ii)可预测性是决定预测难度的主导因素,导致不同机制间平均绝对误差(MAE)差距达 3.64 倍;(iii)深度学习模型在参数数量仅为基础模型 1/59 的情况下,性能与之相当甚至更优;(iv)对于两类模型家族而言,扩大训练数据量所带来的收益显著优于扩大模型规模。上述发现已通过跨基准和跨指标的一致性得到充分验证。我们的开源发布为时间序列预测研究提供了可复现、机制感知的评估框架。
一句话总结
蚂蚁集团研究人员推出了 QUITO-BENCH,这是一个基于十亿级支付宝语料库构建的机制平衡基准,旨在解决时间序列预测中的数据稀缺问题。该基准揭示了可预测性是决定难度的关键因素,且数据扩展的效果优于模型规模扩展,从而实现了在金融和云计算领域的可复现评估。
主要贡献
- 本文介绍了 QUITO-BENCH,这是一个机制平衡的基准,它根据趋势、季节性和可预测性等内在统计属性而非应用领域对时间序列进行分类,以确保在八种不同的预测机制中实现均匀覆盖。
- 提出了名为 QUITO 的十亿级单一来源时间序列语料库,其中包含来自支付宝的均匀长序列,消除了信息泄露,并支持长达 1,024 个时间步的上下文长度的严格评估。
- 在 232,200 个评估实例上进行的广泛实验表明,深度学习模型在短上下文场景中优于基础模型,而基础模型在长上下文场景中占据主导地位;同时,扩展训练数据带来的收益大于扩展模型规模。
引言
时间序列预测对于金融、医疗和云计算中的高风险决策至关重要,但由于缺乏大规模、高质量的基准,该领域正面临评估危机。先前的工作存在基于领域的粗略分类(忽略了数据的内在属性)、严重的分布偏斜(大多数数据落入单一机制)以及因在训练和测试流程中重复使用公共数据集而导致的信息泄露等问题。为了解决这些问题,作者推出了 QUITOBENCH,这是一个基于 QUITO 构建的机制平衡基准。QUITO 是一个来自支付宝的十亿级时间序列语料库,确保了在八种不同的趋势、季节性和可预测性机制中无泄露的评估。这一新标准使得深度学习模型和基础模型之间的严格比较成为可能,揭示了可预测性是决定难度的关键因素,且数据扩展比增加模型规模带来更大的收益。
数据集
-
数据集构成与来源 作者从支付宝(一个主要的数字支付平台)的生产流量遥测数据中构建了 QUITO 语料库。数据涵盖九个业务垂直领域,包括金融、商业和基础设施,确保了全规模数字经济的多样性,而非局限于单一狭窄领域。每个序列代表一个独立应用服务的工作负载,记录为 5 维匿名流量子类型向量。
-
每个子集的关键细节 语料库被划分为两个互不相交的子集,应用标识符无重叠:
- QUITO-MIN:包含 22,522 个序列,分辨率为 10 分钟,时间跨度从 2023 年 7 月 10 日至 2023 年 8 月 19 日。该子集反映了受较短保留窗口限制的高频遥测数据。
- QUITO-HOUR:包含 12,544 个序列,分辨率为 1 小时,时间跨度从 2021 年 11 月 18 日至 2023 年 8 月 19 日。该子集由长期归档的小时聚合数据组成。
- QUITOBENCH:从完整语料库中精心挑选的评估基准,包含 1,290 个测试序列(773 个来自 QUITO-MIN,517 个来自 QUITO-HOUR),旨在确保不同时间序列行为的平衡表示。
-
数据使用与处理策略 作者采用严格的流程来准备训练和评估数据:
- 聚合:原始 1 秒遥测数据通过最大池化聚合为 10 分钟或 1 小时的时间窗,以保留工作负载峰值。
- 清洗:作者应用两阶段去重过程,移除完全重复和近似重复的序列(皮尔逊相关系数 > 0.99),并对 5 个变量进行标准化。
- 机制标记:使用 STL 分解和谱熵,通过 TSF 配置文件(趋势、季节性、可预测性)对每个序列进行特征化。这些指标被二值化以分配八个离散机制标签之一。
- 基准构建:为防止评估偏向常见模式,作者使用分层抽样为 QUITOBENCH 的每个机制单元选择约 162 个序列,确保对所有八种行为类型的近乎均匀覆盖。
-
划分与防泄露 作者在 2023 年 7 月 28 日强制执行全局时间截断,以确保两种粒度下的划分均无泄露。该日期之前的数据被划分为训练集(80%)和验证集(20%),而该日期之后的数据构成测试集。这种时间顺序确保了未来信息不会污染训练过程。
方法
作者利用结构化流程构建了一个鲁棒的时间序列预测基准,确保无污染的评估和多样化的机制覆盖。如框架图所示,整体工作流程分为五个 distinct 阶段:原始生产监控流收集、涉及质量过滤和去重的标准化、建立全局时间截断的划分协议、计算动态机制标签的精选,以及最终创建平衡评估集的基准构建。

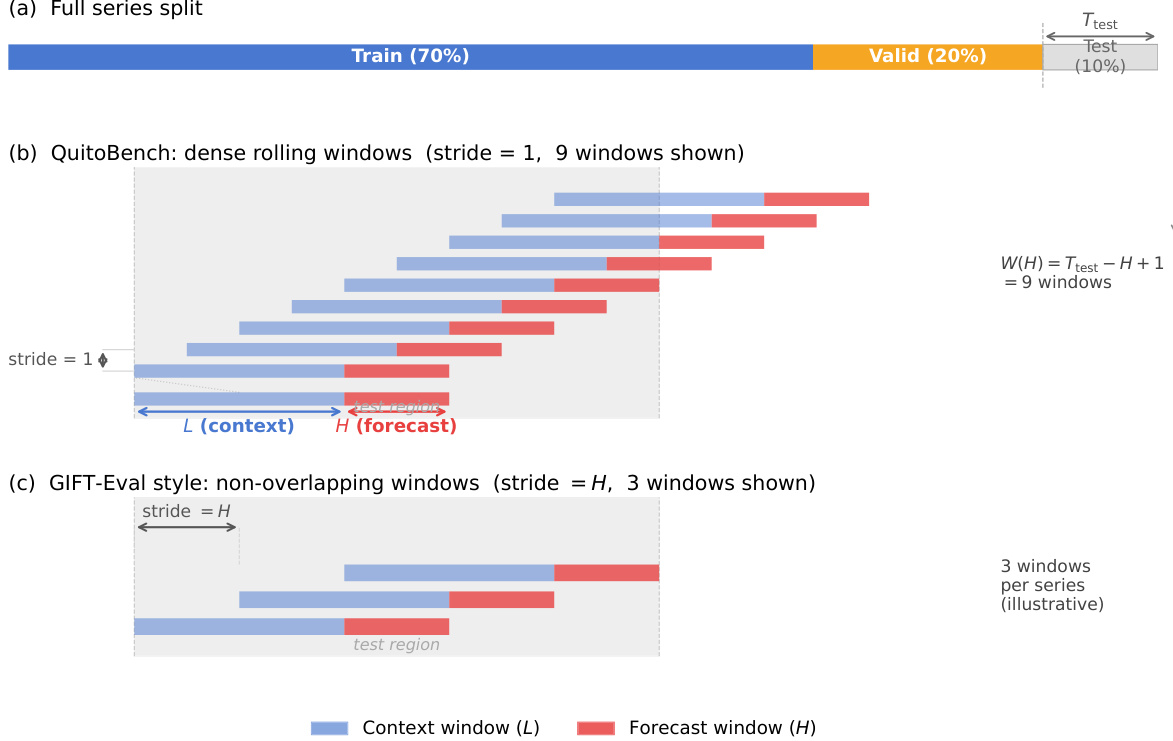
为了确保严格的评估,数据采用全局时间截断策略进行划分。如下图所示,完整序列被划分为训练集(70%)、验证集(20%)和测试集(10%)。对于 QuitoBench 协议,作者在测试阶段采用步长为 1 的密集滚动窗口,以最大化数据利用率,这与 GIFT-Eval 风格评估中使用的非重叠窗口形成对比。这种方法从测试区域生成多个上下文 - 预测对(L 和 H),从而能够更细致地评估模型在不同时间跨度上的性能。
精选过程的核心组成部分是利用三个标量诊断指标来表征每个时间序列的动态机制:趋势强度(T)、季节性强度(S)和可预测性(F)。每个指标的范围都在 [0,1] 之间,其中较高的值表示该属性存在得越强。
为了量化趋势和季节性,作者使用 LOESS 的季节 - 趋势分解(STL)对每个单变量序列 {xt} 进行分解。这产生了三个加性分量:
xt=τt+st+rt.其中,τt 代表趋势,st 代表季节性分量,rt 代表残差。季节性强度(S)和趋势强度(T)基于这些分量的方差定义:
S=max(0, 1−Var(s+r)Var(r)),T=max(0, 1−Var(τ+r)Var(r)).接近 1 的值意味着该分量主导了残差,而接近 0 的值则表明该分量相对于噪声可以忽略不计。季节性周期 p 由序列分辨率决定,QUITO-MIN 设为 144,QUITO-HOUR 设为 24。
可预测性被测量为归一化谱熵的补数。使用带有 Hann 窗的 Welch 方法,计算去均值序列的功率谱密度 Pk。归一化熵 H 计算如下:
H=−k∑p^klogp^k/logK,p^k=∑jPjPk,其中 K 是频率 bin 的数量。可预测性随后定义为 F=1−H,其中 F=1 表示完全确定的序列,F=0 对应白噪声。
由于每个序列都是包含五个变量的多变量序列,作者独立计算每个通道的 T、S 和 F,并通过平均进行聚合:
Ti=51j=1∑5Ti,j,Si=51j=1∑5Si,j,Fi=51j=1∑5Fi,j.最后,每个诊断指标使用 0.4 的固定阈值进行二值化,以分配 HIGH 或 LOW 标签。这三个二进制标签组合形成八个不同的 TSF 机制单元之一(例如,TREND×SEASON×FORECAST),确保基准中难度级别的平衡分布。
实验
- 综合基准评估:在 18 种任务配置下,使用密集滚动窗口测试了来自深度学习、基础模型和统计家族的十种模型。这验证了深度学习模型通常在短上下文场景中优于基础模型,而基础模型在长历史上下文中表现卓越,并确认统计基线不足以应对复杂的流量预测。
- 扩展性与效率分析:改变数据量和模型规模的实验表明,增加训练数据带来的性能提升显著大于增加模型参数。这验证了特定任务的深度学习模型具有更高的参数效率,以数量级更少的参数实现了与大规模基础模型相当或更优的精度。
- 上下文长度与预测跨度敏感性:对上下文长度的分析揭示了一种功能性的划分,即深度学习模型是短历史数据的专家,而基础模型利用预训练来利用长程依赖关系。预测跨度测试进一步表明,特定任务的架构在长预测窗口上比基础模型保持更好的稳定性,后者随着不确定性的累积而更快地退化。
- TSF 机制专业化:在趋势、季节性和可预测性(TSF)机制上的评估确定了可预测性是难度的主要驱动因素。结果验证了基础模型在低可预测性(噪声)环境和高季节性机制中更具鲁棒性,而深度学习模型在趋势驱动、低季节性场景中占据主导地位。
- 鲁棒性与泛化能力:跨指标和跨基准的比较证实,无论误差指标(MAE 与 MSE)或特定数据集来源如何,模型排名都是一致的。这验证了观察到的性能差异反映了模型的内在能力,而非特定评估设置或数据源的伪影。