Command Palette
Search for a command to run...
ViGoR-Bench:视觉生成模型距离零样本视觉推理器还有多远?
ViGoR-Bench:视觉生成模型距离零样本视觉推理器还有多远?
Haonan Han Jiancheng Huang Xiaopeng Sun Junyan He Rui Yang Jie Hu Xiaojiang Peng Lin Ma Xiaoming Wei Xiu Li
摘要
尽管现代 AIGC 模型展现出令人惊叹的视觉保真度,其底层却存在一片“逻辑荒原”:在这些区域,系统难以完成涉及物理规律、因果推断或复杂空间推理的任务。当前的评估体系主要依赖表面化指标或碎片化的基准测试,从而营造出一种忽视生成过程的“性能海市蜃楼”。为应对这一挑战,我们提出了 ViGoR(Vision-Generative Reasoning-centric Benchmark,以视觉生成推理为核心的基准),这是一个旨在破除上述幻象的统一框架。ViGoR 通过四项关键创新脱颖而出:1)实现涵盖“图像到图像”与视频任务的跨模态全场景覆盖;2)采用双轨机制,同步评估中间生成过程与最终结果;3)引入基于证据的自动化评判系统,确保与人类判断的高度对齐;4)提供细粒度的诊断分析,将性能拆解为精细的认知维度。在对 20 余款主流模型进行的实验表明,即便是最先进的系统也存在显著的推理缺陷。这确立了 ViGoR 作为下一代智能视觉模型关键“压力测试”的地位。相关演示已开放访问:https://vincenthancoder.github.io/ViGoR-Bench/
一句话总结
清华大学及其他机构的研究人员推出了 ViGoR,这是一个统一的基准测试框架,通过全面的跨模态覆盖和双轨流程分析来评估视觉生成模型,揭示了当前最先进系统在推理方面的显著缺陷,从而指导未来智能视觉的发展。
主要贡献
- 本文介绍了 ViGoR,这是一个统一的基准框架, bridging 图像到图像和视频任务,在 20 个不同的认知维度上提供全面的跨模态覆盖。
- 实施了一种双轨评估机制,用于评估中间生成过程和最终结果,确保输出不仅符合视觉保真度,还遵循物理定律和因果一致性。
- 提出了一种基于证据的自动化评判系统,以减轻评估者的主观性,在实现与人类专家高度一致的同时,能够对特定的推理失败进行细粒度的诊断分析。
引言
现代 AIGC 模型在视觉保真度方面取得了令人印象深刻的成就,但在需要物理、因果或复杂空间推理的任务中往往表现不佳。这种缺陷被 CLIP-Score 和 FID 等传统指标所掩盖,因为这些指标优先考虑统计相似性而非结构完整性。现有的基准测试在图像到图像或视频生成等特定模态上仍然碎片化,且通常仅评估最终输出而忽略生成过程,从而制造出掩盖逻辑漏洞的“性能幻象”。为了解决这些挑战,作者推出了 ViGoR-Bench,这是一个统一的框架,它 bridging 跨模态任务,并采用双轨机制来评估中间推理步骤和最终结果。该方法利用基于证据的自动化评判系统,确保与人类专家的高度一致性,并提供细粒度的诊断分析,以 pinpoint 最先进系统中的特定认知失败。
数据集
-
数据集构成与来源 作者构建了 ViGoR-Bench,这是一个多样化的基准测试,旨在评估三个主要领域的推理能力:物理推理、知识推理和符号推理。该数据集涵盖 20 个不同的子领域,并整合了三种不同的构建范式:利用大语言模型(LLM)和图像生成模型进行的生成式合成、通过权威网络策展和人工摄影进行的现实世界采集,以及利用基于规则的引擎进行的算法构建。
-
各子集的关键细节
- 物理推理: 该子集涵盖排序、空间推理和物体组装等任务。由于获取现实世界具身数据的复杂性,作者采用了一条生成式流水线,利用 LLM 丰富文本描述以提示如 NanoBanana-Pro 等最先进的图像生成器。这些子集缺乏真实图像(ground-truth images);相反,它们提供经过人工验证的文本真实答案,以确保逻辑一致性。
- 知识推理: 专注于生物学、物理学和历史等学科,这些数据来自权威教育网站和科学存储库。虽然部分样本保留了原始的真实图像(例如“前后”现象),但其他样本仅依赖经过人工验证的文本答案。
- 符号推理: 该领域需要精确的逻辑操作。对于华容道(Klotski)和积木搭建等物理谜题,数据是在物理环境中收集的,标注人员将解决状态作为真实图像。对于数独、迷宫导航和函数绘图等抽象任务,作者使用基于规则的算法生成输入和具有数学严谨性的真实图像。代数计算任务涉及通过 LLM 生成方程,并使用符号求解器验证解决方案,然后将其渲染为图像。
-
数据使用与处理 该基准测试不用于模型训练,而是作为综合评估套件。作者利用严格的后处理验证阶段,包括用于语义一致性的人工循环审查和用于数学精度的符号求解器验证。与之前的基准测试不同,ViGoR-Bench 在适用情况下同时提供引用的真实图像和经过人工验证的真实标题,以确保客观性。
-
元数据与评估结构 数据集结构将输入组织为特定序列:初始输入图像、代表模型逐步推理或动作执行的一系列中间帧,以及可选的最终真实参考图像。评估框架区分思维链(CoT)任务和二元任务,前者评估模型输出的完整时间序列,后者评估最终输出图像。评估维度包括背景一致性、规则遵守、有益行动和视觉质量,分数基于视觉观察并与真实描述进行比较,计算为整数或二元值。
方法
作者提出了一个评估视觉推理能力的综合框架,核心在于构建 ViGoR-Bench 和严格的评估流程。整体架构如框架图所示,概述了数据收集和评估过程。
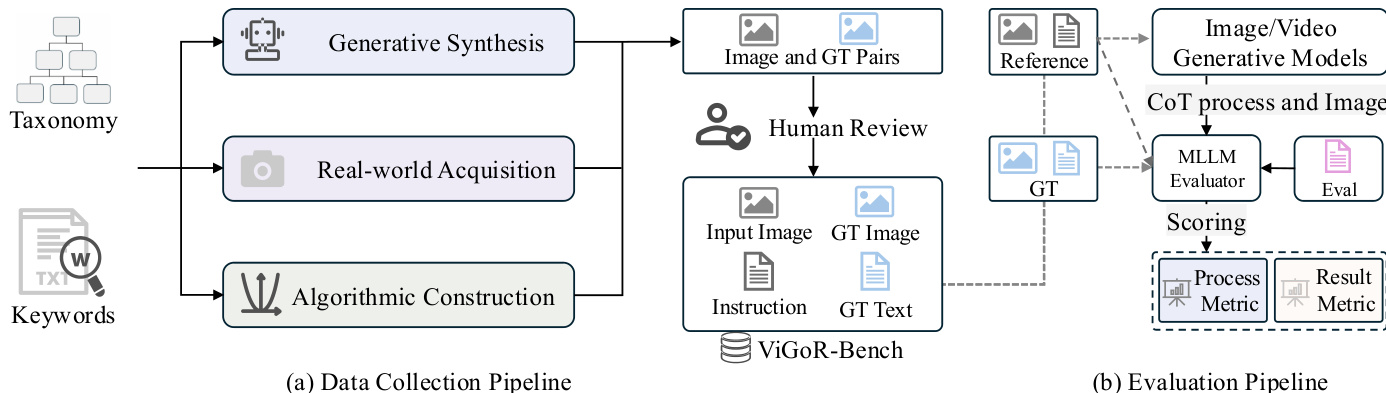
为了确保多样性和质量,基准测试通过三个主要渠道构建:生成式合成、现实世界采集和算法构建。这些来源输入到一个生成图像和真实值(GT)对的过程中。这些对经过人工审查以确保准确性,随后被整合为 ViGoR-Bench 数据集,其中包括输入图像、指令、真实图像和真实文本。评估流程利用图像/视频生成模型根据基准指令生成输出。随后,这些输出由多模态大语言模型(MLLM)评估器进行评估,该评估器将模型的输出与真实值和原始指令进行比较,以生成过程指标和结果指标。
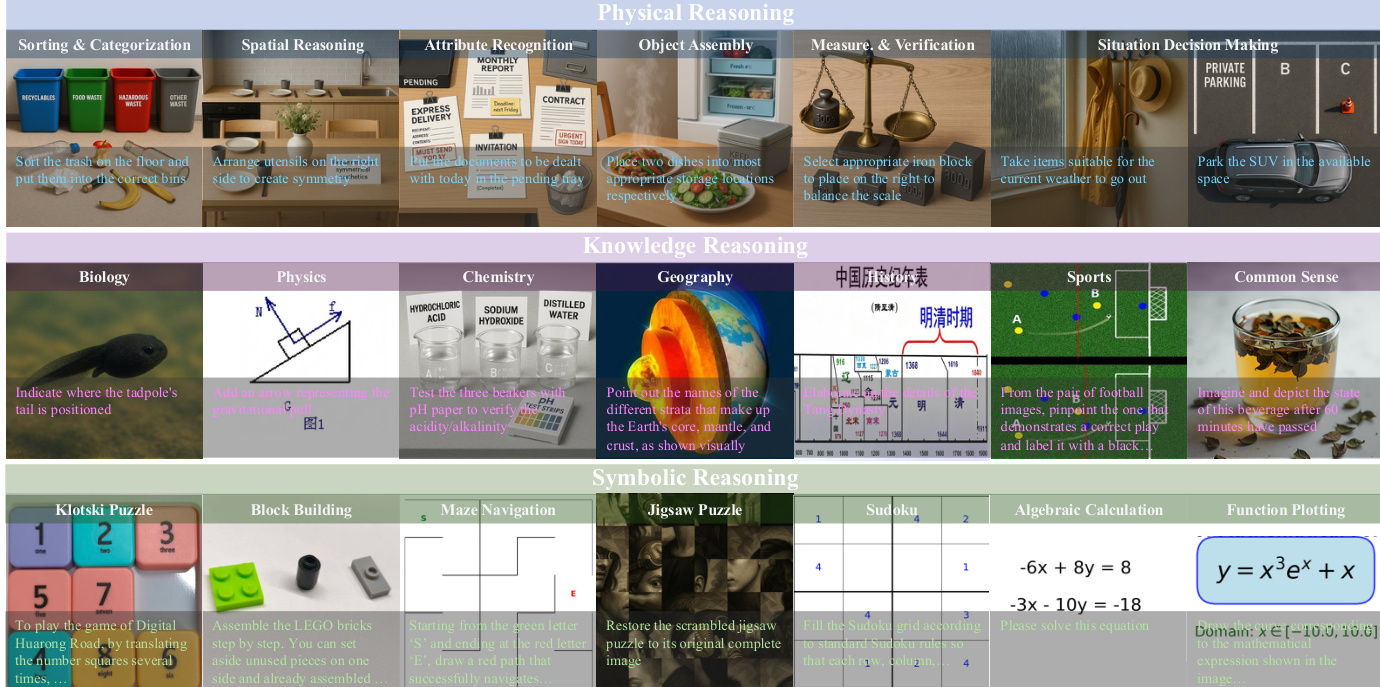
该基准测试将视觉推理任务分为三个主要领域:物理推理、知识推理和符号推理。如分类概览图所示,物理推理涉及物体组装和空间排列等任务。知识推理涵盖生物学、物理学和地理学等领域。符号推理包括数独、迷宫导航和函数绘图等挑战。

具体的任务实例在任务示例网格中可视化,展示了如分类可回收物、求解代数方程和导航迷宫等多样化的挑战。
为了标准化评估,作者采用了针对不同类型推理定制的特定二元模板。对于知识推理任务,评估侧重于四个二元维度:背景一致性、规则遵守、推理准确性和视觉质量。该模板要求评估器输出严格的 JSON 格式,详细说明每个维度的分数和解释。

同样,对于物理推理任务,使用专用模板来评估模型执行具身动作和物理操作的能力。该模板评估模型是否保持环境完整性、遵循特定规则(例如排序标准)并达到正确的最终状态,同时保持高视觉质量。

实验
- 建立了一种双轨评估协议,以评估物理、知识和符号推理领域中中间推理步骤的逻辑连贯性以及最终解决方案的有效性。
- 可靠性分析证实,VLM-as-a-Judge 流程与人类专家高度一致,表明提供真实值参考对于稳定自动化判断至关重要。
- 主要实验显示,专有模型显著优于开源模型,只有顶级模型能够在没有幻觉的情况下处理复杂的物理和符号推理任务。
- 定性发现表明,虽然显式的思维链(Chain-of-Thought)提示提高了过程的可解释性,但由于误差累积和执行限制,并不能保证更高的最终准确率。
- 研究发现,视频生成模型表现出“推理幻觉”,即保持高视觉质量和时间一致性,但无法满足任务完成所需的严格逻辑约束。
- 后训练实验表明,与监督微调(SFT)相比,在高复杂度数据上进行强化学习(RL)能产生更优越的泛化能力和推理成功率,使模型能够超越最先进的专有基线。
- 能力画像突显了一个持续的差距:模型在保持高视觉质量的同时,在多步符号和具身任务中难以遵守规则和保证推理准确性。